Dissecting Intel's EPYC Benchmarks: Performance Through the Lens of Competitive Analysis
by Johan De Gelas & Ian Cutress on November 28, 2017 9:00 AM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Skylake-SP
- Xeon Platinum
- EPYC
- EPYC 7601
Enterprise & Cloud Benchmarks
Below you can find Intel's internal benchmarking numbers. The EPYC 7601 is the reference (performance=1), the 8160 is represented by the light blue bars, the top of the line 8180 numbers are dark blue. On a performance per dollar metric, it is the light blue worth observing.
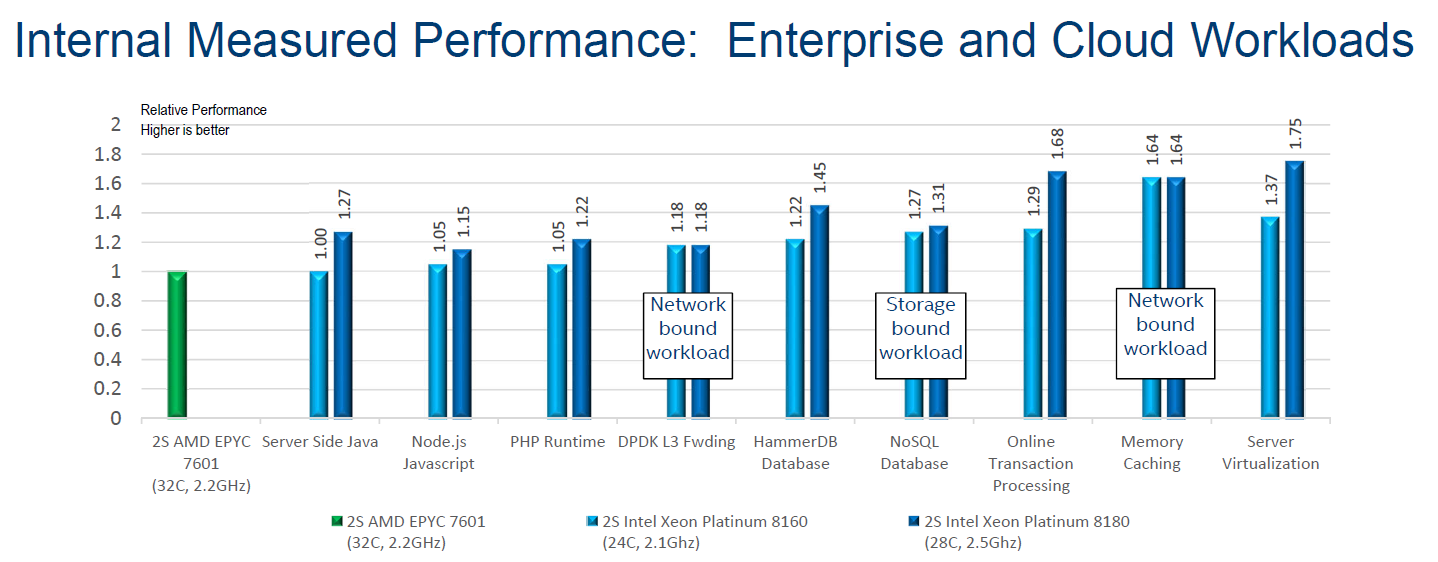
Java benchmarks are typically unrealistically tuned, so it is a sign on the wall when an experienced benchmark team is not capable to make the Intel 8160 shine: it is highly likely that the AMD 7601 is faster in real life.
The node.js and PHP runtime benchmarks are very different. Both are open source server frameworks to generate for example dynamic page content. Intel uses a client load generator to generate a real workload. In the case of the PHP runtime, MariaDB (MySQL derivative) 10.2.8 is the backend.
In the case of Node.js, mongo db is the database. A node.js server spawns many different single threaded processes, which is rather ideal for the AMD EPYC processor: all data is kept close to a certain core. These benchmarks are much harder to skew towards a certain CPU family. In fact, Intel's benchmarks seem to indicate that the AMD EPYC processors are pretty interesting alternatives. Surely if Intel can only show a 5% advantage with a 10% more expensive processor, chances are that they perform very much alike in the real world. In that case, AMD has a small but tangible performance per dollar advantage.
The DPDK layer 3 Network Packet Forwarding is what most of us know as routing IP packets. This benchmark is based upon Intel own Data Plane Developer Kit, so it is not a valid benchmark to use for an AMD/Intel comparison.
We'll discuss the database HammerDB, NoSQL and Transaction Processing workloads in a moment.
The second largest performance advantage has been recorded by Intel testing the distributed object caching layer memcached. As Intel notes, the benchmark was not a processing-intensive workload, but rather a network-bound workload. As AMD's dual socket system is seen as a virtual 8-socket system, due to the way that AMD has put four dies onto each processor and each die has a sub-set of PCIe lanes linked to it, AMD is likely at a disadvantage.
