The Samsung Exynos M3 - 6-wide Decode With 50%+ IPC Increase
by Andrei Frumusanu on January 23, 2018 1:30 PM EST- Posted in
- Mobile
- CPUs
- Samsung
- Smartphones
- Exynos 9810
- Exynos M3

The Exynos 9810 was one of the first big announcements for 2018 and it was quite an exciting one. Samsung’s claims of doubling single-threaded performance was definitely an eye-catching moment and got a lot of attention. The new SoC sports four of Samsung’s third-generation Exynos M3 custom architecture cores running at up to 2.9GHz, alongside four Cortex A55 cores at 1.9GHz.
Usually Samsung LSI’s advertised target frequency for the CPUs doesn’t necessarily mean that the mobile division will release devices with the CPU running at those frequencies. The Exynos 8890 was advertised by SLSI to run up to 2.7GHz, while the S7 limited it to 2.6GHz. The Exynos M2’s DVFS tables showed that the CPU could go up to 2.8GHz but was rather released with a lower and more power efficient 2.3GHz clock. Similarly, it’s very possible we might see more limited clocks on an eventual Galaxy S9 with the Exynos 9810.
Of course even accounting for the fact that part of Samsung’s performance increase claim for the Exynos 9810 comes from the clockspeed jump from 2.3GHz to 2.9GHz, that still leave a massive performance discrepancy towards the goal of doubling single-threaded performance. Thus, this performance delta must come from the microarchitectural changes. Indeed the effective IPC increase must be in the 55-60% range for the math to make sense.
With the public announcement of the Exynos 9810 having finally taken place, Samsung engineers are now free to release information on the new M3 CPU microarchitecture. One source of information that’s been invaluable over the years into digging into the deeper working of CPU µarch’s are the companies' own submissions to open-source projects such as the GCC and LLVM compilers. Luckily Samsung is a fantastic open-source contributor and has yesterday posted the first patches describing the machine model for the M3 microarchitecture.
To better visualise the difference between the previous microarchitectures and the new M3, we take a step back in time to have a look what the high-level pipeline configuration of the Exynos M1/M2:
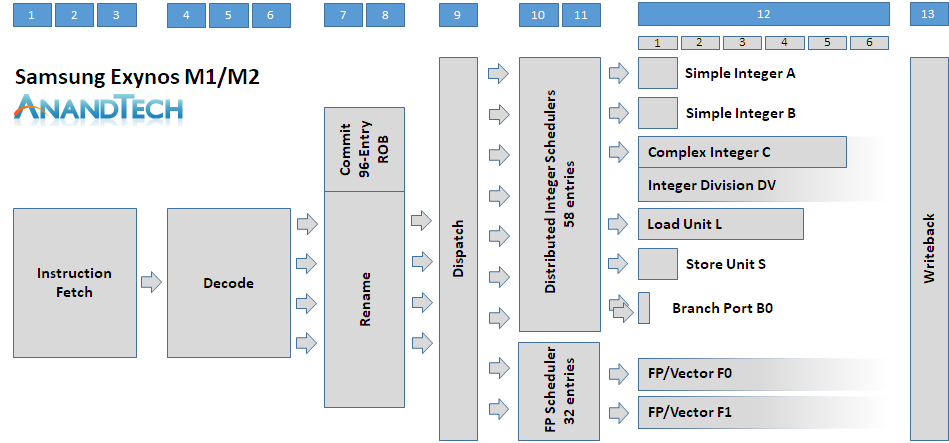
At heart the Exynos M1 and M2 microarchitectures are based on a 4-wide in-order stage for decode and dispatch. The wide decode stage was rather unusual at the time as ARM’s own Cortex A72 and A73 architectures made due with respectively 3 and 2-wide instruction decoders. With the Exynos M1/M2 being Samsung LSI’s first in-house microarchitecture it’s possible that the front-end wasn’t as advanced as ARM’s, as the latter’s 2-wide A73 microarchitecture was more than able to keep up in terms of IPC against the 4-wide M1 & M2. Samsung’s back-end for the M1 and M2 included 9 execution ports:
- Two simple ALU pipelines capable of integer additions.
- A complex ALU handling simple operations as well as integer multiplication and division.
- A load unit port
- A store unit port
- Two branch prediction ports
- Two floating point and vector operations ports leading to two mixed capability pipelines
The M1/M2 were effectively 9-wide dispatch and execution machines. In comparison the A73 dispatches up to 8 micro-ops into 7 pipelines and the A75 dispatches up to 11 µops into 8 pipelines, keeping in mind that we’re talking about very different microarchitectures here and the execution capabilities between the pipelines differ greatly. From fetch to write-back, the M1/M2 had a pipeline depth of 13 stages which is 2 stages longer than that of the A73 and A75, resulting is worse branch-misprediction penalties.
