Intel's Pentium 4 E: Prescott Arrives with Luggage
by Anand Lal Shimpi & Derek Wilson on February 1, 2004 3:06 PM EST- Posted in
- CPUs
Larger, Slower Cache
On the surface Prescott is nothing more than a 90nm Pentium 4 with twice the cache size, but we’ve hopefully been able to illustrate quite the contrary thus far. Despite all of the finesse Intel has exhibited with improving branch predictors, scheduling algorithms and new execution blocks they did exploit one of the easiest known ways to keep a long pipeline full – increase cache size.
With Prescott Intel debuted their highest density cache ever – each SRAM cell (the building blocks of cache) is now 43% smaller than the cells used in Northwood. What this means is that Intel can pack more cache into an even smaller area than if they had just shrunk the die on Prescott.
While Intel has conventionally increased L2 cache size, L1 cache has normally remained unchanged – armed with Intel’s highest density cache ever, Prescott gets a larger L1 cache as well as a larger L2.
The L1 Data cache has been doubled to a 16KB cache that is now 8-way set associative. Intel states that the access latency to the L1 Data cache is approximately the same as Northwood’s 8KB 4-way set associative cache, but the hit rate (probability of finding the data you’re looking for in cache) has gone up tremendously. The increase in hit rate is not only due to the increase in cache size, but also the increase in associativity.
Intel would not reveal (even after much pestering) the L1 cache access latency, so we were forced to use two utilities - Cachemem and ScienceMark to help determine if there was any appreciable increase in access latency to data in the L1.
| Cachemem L1 Latency | ScienceMark L1 Latency | |
|---|---|---|
Northwood |
1 cycle |
2 cycles |
Prescott |
4 cycles |
4 cycles |
Although Cachemem and ScienceMark don't produce identical results, they both agree on one thing: Prescott's L1 cache latency is increased by more than an insignificant amount. We will just have to wait for Intel to reveal the actual access latencies for L1 in order to confirm our findings here.
Although the size of Prescott’s Trace Cache remains unchanged, the Trace Cache in Prescott has been changed for the better thanks to some additional die budget the designers had.
The role of the Trace Cache is similar to that of a L1 Instruction cache: as instructions are sent down the pipeline, they are cached in the Trace Cache while data they are operating on is cached in the L1 Data cache. A Trace Cache is superior to a conventional instruction cache in that it caches data further down in the pipeline, so if there is a mispredicted branch or another issue that causes execution to start over again you don’t have to start back at Stage 1 of the pipeline – rather Stage 7 for example.
The Trace Cache accomplishes this by not caching instructions as they are sent to the CPU, but the decoded micro operations (µops) that result after sending them through the P4’s decoders. The point of decoding instructions into µops is to reduce their complexity, once again an attempt to reduce the amount of work that has to be done at any given time to boost clock speeds (AMD does this too). By caching instructions after they’ve already been decoded, any pipeline restarts will pick up after the instructions have already made it through the decoding stages, which will save countless clock cycles in the long run. Although Prescott has an incredibly long pipeline, every stage you can shave off during execution, whether through Branch Prediction or use of the Trace Cache, helps.
The problem with a Trace Cache is that it is very expensive to implement; achieving a hit rate similar to that of an instruction cache requires significantly more die area. The original Pentium 4 and even today’s Prescott can only cache approximately 12K µops (with a hit rate equivalent to an 8 – 16KB instruction cache). AMD has a significant advantage over Intel in this regard as they have had a massive 64KB instruction cache ever since Athlon. Today’s compilers that are P4 optimized are aware of the very small Trace Cache so they produce code that works around it as best as possible, but it’s still a limitation.
Another limitation of the Trace Cache is that because space is limited, not all µops can be encoded within it. For example, complicated instructions that would take a significant amount of space to encode within the Trace Cache are instead left to be sequenced from slower ROM that is located on the chip. Encoding logic for more complicated instructions can occupy precious die space that is already limited because of the complexity of the Trace Cache itself. With Prescott, Intel has allowed the Trace Cache to encode a few more types of µops inside the Trace Cache – instead of forcing the processor to sequence them from microcode ROM (a much slower process).
If you recall back to the branch predictor section of this review we talked about Prescott’s indirect branch predictor – to go hand in hand with that improvement, µops that involve indirect calls can now be encoded in the Trace Cache. The Pentium 4 also has a software prefetch instruction that developers can use to instruct the processor to pull data into its cache before it appears in the normal execution. This prefetch instruction can now be encoded in the Trace Cache as well. Both of these Trace Cache enhancements are designed to reduce latencies as much as possible, once again, something that is necessary because of the incredible pipeline length of Prescott.
Finally we have Prescott’s L2 cache: a full 1MB cache. Prescott’s L2 cache has caught up with the Athlon 64 FX, which it needs as it has no on-die memory controller and thus needs larger caches to hide memory latencies as much as possible. Unfortunately, the larger cache comes at the sacrifice of access latency – it now takes longer to get to the data in Prescott’s cache than it did on Northwood.
| Cachemem L2 Latency | ScienceMark L2 Latency | |
|---|---|---|
Northwood |
16 cycles |
16 cycles |
Prescott |
23 cycles |
23 cycles |
Both Cachemem and ScienceMark agree on Prescott having a ~23 cycle L2 cache - a 44% increase in access latency over Northwood. The only way for Prescott's slower L2 cache to overcome this increase in latency is by running at higher clock speeds than Northwood.
