Dissecting Intel's EPYC Benchmarks: Performance Through the Lens of Competitive Analysis
by Johan De Gelas & Ian Cutress on November 28, 2017 9:00 AM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Skylake-SP
- Xeon Platinum
- EPYC
- EPYC 7601
HPC Benchmarks
Discussing HPC benchmarks feels always like opening a can of worms to me. Each benchmark requires a thorough understanding of the software and performance can be tuned massively by using the right compiler settings. And to make matters worse: in many cases, these workloads can be run much faster on a GPU or MIC, making CPU benchmarking in some situations irrelevant.
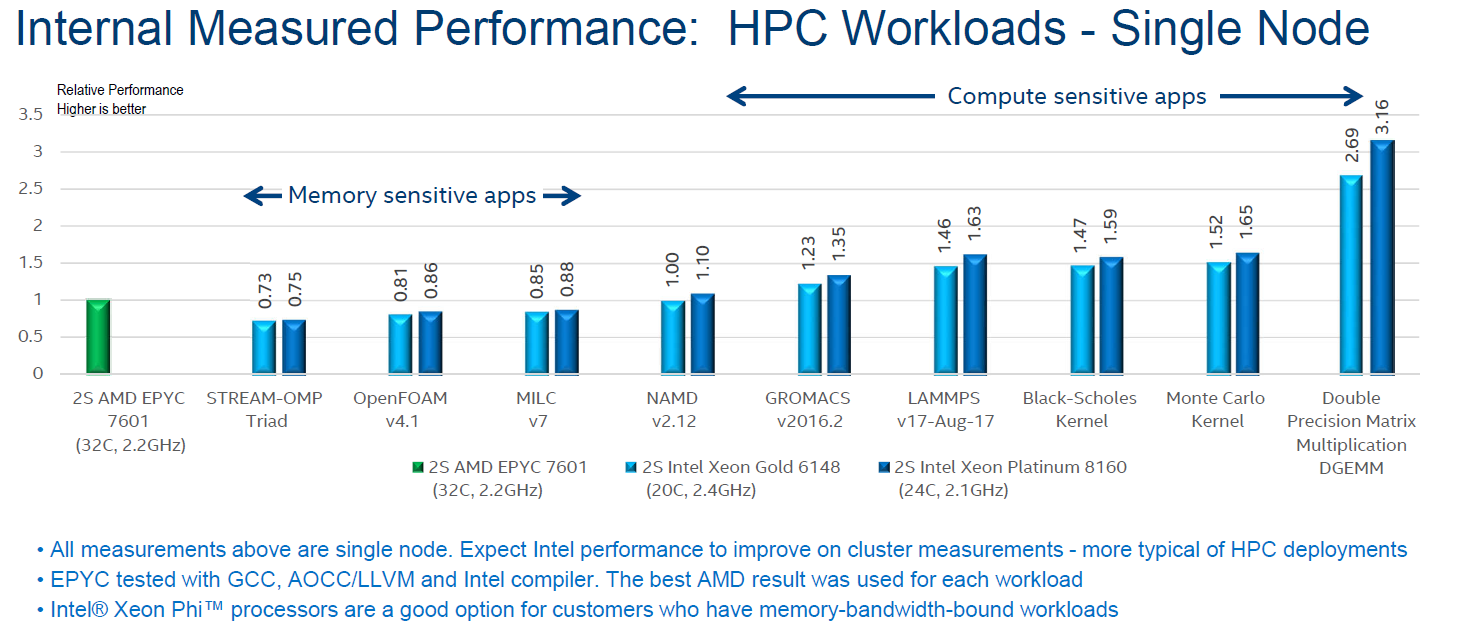
NAMD (NAnoscale Molecular Dynamics) is a molecular dynamics application designed for high-performance simulation of large biomolecular systems. It is rather memory bandwidth limited, as even with the advantage of an AVX-512 binary, the Xeon 8160 does not defeat the AVX2-equipped AMD EPYC 7601.
LAMMPS is classical molecular dynamics code, and an acronym for Large-scale Atomic/Molecular Massively Parallel Simulator. GROMACS (for GROningen MAchine for Chemical Simulations) primarily does simulations for biochemical molecules (bonded interactions). Intel compiled the AMD version with the Intel compiler and AVX2. The Intel machines were running AVX-512 binaries.
For these three tests, the CPU benchmarks results do not really matter. NAMD runs about 8 times faster on an NVIDIA P100. LAMMPS and GROMACS run about 3 times faster on a GPU, and also scale out with multiple GPUs.