This is only a rough overview of the M1/M2 cores, Samsung published a far more in depth microarchitectural overview at HotChips 2016 which we’ve covered here.
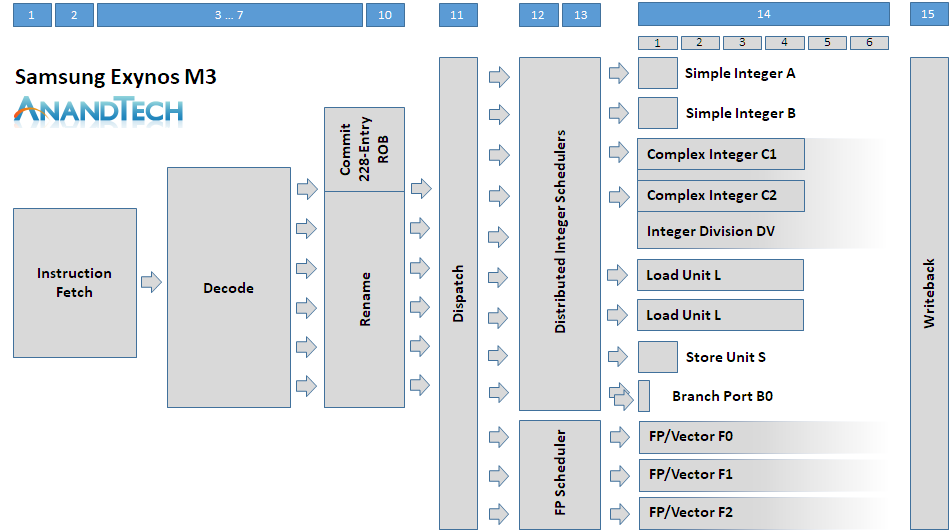
The Exynos M3 differs greatly from the M1/M2 as it completely overhauls the front-end and also widens the back-end. The M3 front-end fetch, decode, and rename stages now increases in width by 50% to accommodate a 6-wide decoder, making the new microarchitecture among one of the widest in the mobile space alongside Apple’s CPU cores.
This comes at a cost however, as some undisclosed stages in the front-end become longer by 2 cycles, increasing the minimum pipeline depth from fetch to writeback from 13 to 15 stages. To counteract this, Samsung must have improved the branch predictor, however we can’t confirm for sure what individual front-end stage improvements have been made. The reorder buffer on the rename stage has seen a massive increase from 96 entries to 228 entries, pointing out that Samsung is trying to vastly increase their ability to extract instruction level parallelism to feed their back-end execution units.
The depiction of the schedulers are my own best guess on how the M3 looks like, as it seemed to me like the natural progression from the M1 configuration. What we do know is that the core dispatches up to 12 µops into the schedulers and we have 12 execution ports:
- Two simple ALU pipelines for integer additions, same as on the M1/M2.
- Two complex ALUs handling simple integer additions and also multiplication and division. The doubling of the complex pipelines means that the M3 has now double the integer multiplication throughput compared to the M1/M2 and a 25% increase in simple integer arithmetic.
- Two load units. Again, the M3 here doubles the load capabilities compared to the M1 and M2.
- A store unit port, same as on the M1/M2.
- Two branch prediction ports, likely the same setup as on the M1/M2, capable of feeding the two branches/cycle the branch prediction unit is able to complete.
- Instead of 2 floating point and vector pipelines, the M3 now includes 3 of them, all of them capable of complex operations, theoretically vastly increasing FP throughput.
The simple ALU pipelines already operate at single-cycle latencies so naturally there’s not much room for improvement there. On the side of the complex pipelines we still see 4-cycle multiplications for 64-bit integers, however integer division has been greatly improved from 21 cycles down to 12 cycles. I’m not sure if the division unit reserves both complex pipelines or only one of them, but what is clear as mentioned before, integer multiplication execution throughput is doubled and the additional complex pipe also increases simple arithmetic throughput from 3 to 4 ADDs.
The load units have been doubled and their load latency remains 4 cycles for basic operations. The Store unit also doesn’t seem to change in terms of its 1-cycle latency for basic stores.
The floating point and vector pipelines have seen the most changes in the Exynos M3. There are 3 pipelines now with distributed capabilities between them. Simple FP arithmetic operations and multiplication see a three-fold increase in throughput as all pipelines now offer the capability, compared to only one for the Exynos M1/M2. Beyond tripling the throughput, the latency of FP additions and subtractions (FADD, FSUB) is reduced from 3 cycles down to 2 cycles. Multiplication stays at a 4-cycle latency.
