Intel's Pentium 4 E: Prescott Arrives with Luggage
by Anand Lal Shimpi & Derek Wilson on February 1, 2004 3:06 PM EST- Posted in
- CPUs
Larger, Slower Cache
On the surface Prescott is nothing more than a 90nm Pentium 4 with twice the cache size, but we’ve hopefully been able to illustrate quite the contrary thus far. Despite all of the finesse Intel has exhibited with improving branch predictors, scheduling algorithms and new execution blocks they did exploit one of the easiest known ways to keep a long pipeline full – increase cache size.
With Prescott Intel debuted their highest density cache ever – each SRAM cell (the building blocks of cache) is now 43% smaller than the cells used in Northwood. What this means is that Intel can pack more cache into an even smaller area than if they had just shrunk the die on Prescott.
While Intel has conventionally increased L2 cache size, L1 cache has normally remained unchanged – armed with Intel’s highest density cache ever, Prescott gets a larger L1 cache as well as a larger L2.
The L1 Data cache has been doubled to a 16KB cache that is now 8-way set associative. Intel states that the access latency to the L1 Data cache is approximately the same as Northwood’s 8KB 4-way set associative cache, but the hit rate (probability of finding the data you’re looking for in cache) has gone up tremendously. The increase in hit rate is not only due to the increase in cache size, but also the increase in associativity.
Intel would not reveal (even after much pestering) the L1 cache access latency, so we were forced to use two utilities - Cachemem and ScienceMark to help determine if there was any appreciable increase in access latency to data in the L1.
| Cachemem L1 Latency | ScienceMark L1 Latency | |
|---|---|---|
Northwood |
1 cycle |
2 cycles |
Prescott |
4 cycles |
4 cycles |
Although Cachemem and ScienceMark don't produce identical results, they both agree on one thing: Prescott's L1 cache latency is increased by more than an insignificant amount. We will just have to wait for Intel to reveal the actual access latencies for L1 in order to confirm our findings here.
Although the size of Prescott’s Trace Cache remains unchanged, the Trace Cache in Prescott has been changed for the better thanks to some additional die budget the designers had.
The role of the Trace Cache is similar to that of a L1 Instruction cache: as instructions are sent down the pipeline, they are cached in the Trace Cache while data they are operating on is cached in the L1 Data cache. A Trace Cache is superior to a conventional instruction cache in that it caches data further down in the pipeline, so if there is a mispredicted branch or another issue that causes execution to start over again you don’t have to start back at Stage 1 of the pipeline – rather Stage 7 for example.
The Trace Cache accomplishes this by not caching instructions as they are sent to the CPU, but the decoded micro operations (µops) that result after sending them through the P4’s decoders. The point of decoding instructions into µops is to reduce their complexity, once again an attempt to reduce the amount of work that has to be done at any given time to boost clock speeds (AMD does this too). By caching instructions after they’ve already been decoded, any pipeline restarts will pick up after the instructions have already made it through the decoding stages, which will save countless clock cycles in the long run. Although Prescott has an incredibly long pipeline, every stage you can shave off during execution, whether through Branch Prediction or use of the Trace Cache, helps.
The problem with a Trace Cache is that it is very expensive to implement; achieving a hit rate similar to that of an instruction cache requires significantly more die area. The original Pentium 4 and even today’s Prescott can only cache approximately 12K µops (with a hit rate equivalent to an 8 – 16KB instruction cache). AMD has a significant advantage over Intel in this regard as they have had a massive 64KB instruction cache ever since Athlon. Today’s compilers that are P4 optimized are aware of the very small Trace Cache so they produce code that works around it as best as possible, but it’s still a limitation.
Another limitation of the Trace Cache is that because space is limited, not all µops can be encoded within it. For example, complicated instructions that would take a significant amount of space to encode within the Trace Cache are instead left to be sequenced from slower ROM that is located on the chip. Encoding logic for more complicated instructions can occupy precious die space that is already limited because of the complexity of the Trace Cache itself. With Prescott, Intel has allowed the Trace Cache to encode a few more types of µops inside the Trace Cache – instead of forcing the processor to sequence them from microcode ROM (a much slower process).
