The Intel Optane SSD 900p 480GB Review: Diving Deeper Into 3D XPoint
by Billy Tallis on December 15, 2017 12:15 PM ESTRandom Read Performance
Our first test of random read performance uses very short bursts of operations issued one at a time with no queuing. The drives are given enough idle time between bursts to yield an overall duty cycle of 20%, so thermal throttling is impossible. Each burst consists of a total of 32MB of 4kB random reads, from a 16GB span of the disk. The total data read is 1GB.
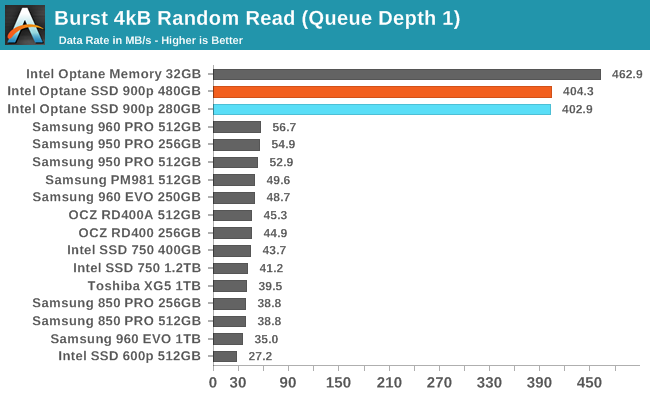
Random reads at queue depth 1 are where Intel's Optane products shine. Compared to the fastest NVMe SSDs using MLC NAND flash, the Optane SSDs aren't quite an order of magnitude faster, but only because the latency of the NVMe protocol over PCIe becomes the bottleneck. Intel's tiny Optane Memory M.2 cache drive is slightly faster in this one benchmark, but the difference hardly matters.
Our sustained random read performance is similar to the random read test from our 2015 test suite: queue depths from 1 to 32 are tested, and the average performance and power efficiency across QD1, QD2 and QD4 are reported as the primary scores. Each queue depth is tested for one minute or 32GB of data transferred, whichever is shorter. After each queue depth is tested, the drive is given up to one minute to cool off so that the higher queue depths are unlikely to be affected by accumulated heat build-up. The individual read operations are again 4kB, and cover a 64GB span of the drive.
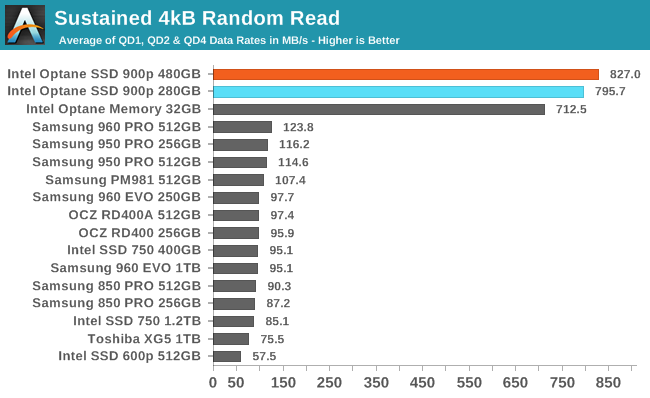
Adding some higher queue depths to the average shows a small speed advantage for the 480GB Optane SSD over the 280GB model, and the Optane Memory M.2 starting to fall behind the larger Optane SSDs. The NAND flash-based SSDs also pick up speed as queue depths grow, but they need to go far beyond QD4 to catch up.
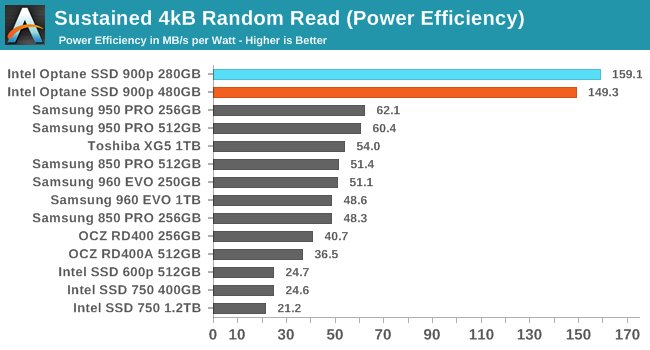
Given how thoroughly the Optane SSDs have shattered the record for random read performance, it's not too surprising to see them at the top of the charts for power efficiency when performing random reads. The 480GB Optane SSD is a bit less efficient than the smaller model because it has to power significantly more 3D XPoint memory chips with only a small performance boost to show for it. Compared to the flash-based SSDs, the Optane SSDs are only about 2.5 times more efficient, despite being about 7 times faster. The performance doesn't come for free.
