HiSilicon Kirin 970 - Android SoC Power & Performance Overview
by Andrei Frumusanu on January 22, 2018 9:15 AM ESTNPU Performance Tested
To test the performance of the NPU we need a benchmark which currently targets all of the various vendor APIs. Unfortunately at this stage short of developing our own implementation the choices are scarce, but luckily there is one: Popular Chinese benchmark suite Master Lu recently introduced an AI benchmark implementing both HiSilicon’s HiAI as well as Qualcomm’s SNPE frameworks. The benchmarks implements three different neural network models: VGG16, InceptionV3 as well as ResNet34. The input dataset are 100 images which are a subset of the ImageNet reference database. As a fall-back the app implements the TensorFlow inferencing library to run on the CPU. I’ve ran the performance figures on the Mate 10 Pro, Mate 9 as well as two Snapdragon 835 (Pixel 2 XL & V30) devices respectively running on the CPU as well as the Hexagon DSP.

Similarly to the SPEC2006 results I chose to use a more complex graph to better showcase the three dimensions of average power (W), efficiency (mJ/inference) as well as absolute performance (fps / inferences per second).
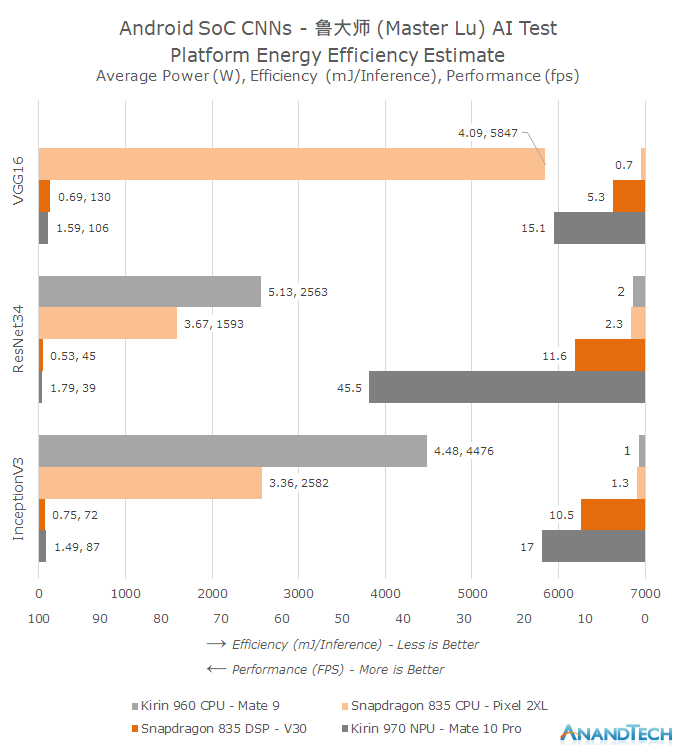
First thing we notice from the graph is that we can observe an order of magnitude difference in performance between the NPU and CPU implementations. Running the networks as they are on the CPUs we’re not able to exceed 1-2fps and we do so at very heavy CPU power consumption. Both the Snapdragon 835 as well as the Kirin 960 CPUs struggle with the workloads with average power exceeding sustainable workloads.
Qualcomm’s Hexagon DSP is able to improve on the CPU performance by a factor of 5-8x. But Huawei’s NPU performance figures are again several factors above that, showcasing up to a 4x lead in ResNet34. The reason for the different performance ratio differences between the different models is their design. Convolutional layers are heavily parallelisable whilst the polling and fully connected layers of the models must use more serial processing steps. ResNet in particular makes use of a larger percentage of convolution processing for a single inference and thus is able to achieve a higher utilization rate of the Kirin NPU.

In terms of power efficiency we’re very near to Huawei’s claims of up to a 50x improvement. This is the key characteristic that will enable CNNs to be used in real-world use-cases. I was quite surprised to see Qualcomm’s DSP reach similar efficiency levels as Huawei’s NPU – albeit at 1/3rd to 1/4th of the performance. This should bode quite well in terms of the Snapdragon 845’s Hexagon 685 which promises up to a 3x increase in performance.