If you recall back to the branch predictor section of this review we talked about Prescott’s indirect branch predictor – to go hand in hand with that improvement, µops that involve indirect calls can now be encoded in the Trace Cache. The Pentium 4 also has a software prefetch instruction that developers can use to instruct the processor to pull data into its cache before it appears in the normal execution. This prefetch instruction can now be encoded in the Trace Cache as well. Both of these Trace Cache enhancements are designed to reduce latencies as much as possible, once again, something that is necessary because of the incredible pipeline length of Prescott.
Finally we have Prescott’s L2 cache: a full 1MB cache. Prescott’s L2 cache has caught up with the Athlon 64 FX, which it needs as it has no on-die memory controller and thus needs larger caches to hide memory latencies as much as possible. Unfortunately, the larger cache comes at the sacrifice of access latency – it now takes longer to get to the data in Prescott’s cache than it did on Northwood.
| Cachemem L2 Latency | ScienceMark L2 Latency | |
|---|---|---|
Northwood |
16 cycles |
16 cycles |
Prescott |
23 cycles |
23 cycles |
Both Cachemem and ScienceMark agree on Prescott having a ~23 cycle L2 cache - a 44% increase in access latency over Northwood. The only way for Prescott's slower L2 cache to overcome this increase in latency is by running at higher clock speeds than Northwood.
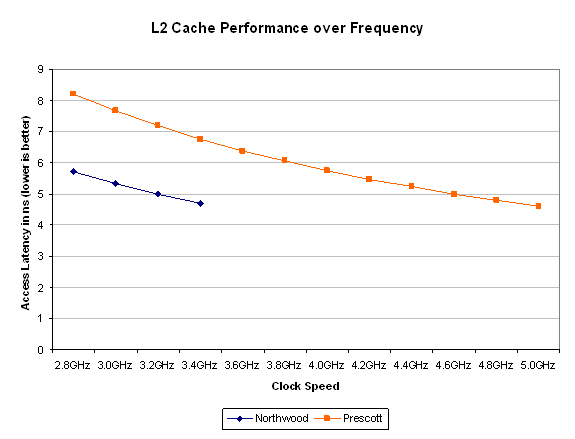
If our cache latency figures are correct, it will take a 4GHz Prescott to have a faster L2 cache than a 2.8GHz Northwood. It will take a 5GHz Prescott to match the latency of a 3.4GHz Northwood. Hopefully by then the added L2 cache size will be more useful as programs get larger, so we'd estimate that the Prescott's cache would begin to show an advantage around 4GHz.
Intel hasn’t changed any of the caching algorithms or the associativity of the L2 cache, so there are no tricks to reduce latency here – Prescott just has to pay the penalty.
For today’s applications, this increase in latency almost single handedly eats away any performance benefits that would be seen by the doubling of Prescott’s cache size. In the long run, as applications and the data they work on gets larger the cache size will begin to overshadow the increase in latency, but for now the L2 latency will do a good job of keeping Northwood faster than Prescott.








104 Comments
View All Comments
TrogdorJW - Tuesday, February 3, 2004 - link
Technically, it depends on how you cound pipelines. The P4 has several "simple" pipelines that deal with the easy instructions, and then "complex" pipelines that deal with the more difficult instructions.For example, they have two Integer units running at twice the core clock speed, but those only do simple integer instructions. Then they have a complex Integer unit running at core speed that can do the remaining integer instructions. So that's 3 INT units, technically, and two of those are double-pumped, so you could even call it five INT units if you want to be generous.
The FP/SSE is somewhat similar, I believe. The end result is that it's not an apples-to-apples comparison between Intel and AMD pipelines. You could really say both of them have nine different execution units (pipelines), but Intel's pipelines aren't as powerful as AMD's when compared directly. See: http://www.tomshardware.com/cpu/20040201/prescott-... - there is an image of the pipelines in the Prescott, which is mostly unchanged from the Northwood.