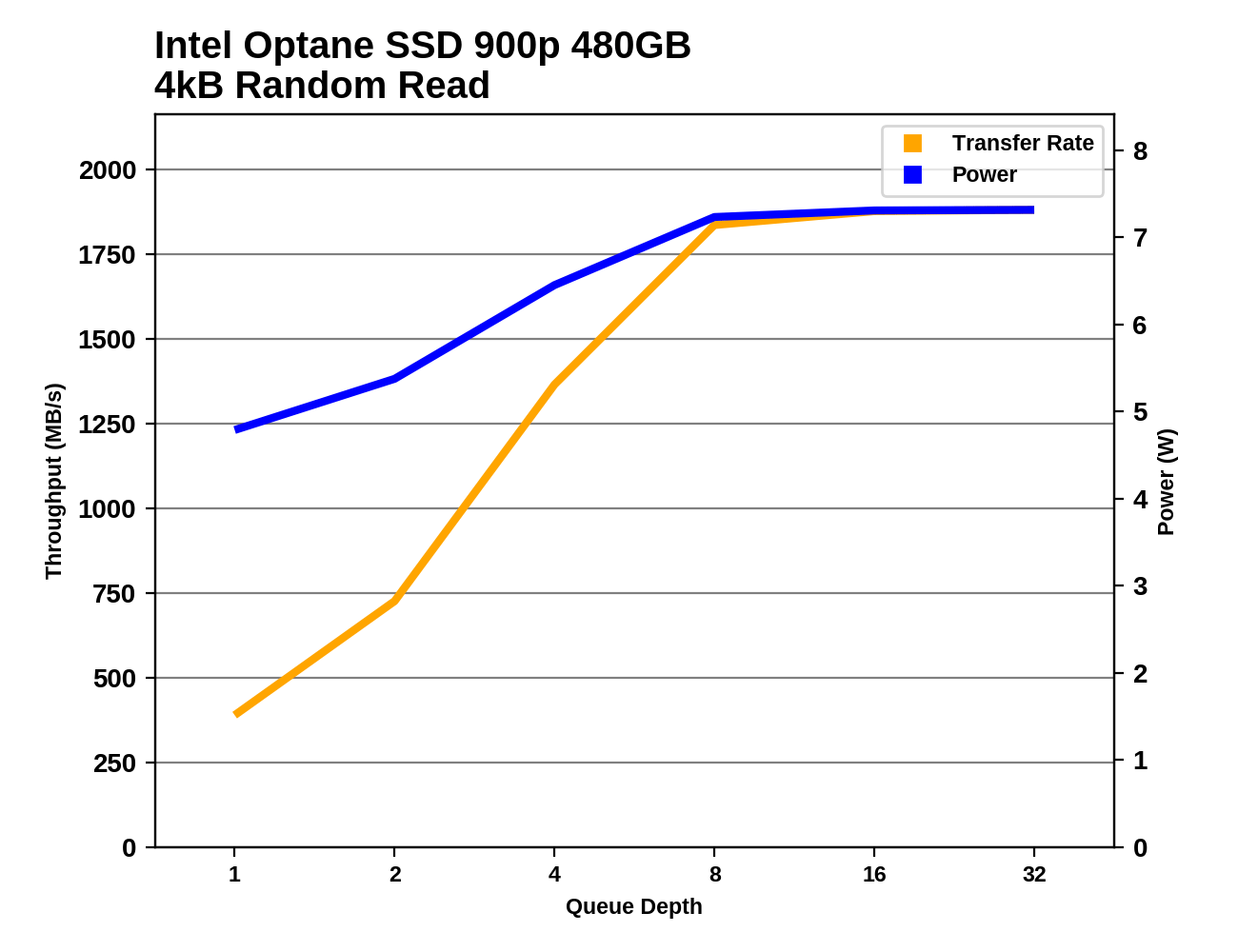 |
|||||||||
At low queue depths the two Optane SSDs offer nearly the same random read performance. When they both reach saturation at QD8, the 480GB model has slightly higher performance, and is drawing about 0.85W more power—a 13% power increase for a 7% performance boost.