I wanted to take the opportunity to make a rant about Google’s Pixel 2: I was able to actually run the benchmark on the Snapdragon 835’s CPU because the Pixel 2 devices lacked support for the SNPE framework. This was in a sense maybe both expected as well as unexpected. With the introduction of the NN API in Android 8.1, which the Pixel 2 phones support and use acceleration through the dedicated Pixel Visual Core SoC, it’s natural that Google would want to push usage of Android’s standard APIs. But on the other hand this is also a limitation on the capabilities of the phone by the OEM vendor which I can’t help but compare to the decision by Google to by default omit OpelCL in Android. This is a decision which in my eyes has heavily stifled the ecosystem and is why we don’t see more GPU accelerated compute workloads, out of which CNNs could have been one.
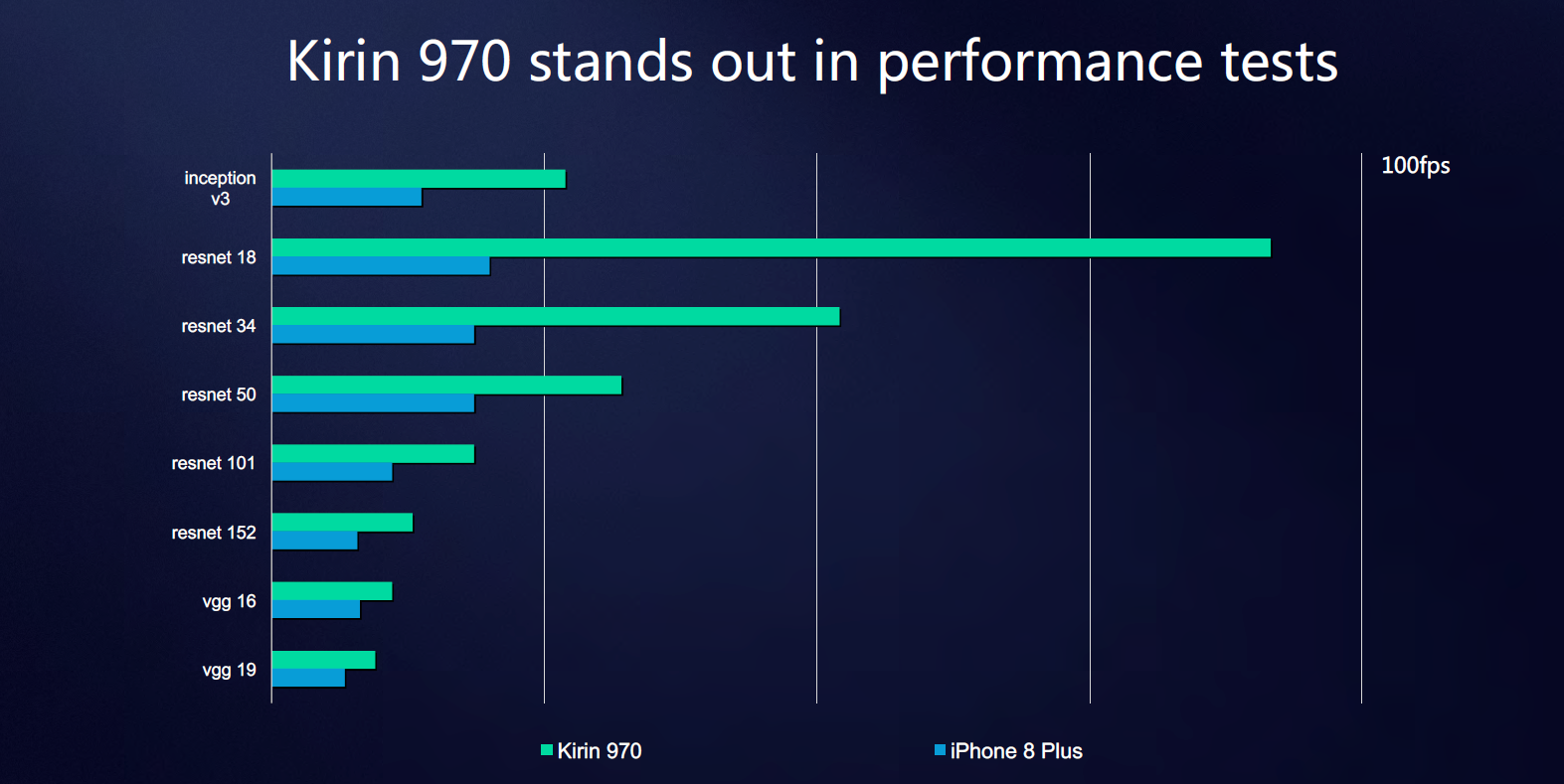
While we can’t run the Master Lu AI test on an iPhone, HiSilicon did publish some slides with reported internally numbers we can try to correlate. Based on the models included in the slide, the Apple A11 neural network IP’s performance should land somewhere slightly ahead of the Snapdragon 835’s DSP but still far behind the Kirin NPU, but again we can't independently verify these figures due to lack of a fitting iOS benchmark we can run ourselves.

Of course the important question is, what is this all good for? HiSilicon discloses that one use-case being used is noise reduction via CNN processing, and thus is able to increase voice recognition rate in heavy traffic from 80% to 92%.