The thing with the number of stages in a pipeline still holds true. So you have 60 million transistors in 7 pipelines, each with 31 stages. (Actually, the FP pipelines probably have more stages.) That still gives you a rough guess of 275000 transistors in each pipeline stage. In the P4, it was 30 million transistors in 20 stages and still 7 pipelines, giving a guess of 215000 transistors per stage.
I'm really, REALLY curious as to what Intel is doing. For some reason, the core of the P4 in the Prescott is at least twice as big (in transistor count) as the core of the Northwood. The L2 cache is also twice as big. So we went from 29+26 million transistors in Northwood (core+L2 cache) to apparently something like 75+50 in the Prescott.
If indeed there are 75 million transistors in the Prescott core, they *had* to increase the length of the pipelines to 30 or so stages to have any chance of running fast. However, you can't argue that the increase in transistors was necessitated by the increase in the number of pipeline stages! Why? Apparently, the Prescott has more transistors per stage, so in theory a Northwood would have actually scaled to *higher* clockspeeds than a Prescott!
Intel is definitely not showing all of their cards on the table right now. I'm betting that they're trying to protect Itanium as long as they can. I guess we'll know sometime in the next year or so.
KristopherKubicki - Tuesday, February 3, 2004 - link
Check out Anand's Blog on x86-64 for Intelhttp://www.anandtech.com/weblog/index.html?bid=46
Kristopher
Pumpkinierre - Tuesday, February 3, 2004 - link
Errata for #87 2nd paragraph: 'According to Ace's'- not Ace's but X-bit:http://www.xbitlabs.com/articles/cpu/display/presc...
Thank you #89 although I didnt think the P4 had as many pipelines as you quote.
INTC - Tuesday, February 3, 2004 - link
http://69.56.255.194/?article=13959Hmmm - wouldn't that be exciting? P4 Prescott 3.2E GHz with XDR Rambus at 3.2 GHz PCI Express and 64-bit extensions at IDF - I wonder when Nventiv will have that in their new Cold Fusion systems?
DerekBaker - Tuesday, February 3, 2004 - link
On the most common way of counting the Athlon has 9 pipelines, the P4 7.Derek
Pumpkinierre - Tuesday, February 3, 2004 - link
Add "So to compensate the slower speed of shorter pipelines, they make them more numerous in a cpu eg 6-8 in Athlons cf. 3 in P4 (I believe)" to the middle of 1st paragraphPumpkinierre - Tuesday, February 3, 2004 - link
#82 There is more than one pipeline in a processor so you have to take that into account in your stage/No. of transistor calculations plus registers, buffers, stacks, MMX, SSE etc.. I also am not totally happy with the AT explanation of pipelines. Pipelines are just a way of guessing the correct answer so that idle cpu time can be put to good use. I thought the stages in a pipeline be it 10 or 20 were of the same complexity. Its just that the outcome of a longer pipeline had a lower probability of being correct due to the increased likelihood of more branch statements being present in a longer pipeline. But work in checking the correct outcome is less in a longer pipeline. Work is heat so smaller pipelines make more heat which lessens speed headroom while longer pipelines can run at higher speed but correct outcomes are less probable. So to compensate they use more pipelines. Paradoxically with Prescott they've increased the pipeline lenght but they have more heat so as far as I am concerned speed headroom is limited and I doubt they will get past 4Gig with the present cpu. The o'clocks so far bear this out, with stable bests at ~3.8GHz. This is as result of some physical problem with the 90 nm process. What they should have done is applied the tweaks to the Northwood 130nm core and they would have been heaps better off. Its doubtful whether the tweaks would have increased temperature but they would be getting 30 to 50% better calculating power from the cpu at the same core speed. Would'nt need to PR rate it, just call it a different name. Then they would have had more time to sort out the 90nm problem while keeping the consumer happy. As it is they are going to cop a lot of flak over this overbaked failure.I'm also not happy about this loss of latency in the caches. Even though i've abused large caches in the past, that was on the grounds of gaming software where i expected alot of cache misses by the cpu because of the unpredictable nature of operator driven gaming. But here they are saying the latency has increased (and tests measure this) no matter the application and the reason given by sites is the doubling in size of the cache. But when the P4 went from 256K L2 to 512k L2 and the A-XP(256K) to Barton(512K) or even A64 3000+(512K) and 3200+(1024K) no major increase in cache latency was reported- in fact often the opposite. According to Ace's the latency of the Prescott 16K data L1 cache is now close to that of the a64 L1 (64K data) 4 times its size and double the latency of the Northwood 9even though Intel says it is the same- but no figures)! Something weird's going on with this 90nm stuff.