Random Write Performance
Our test of random write burst performance is structured similarly to the random read burst test, but each burst is only 4MB and the total test length is 128MB. The 4kB random write operations are distributed over a 16GB span of the drive, and the operations are issued one at a time with no queuing.
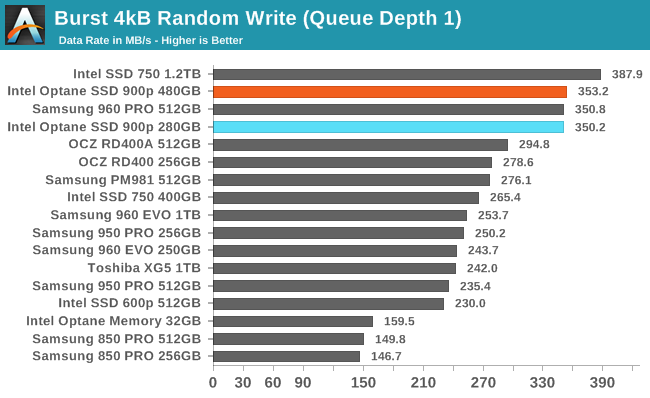
The random write performance at queue depth 1 of the Optane SSDs is great, but not record-setting. Flash-based SSDs can cache write operations in their DRAM and report the command as complete before the data has actually made it to the flash memory. This means that for most flash-based SSDs the burst random write speed is more of a controller benchmark than a test of the storage itself. The Optane SSDs don't have large DRAM caches on the drive and are actually writing to the 3D XPoint memory almost as quickly as the Intel SSD 750 can stash the writes in its DRAM.
As with the sustained random read test, our sustained 4kB random write test runs for up to one minute or 32GB per queue depth, covering a 64GB span of the drive and giving the drive up to 1 minute of idle time between queue depths to allow for write caches to be flushed and for the drive to cool down.
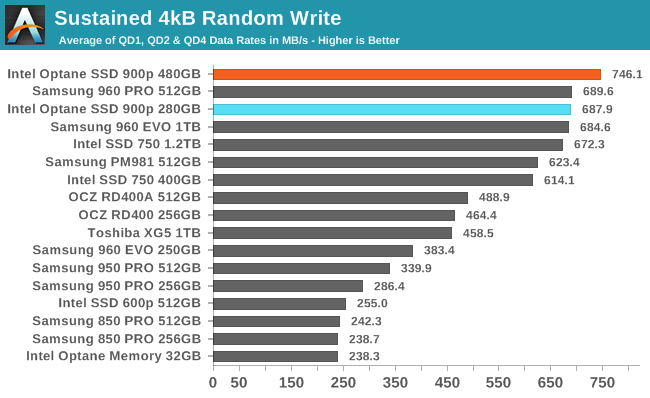
With larger queue depths and test durations long enough to defeat any DRAM-based write caching and many SLC write caches, the Optane SSDs rise to the top. With this second round of testing, the 280GB Optane SSD performed slightly worse than the first run, but it's still essentially tied with the fastest flash-based SSDs. The 480GB model is a tiny bit faster than even the previous record from the 280GB model, putting it about 8% faster than the Samsung 960 PRO.