The other most publicised use-case is the implementation in the camera app. The Mate 10’s camera makes use of the NPU to run inferencing to recognize different scenarios and optimize the camera settings based on pre-sets for those scenarios. The Mate 10 comes with a translation app which was developed with Microsoft, which is able to use the NPU for accelerated offline translation, and this was definitely the single most impressive usage for me. Inside the built-in gallery application we also see the use of image classification to create a new section where pictures are organized by content type. The former scenarios where the SoC is doing live inferencing on a media stream such as the camera feed is also the use-case where HiSilicon has an advantage over Qualcomm as employs both a DSP and the NPU whereas Snapdragon SoCs have to share the DSP resources between vision processing and neural network inferencing workloads.
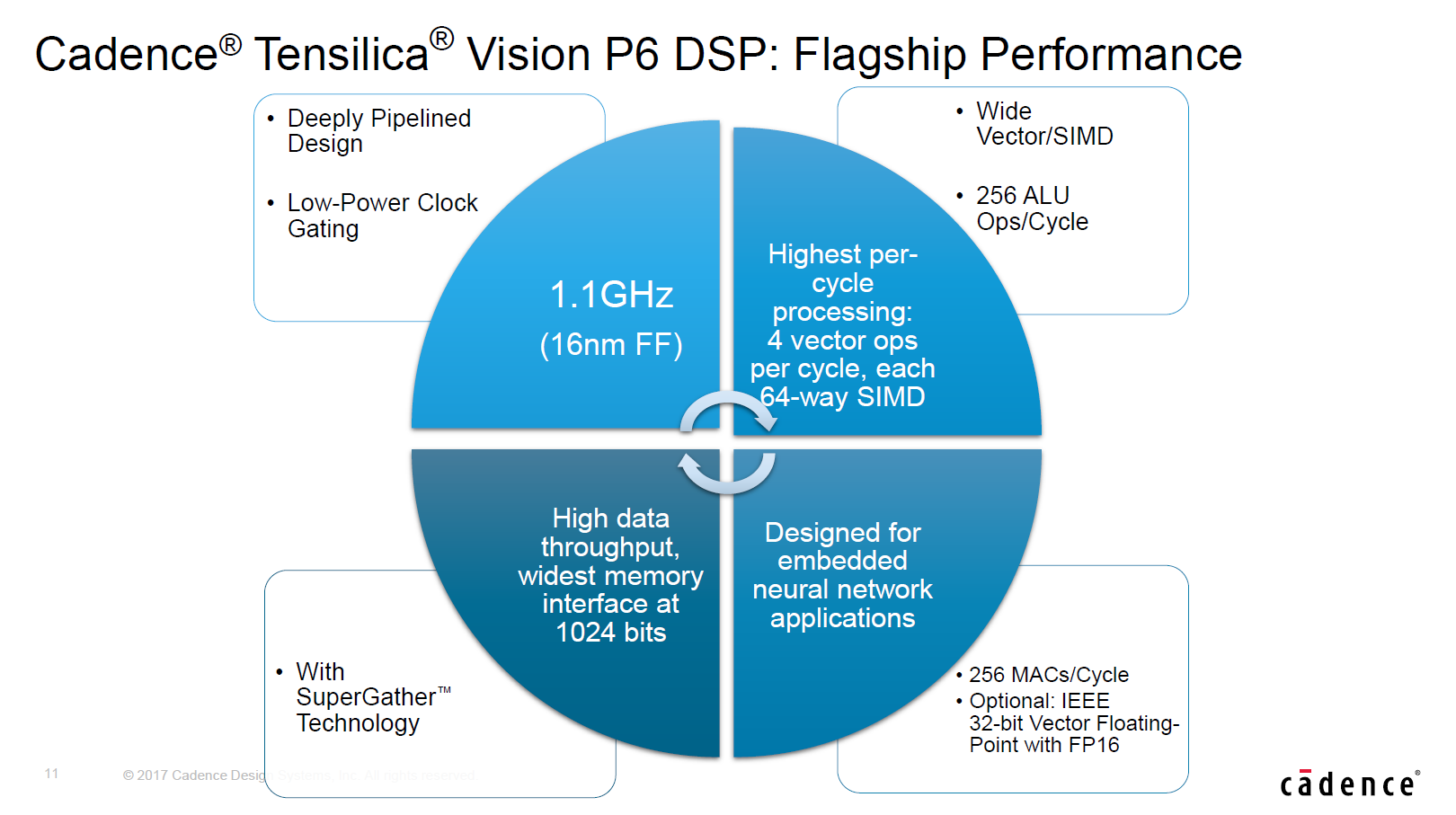
Oddly enough the Kirin 970 has sort of double the silicon IP capable of running neural network efficiently as its vision pipeline also includes a Cadence Tensilica Vision P6 DSP which should be in the same performance class as Qualcomm’s Hexagon 680 DSP, but is currently not exposed for user applications.