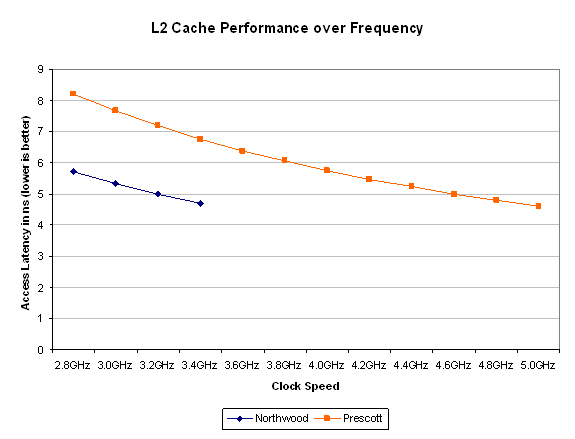
If our cache latency figures are correct, it will take a 4GHz Prescott to have a faster L2 cache than a 2.8GHz Northwood. It will take a 5GHz Prescott to match the latency of a 3.4GHz Northwood. Hopefully by then the added L2 cache size will be more useful as programs get larger, so we'd estimate that the Prescott's cache would begin to show an advantage around 4GHz.
Intel hasn’t changed any of the caching algorithms or the associativity of the L2 cache, so there are no tricks to reduce latency here – Prescott just has to pay the penalty.
For today’s applications, this increase in latency almost single handedly eats away any performance benefits that would be seen by the doubling of Prescott’s cache size. In the long run, as applications and the data they work on gets larger the cache size will begin to overshadow the increase in latency, but for now the L2 latency will do a good job of keeping Northwood faster than Prescott.








104 Comments
View All Comments
sprockkets - Monday, February 2, 2004 - link
Hmmm... on Intel's website on the new processor news: "Thermal Monitoring: Allows motherboards to be cost-effectively designed to expected application power usages rather than theoretical maximums."Not sure what it means. I'm thinking clock throttling so that if your particular chip is hotter than it should be it will run on under engineered motherboards/coolers.
This chip dissipates around the same heat as Northwoods clock for clock! And of course, Intel style is wait 6-12, then the new stuff will actually be good. Still, is it really that important to increase performance so much that heat becomes an issue? I.E., will Dell be able to make the cooling whisper quiet? They can with the processor sitting at 80-90c, but now that with normal cooling it's almost there, now what will they do? Why can't we just have new processors that run so cool that we can just use heatsinks without fans? Oh well.
Novaoblivion - Monday, February 2, 2004 - link
Great article :) I found it very interesting I dont think I'll be buying a prescott till they hit about 4Ghz. My 2.4C is nice and fast for now.CRAMITPAL - Monday, February 2, 2004 - link
http://www.theinquirer.net/?article=13927
http://www.theinquirer.net/?article=13947
johnsonx - Monday, February 2, 2004 - link
To Vanners, #38:"if you halve the time for a stage in the pipeline and double the number of stages. Yes this means you can run at 2GHz instead of 1GHz but the reality is you're still taking 5ns to complete the pipe."
Yes and no... In the example, you're right that a single instruction takes the same 5ns to complete. But you're not just executing a single instruction... rather, thousands to millions! The 10 stage pipe has twice as many instructions in flight as the 5 stage pipe. Therefore in the example, you get one result out of the 5-stage/1Ghz cpu every 1ns, but TWO results out of the 10-stage/2Ghz cpu in the same 1ns... twice as many.
What I find interesting is that as pipelines get longer and longer, we might have to start talking about Instruction Latency: the number of clocks and ns between the time an instruction goes in and when the result comes out. It'll never be anything a human could notice directly, but it might come into play in high-performance realtime apps that deal with input from the outside world, and have to produce synchronized output. Any CPU calculates somewhat "back-in-time" as instructions fly down the pipe... right now, a Prescott calculates about twice as far behind 'reality' as an A64 does. I don't know if there is any realworld application where this really could make a difference, or if there ever will be, but it's interesting to ponder, particularly if the pipeline lengths of Intel vs. AMD continue to diverge.
cliffa3 - Monday, February 2, 2004 - link
i don't see how a 4+GHz prescott will match up with intel's new pico BTX form factor...with that much heat (using air cooling), you need to keep a safe zone around the proc unless you like your RAM DDR+BBQ.I'd have to say that a lot of enthusiasts are younger and live in limited space conditions...might work well for people up north who don't want to run the heater, but as for me in texas, i have all the cool air pumping in to my bedroom and it still takes a lot to keep it cool. Can you imagine a university or corporation having a room full of those?..if they think about that, then it's no bueno for DELL and others as well.
I'd also have to agree with the others about the heat/power being a major part of the article that was left out...otherwise a tremendous read, thanks for all the effort that goes into these.
tfranzese - Monday, February 2, 2004 - link
But - I need to add - the correction was needed and is welcome. Not trying to pick a bone with the editors.tfranzese - Monday, February 2, 2004 - link
#55, you read what I read. I'll vouch for you.Icewind - Monday, February 2, 2004 - link
#55Better go back to sleep me thinks :)
Spearhawk - Monday, February 2, 2004 - link
Is it just me (who was extremely tired yesterday) or has the 101 on pipeline part changed since the article was put up?I seem to rememeber reading someting about how a 5 staged CPU at 1 Ghz should be exactly as fast as a 2 GHz CPU with 10 stages (all else being equal of course) and that the secret of geting any profit out of going to more stages was to make sure that it couldn't only scale to 2 Ghz but to 3 Ghz or more.
Icewind - Monday, February 2, 2004 - link
I think shuttle owners are SOL with prescott.