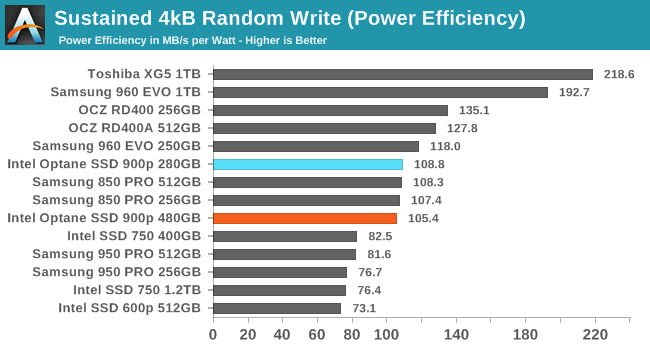
Without a huge performance lead, the high power consumption of the Optane SSDs takes a toll on their efficiency scores for random writes. They are ahead of early NVMe SSDs and on par with the fastest SATA SSDs, but the best current flash-based NVMe SSDs are substantially more efficient. The Toshiba XG5 prioritized efficiency over peak performance and ends up offering more than twice the power efficiency of the Optane SSDs, while the Samsung 960 EVO has a mere 77% efficiency advantage at essentially the same level of performance.
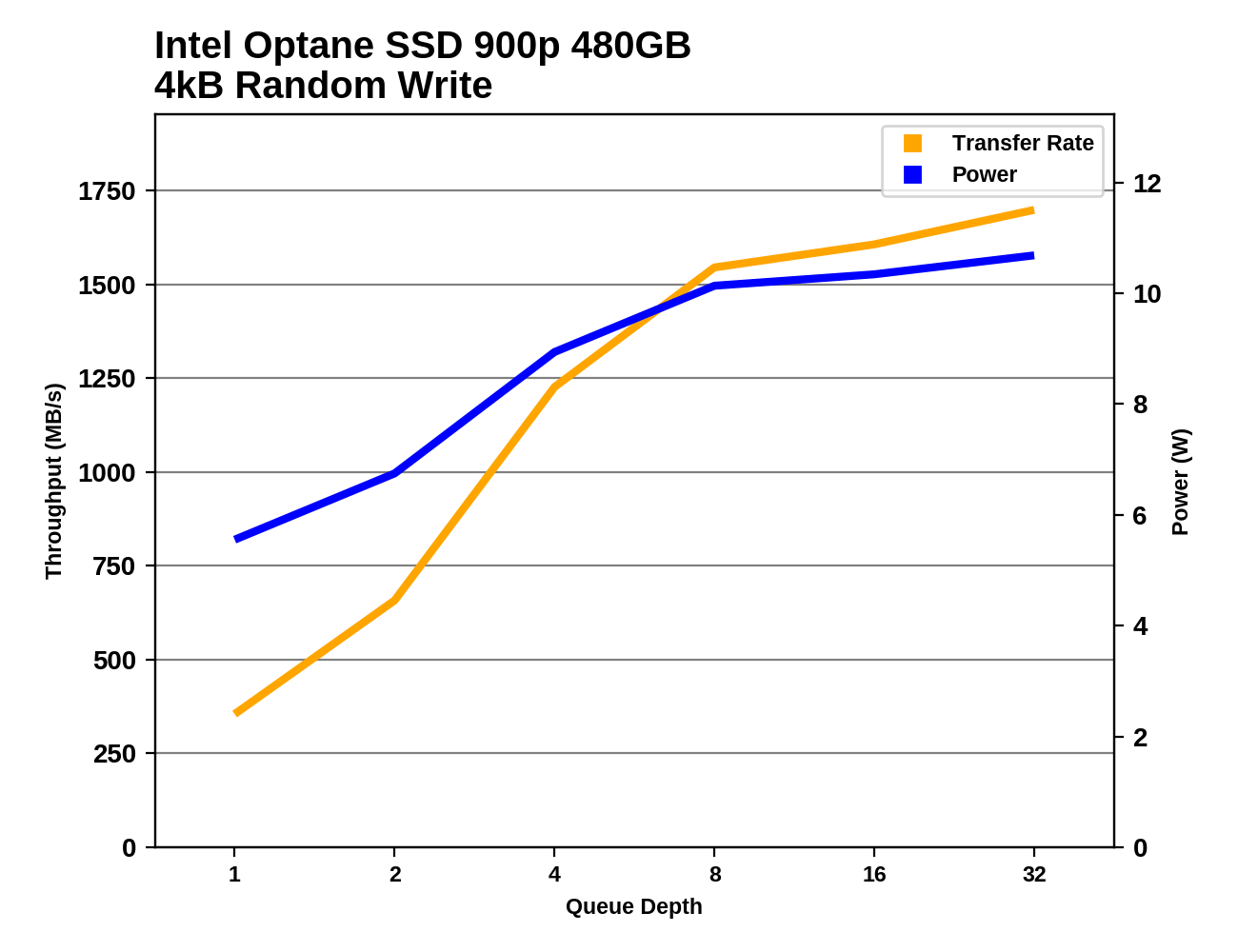 |
|||||||||
As with random reads, the performance and power consumption gap between the two Optane SSD 900p capacities widens at higher queue depths. With power consumption starting at 5W and climbing to over 10W for the larger model, the Optane SSDs are in a completely different league from M.2 NVMe SSDs, which mostly top out around 4.5W.