While the Mate 10 does make some use of the NPU it’s hard to argue that it’s a definitive differentiating factor for the end-user. Currently neural network usage in mobile doesn’t seem to have the same killer-applications that they have in automotive and security camera sectors. Again this is due to the ecosystem being its early days and the Mate 10 among the first devices to actually offer such a dedicated acceleration block. It’s arguable if it’s worth it for the Kirin 970 to have implemented such a piece and Huawei is very open about the fact that it’s reaching out to developers to try and find more use-cases for the silicon, and at least Huawei should be lauded for innovating with something new.
Huawei/Microsoft's translation app seemed to be the most distinguished experience on the Mate 10 so maybe there’s more non-image based use-cases that can be explored in the future. Currently the app allows the traditional snapshot of a foreign language text and then shows a translated overlay, but imagine a future implementation where it’s able to do it live from the camera feed and allow for an AR experience. MediaTek at CES also showed a distinguishing use-case of using CNNs: for video conferencing the video encoder is fed metadata on scene composition by a CNN layer doing image recognition and telling the encoder to use finer-grained block sizes where a user’s face would be, thus increasing video quality. It’s more likely that neural network use-cases will slowly creep up with time rather than there being a new revolutionary thing, as more devices will start to incorporate such IPs and they become more widespread so will developers be more enticed to find uses for them.