PrinceGaz - Tuesday, February 3, 2004 - link
Hmmm... where to begin :)Okay, first of all I must say that was an excellent review overall and the background material covering all the architectural changes was nothing short of superb. I'll definitely re-read chunks of that whenever I need a refresher on various aspects of its design.
Your overclocking results were very good, far better than those achieved by most other sites. However I think it was a bad idea for AnandTech to suggest a Prescott is a great overclocker based on the sample(s) they received from Intel. It would be better to wait until you've got some retail CPUs from other sources before making recommendations about buying it for overclocking as readers may not be so lucky as you were.
Right, onto the tests... overall as I see it the Prescott is really pretty much on a par with the Northwood performance-wise for a given clock-speed. Its faster at some tasks by a small margin thats not significant, and slower at as many others by a similar small margin I wouldn't worry about. As such it won't matter to an average user whether they get a P4 3.4C or a P4 3.4E processor. Therefore everything that has been said comparing the Northwood to the A64 is still valid when comparing the Prescott to the A64 (at least at clock-speeds over 3GHz).
As many others have commented, the omission of any mention at all of the thermal issues was nothing short of staggering. *Every* other major review I read at least said something about it and most of them had quite a lot to say about it. I did notice the occassional error in what they said such as at [H]ard where their Prescott was running at 1.5V which therefore invalidated their temperature readings but even on those sites where it was running at the correct voltage, heat was still an issue.
Its quite possible the current version of the Prescott is a bit like AMD's first 130nm chip the Thoroughbred 'A' which also ran rather hot. Of course this is already supposed to be the third revision of the Prescott so whether they can make any further tweaks that will seriously reduce power requirements is debatable. If they can't then ramping up the speed up to 4GHz and beyond that in 2005 will be a major problem. The most conservative estimate based on current figures would be for a 4GHz chip to have a TDP of 130W though in reality thats likely to be closer to 150W. Even if improved cooling solutions are able to get rid of that much heat from the chip *and* the case, electricity isn't free so the cost of running it must be considered to.
Finally about 64-bit support in the Prescott. It wouldn't surprise me if Prescott does have 64-bit support built into it which is currently disabled in much the same way Hyper-Threading was disabled in some Northwood cores. The only people who know for sure either work for Intel and arent saying, or are under NDA. It would be a blow to IA64 (and also in a way be seen as saying AMD was right) if Intel did suddenly enable x86-64 support so I doubt they'll do so unless the case becomes compelling. Theres no sign of that happening in the immediate future.
KristopherKubicki - Tuesday, February 3, 2004 - link
They put 30M extra transistors on there to confuse people. :(Kristopher
TrogdorJW - Tuesday, February 3, 2004 - link
Actually, Icewind, if they don't *have* to activate the 64-bit capability, then they're okay. I mean, activating 64-bit in x86 is basically the death toll for Itanium and IA-64. That would make some (*all*?) of the companies that have purchased and worked on IA-64 rather pissed, right?If Prescott does have 64-bit, it was just Intel hedging their bets. They would have started design on the new core 2 years ago, around the time when the full specifications of AMD64 were released. Intel couldn't know for sure what the final result of K8 would be, so they may have decided to start early, just in case.
Like I said before, it's pure speculation at this point, but I figure adding 64-bit registers and instructions to x86 could be done with 10 to 15 million transistors "easily". I've basically figured out (as others have, apparently) that there are close to 30 million transistors that aren't accounted for in the Prescott. That's the size of the entire Northwood core (minus cache)! If you have a better idea of where these transistors were used, feel free to share it. :)