Monte Carlo is a numerical method that uses statistical sampling techniques to approximate solutions to quantitative problems. In finance, Monte Carlo algorithms are used to evaluate complex instruments, portfolios, and investments. This is a compute bound, double precision workload that does not run faster on a GPU than on Intel's AVX-512 capable Xeons. In fact, as far as we know the best dual socket Xeons are quite a bit faster than the P100 based Tesla. Some of these tests are also FP latency sensitive.
Black-Scholes is another popular mathematical model used in finance. As this benchmark is also double precision, the dual socket Xeons should be quite competitive compared to GPUs.
So only the Monte Carlo and Black Scholes are really relevant, showing that AVX-512 binaries give the Intel Xeons the edge in a limited number of HPC applications. In most HPC cases, it is probably better to buy a much more affordable CPU and to add a GPU or even a MIC.
The Caveats
Intel drops three big caveats when reporting these numbers, as shown in the bullet points at the bottom of the slide.
Firstly is that these are single node measurements: One 32-core EPYC vs 20/24-core Intel processors. Both of these CPUs, the Gold 6148 and the Platinum 8160, are in the ball-park pricing of the EPYC. This is different to the 8160/8180 numbers that Intel has provided throughout the rest of the benchmarking numbers.
The second is the compiler situation: in each benchmark, Intel used the Intel compiler for Intel CPUs, but compiled the AMD code on GCC, LLVM and the Intel compiler, choosing the best result. Because Intel is going for peak hardware performance, there is no obvious need for Intel to ensure compiler parity here. Compiler choice, as always, can have a substantial effect on a real-world HPC can of worms.
The third caveat is that Intel even admits that in some of these tests, they have different products oriented to these workloads because they offer faster memory. But as we point out on most tests, GPUs also work well here.








105 Comments
View All Comments
smilingcrow - Tuesday, November 28, 2017 - link
TSX has been implemented but how about ASF?CajunArson - Tuesday, November 28, 2017 - link
Incidentally, for anybody who think Intel "cheated" with those numbers there's concrete proof from independent third-party reviewers that at least the GROMACS benchmark results that Intel itself is showing are not fully accurate... as in they are not fully accurate in *AMD's favor*.Here's a link to GROMACS results from Serve the Home that are actually using the newest version that finally turns on the AVX-512 support to show you what the Xeon platform was actually designed to do: https://www.servethehome.com/wp-content/uploads/20...
So just remember that Intel is being pretty conservative with these numbers if their own published GROMACS results are anything to go by.
MonkeyPaw - Tuesday, November 28, 2017 - link
I would hope they’d be conservative in this sector. I’m guessing very knowledgeable people will be making the buying decisions here, and there may even be contractual expectations from the purchasing companies. Over promising and under delivering on an internal report might not just cost a few big sales, they might even result in lawsuits.tamalero - Tuesday, November 28, 2017 - link
I think the problem is while intel usually uses the most optimized compilers and systems. They usually do not optimize the intel systems at all. At least in the consumer benchmarks.Not so sure about these enterprise because I have no idea what most of these tests do.
jjj - Tuesday, November 28, 2017 - link
The biggest lie is through omission, the bulk of the volumes is at rather low ASP so if you are gonna test test 1k$ and bellow SoCs and use the I/O offered by each.eek2121 - Tuesday, November 28, 2017 - link
I would be interested to see how AMD EPYC processors with lower core counts perform in the database benchmarks, as they should have few NUMA nodes.CajunArson - Tuesday, November 28, 2017 - link
Wrong. You clearly don't understand how Epyc works. Literally every Epyc chip has the same number of NUMA nodes regardless of core count from the 7601 all the way down to the super-stripped down parts.Each chip has 4 dies that produce the same number of NUMA nodes, AMD just turns off cores on the lower-end parts.
Maybe you should have actually learned about what Epyc was instead of wasting your time posting ignorant attacks on other people's posts.
eek2121 - Tuesday, November 28, 2017 - link
The same goes for you. My ignorance with EPYC stems from poor availability and the lack of desire to learn about EPYC. You seem to have a full time job trolling on AnandTech. Go troll somewhere else.IGTrading - Tuesday, November 28, 2017 - link
Chill guys :)Reading your posts I see you're both right, just using examples of different use cases.
P.S. Cajun seems like a bit of an avid Intel supporter as well, but he's right : in AVX512 and in some particular software, Intel offers excellent performance.
But that comes at a price, plus some more power consumption, plus the inability to upgrade (considering what Intel usually does to its customers) .
iwod - Tuesday, November 28, 2017 - link
poor availability - do dell offer AMD now?