116 Comments
View All Comments
StormyParis - Monday, January 22, 2018 - link
If the Modem IP is Huawei's one true in-house part, why didn't you at least test it alongside the CPU and GPU ? I'd assume in the real world, ti too has a large impact on batteyr and performance ?Ian Cutress - Monday, January 22, 2018 - link
The kit to properly test a modem power/attenuation to battery is around $50-100k. We did borrow one once, a few years ago, but it was only short-term loan. Not sure if/when we'll be able to do that testing again.juicytuna - Monday, January 22, 2018 - link
How does Mali have so many design wins? Why did Samsung switch from PowerVR to Mali? Cost savings? Politics? Because it clearly wasn't a descistion made on technical merit.lilmoe - Tuesday, January 23, 2018 - link
Because OEMs like Samsung are not stupid? And Mali is actually very power efficient and competitive?What are you basing your GPU decision on? Nothing in the articles provides evidence that Mali is less efficient than Adreno in UI acceleration or 60fps capped popular games (or even 60fps 1080p normalized T-Rex benchmark)...
Measuring the constant power draw of the GPU, which is supposed to be reached in vert short bursts, is absolutely meaningless.
lilmoe - Tuesday, January 23, 2018 - link
***Measuring the max (constant) power draw of the GPU, which is supposed to be reached in very short bursts during a workload, is absolutely meaningless.jospoortvliet - Saturday, January 27, 2018 - link
Your argument is half-way sensible for a CPU but not for a GPU.A GPU should not even HAVE a boost clock - there is no point in that for typical GPU workloads. Where a CPU is often active in bursts, a GPU has to sustain performance in games - normal UI work barely taxes it anyway.
So yes the max sustained performance and associated efficiency is ALL that matters. And MALI, at least in the implementations we have seen, is behind.
lilmoe - Sunday, January 28, 2018 - link
I think you're confusing fixed function processing with general purpose GPUs. Modern GPU clocks behave just like CPU cores, and yes, with bursts, just like NVidia's and AMD's. Not all scenes rendered in a game, for example, need the same GPU power, and not all games have the same GPU power needs.Yes, there is a certain performance envelope that most popular games target. That performance envelope/ target is definitely not SlingShot nor T-rex.
This is where Andrei's and your argument crumbles. You need to figure out that performance target and measure efficiency and power draw at that target. That's relatively easy to do; open up candy crush and asphalt 8 and measure in screen fps and power draw. That's how you measure efficiency on A SMARTPHONE SoC. Your problem is that you think people are using these SoCs like they would on a workstation. They don't. No one is going to render a 3dmax project on these phones, and there are no games that even saturate last year's flagship mobile gpu.
Not sure if you're not getting my simple and sensible point, or you're just being stubborn about it. Mobile SoC designed have argued for bursty gpu behavior for years. You guys need to get off your damn high horse and stop deluding yourself into thinking that you know better. What Apple or Qualcomm do isn't necessarily best, but it might be best for the gpu architecture THEY'RE using.
As for the CPU, you agree but Andrei insists on making the same mistake. You DON'T measure efficiency at max clocks. Again, max clocks are used in bursts and only for VERY short periods of time. You measure efficient by measuring the time it takes to complete a COMMON workload and the total power it consumes at that. Another hint, that common workload is NOT geekbench, and it sure as hell isn't SPEC.
lilmoe - Sunday, January 28, 2018 - link
The A75 is achieving higher performance mostly with higher clocks. The Exynos M3 is a wide core WITH higher clocks. Do you really believe these guys are idiots? You really think that's going to affect efficiency negatively? You think Android OEMs will make the same "mistake" Apple did and not provide adequate and sustainable power delivery?Laughable.
futrtrubl - Monday, January 22, 2018 - link
"The Kirin 970 in particular closes in on the efficiency of the Snapdragon 835, leapfrogging the Kirin 960 and Exynos SoCs."Except according to the chart right above it the 960 is still more efficient.
Andrei Frumusanu - Monday, January 22, 2018 - link
The efficiency axis is portrayed as energy (joules) per performance (test score). In this case the less energy used, the more efficient, meaning the shorter the bars, the better.