Floating point division sees a doubling of the throughput as two of the three pipelines are now capable of the operations, and latency has also been reduced from 15 cycles down to 12 cycles. Cryptographic throughput of AES instruction doubles as well as two of the 3 pipelines are able to execute them. SHA instruction throughput remains the same. For simple vector operations we see a 50% increase in throughput due to the additional pipeline.

We’re only scratching the surface of what Samsung’s third-generation CPU microarchitecture is bringing to the table, but already one thing is clear: SLSI’s claim of doubling single-threaded performance does not seem farfetched at all. What I’ve covered here are only the high-level changes the in the pipeline configurations and we don’t know much at all about the improvements on the side of the memory subsystem. I’m still pretty sure that we’ll be looking at large increases in the cache sizes up to 512KB private L2’s for the cores with a large 4MB DSU L3. Given the floating point pipeline changes I’m also expecting massive gains for such workloads. The front-end of the M3 microarchitecture is still a mystery so here’s hoping that Samsung will be able to re-attend Hot Chips this year for a worthy follow-up presentation covering the new design.
With all of these performance improvements, it’s also expected that the power requirements of the core will be greatly beyond those of existing cores. This seems a natural explanation for the two-fold single-core performance increase while the multi-core improvement remains at 40% - running all cores of such a core design at full frequency would indeed showcase some very high TDP numbers.
If all these projections come to fruition, I have no idea how Samsung’s mobile division is planning to equalise the CPU performance between the Exynos 9810 and against an eventual Snapdragon 845 variant of the Galaxy S9, short of finding ourselves in a best-case scenario for ARM’s A75 vs a worst-case for the new Exynos M3. With 2 months to go, we’ll have to wait & see what both Samsung mobile and Samsung LSI have managed to cook up.








60 Comments
View All Comments
N Zaljov - Wednesday, January 24, 2018 - link
The S6 was equipped with the Exynos 7420, which was only an AP, which means that it didn't have an integrated baseband processor. In Europe, the 7420 was combined with an external Shannon 333 baseband, whereas the NA version (and I also think the Chinese...) was equipped with an external Qualcomm MDM9635 BB.Since the 889x-series has it's own fully integrated BB processor, it doesn't make a whole lot of sense to combine it with an external BB processor, when Samsung can just use an SoC that has all the demanded functionality on board while delivering equal performance figures. But we'll see how that changes with the 9810, which I believe will be the turning point for SLSI (look at the recently announced Meizu phone, which has an Exynos with " CDMA support a couple of days ago...).
N Zaljov - Wednesday, January 24, 2018 - link
*its own fully integratedThe eternal need of an edit button is real. |-D
StormyParis - Tuesday, January 23, 2018 - link
Very interesting read, thank you. Now for the benchmarks ;-piwod - Wednesday, January 24, 2018 - link
This is one reason I believe Apple will never Fab with Samsung again. Hence I dont understand why the Analyst and Internet keep bumping out fake news.How far is M3 from Apple's A11 in Single Thread Performance? I mean projected numbers.
Does it mean Samsung could possibly have Windows 10 laptop running ARM using its own chip?
id4andrei - Wednesday, January 24, 2018 - link
As long as Exynos(and Snapdragon for that matter) are smaller in die size for the same process node they will never reach Apple's single-threaded performance. That's not a bad thing because:1. Smartphones are powerful enough for average daily usage.
2. Apple's performance is not sustainable as we've seen from the throttling fiasco.
onfire23 - Wednesday, January 24, 2018 - link
Is this Andrei frumasanu the same guy known as andreilux in the xda. Fantastic kernel dev, made my s3 very usablearsjum - Thursday, January 25, 2018 - link
Yes, he is.lmcd - Wednesday, January 24, 2018 - link
ARM A75 is supposed to be knocked down a peg with its inevitable Meltdown patch, no?Wardrive86 - Wednesday, January 24, 2018 - link
This is a honest to goodness big fat core! Will it out perform A75? I'm not so sure, it seems to be bigger than A75, in many of the same proportions that Mongoose 2 was to A73/Kryo 280. As we've recently seen they performed roughly the same only with substantial differences in power consumption and efficiency. Granted Mongoose 3 has alot of execution units, and a 228 entry RoB, the branch predictor accuracy must be insane!ricky89 - Sunday, April 15, 2018 - link
When will we see this super powerful processor on a smartphone?