69 Comments
View All Comments
Notmyusualid - Sunday, December 17, 2017 - link
So, when you are at gun point, in a corner, you finally concede defeat?I think you need professional help.
tuxRoller - Friday, December 15, 2017 - link
If you are staying with a single thread submission model Windows may we'll have a decent sized advantage with both iocp and rio. Linux kernel aio is just such a crap shoot that it's really only useful if you run big databases and you set it up properly.IntelUser2000 - Friday, December 15, 2017 - link
"Lower power consumption will require serious performance compromises.Don't hold your breath for a M.2 version of the 900p, or anything with performance close to the 900p. Future Optane products will require different controllers in order to offer significantly different performance characteristics"
Not necessarily. Optane Memory devices show the random performance is on par with the 900P. It's the sequential throughput that limits top-end performance.
While its plausible the load power consumption might be impacted by performance, not always true for idle. The power consumption in idle can be cut significantly(to 10's of mW levels) by using a new controller. It's reasonable to assume the 900P uses the controller derived from the 750, which is also power hungry.
p1esk - Friday, December 15, 2017 - link
Wait, I don't get it: the operation is much simpler than flash (no garbage collection, no caching, etc), so the controller should be simpler. Then why does it consume more power?IntelUser2000 - Friday, December 15, 2017 - link
You are still confusing load power consumption with idle power consumption. What you said makes sense for load, when its active. Not for idle.Optane Memory devices having 1/3rd the idle power demonstrates its due to the controller. They likely wanted something with short TTM, so they chose whatever controller they had and retrofitted it.
rahvin - Friday, December 15, 2017 - link
Optane's very nature as a heat based phase change material is always going to result in higher power use than NAND because it's always going to take more energy to heat a material up than it would to create a magnetic or electric field.tuxRoller - Saturday, December 16, 2017 - link
That same nature also means that it will require less energy per reset as the process node shrinks (roughly e~1/F).In general, pcm is a much more amenable to process scaling than nand.
CheapSushi - Friday, December 15, 2017 - link
Keep in mind a big part of the sequential throughput limit is the fact that the Optane M.2s are x2 PCIe lanes. This AIC is x4. Most NAND M.2 sticks are x4 as well.twotwotwo - Friday, December 15, 2017 - link
I'm curious whether it's possible to get more IOPS doing random 512B reads, since that's the sector size this advertises.When the description of the memory tech itself came out, bit addressability--not having to read any minimum block size--was a selling point. But it may be that the controller isn't actually capable of reading any more 512B blocks/s than 4KB ones, even if the memory and the bus could handle it.
I don't think any additional IOPS you get from smaller reads would help most existing apps, but if you were, say, writing a database you wanted to run well on this stuff, it'd be interesting to know that small reads help.
tuxRoller - Friday, December 15, 2017 - link
Those latencies seem pretty high. Was this with Linux or Windows? The table on page one indicates both were used.Can you run a few of these tests against a loop mounted ram block device? I'm curious to see what both the min, average and standard deviation values of latency look like when the block layer is involved.