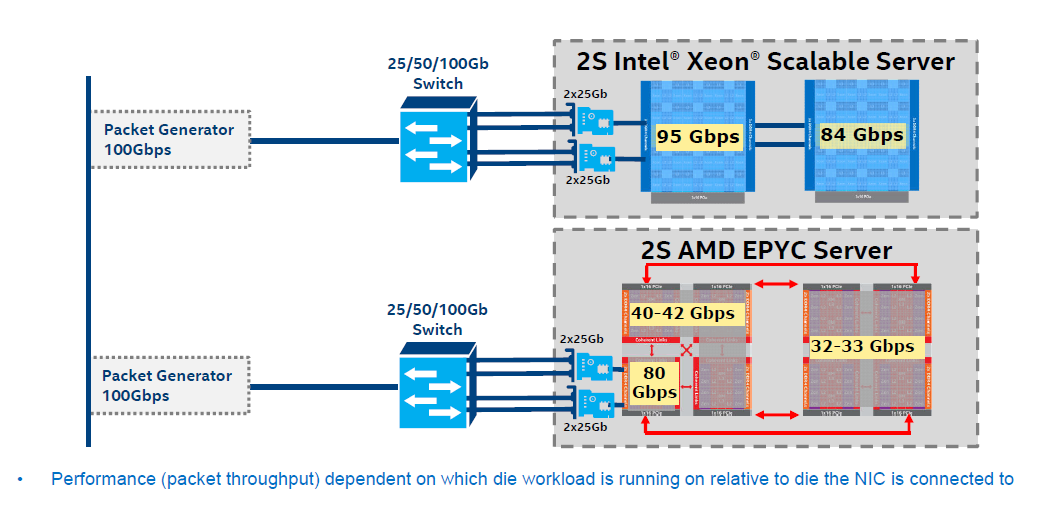
Intel's example of network bandwidth limitations in a pseudo-socket configuration
Suppose you have two NICs, which is very common. The data of the first NIC will, for example, arrive in NUMA node 1, Socket 1, only to be accessed by NUMA node 4, Socket 1. As a result, there is some additional latency incurred. In Intel's case, you can redirect a NIC to each socket. With AMD, this has to be locally programmed, to ensure that the packets that are sent to each NICs are processed on each virtual node, although this might incur additional slowdown.
The real question is whether you should bother to use a 2S system for Memached. After all, it is distributed cache layer that scales well over many nodes, so we would prefer a more compact 1S system anyway. In fact, AMD might have an advantage as in the real world, Memcached systems are more about RAM capacity than network or CPU bottlenecks. Missing the additional RAM-as-cache is much more dramatic than waiting a bit longer for a cache hit from another server.
The virtualization benchmark is the most impressive for the Intel CPUs: the 8160 shows a 37% performance improvement. We are willing to believe that all the virtualization improvements have found their way inside the ESXi kernel and that Intel's Xeon can deliver more performance. However, in most cases, most virtualization systems run out of DRAM before they run out of CPU processing power. The benchmarking scenario also has a big question mark, as in the footnotes to the slides Intel achieved this victory by placing 58 VMs on the Xeon 8160 setup versus 42 VMs on the EPYC 7601 setup. This is a highly odd approach to this benchmark.
Of course, the fact that the EPYC CPU has no track record is a disadvantage in the more conservative (VMware based) virtualization world anyway.








105 Comments
View All Comments
smilingcrow - Tuesday, November 28, 2017 - link
TSX has been implemented but how about ASF?CajunArson - Tuesday, November 28, 2017 - link
Incidentally, for anybody who think Intel "cheated" with those numbers there's concrete proof from independent third-party reviewers that at least the GROMACS benchmark results that Intel itself is showing are not fully accurate... as in they are not fully accurate in *AMD's favor*.Here's a link to GROMACS results from Serve the Home that are actually using the newest version that finally turns on the AVX-512 support to show you what the Xeon platform was actually designed to do: https://www.servethehome.com/wp-content/uploads/20...
So just remember that Intel is being pretty conservative with these numbers if their own published GROMACS results are anything to go by.
MonkeyPaw - Tuesday, November 28, 2017 - link
I would hope they’d be conservative in this sector. I’m guessing very knowledgeable people will be making the buying decisions here, and there may even be contractual expectations from the purchasing companies. Over promising and under delivering on an internal report might not just cost a few big sales, they might even result in lawsuits.tamalero - Tuesday, November 28, 2017 - link
I think the problem is while intel usually uses the most optimized compilers and systems. They usually do not optimize the intel systems at all. At least in the consumer benchmarks.Not so sure about these enterprise because I have no idea what most of these tests do.
jjj - Tuesday, November 28, 2017 - link
The biggest lie is through omission, the bulk of the volumes is at rather low ASP so if you are gonna test test 1k$ and bellow SoCs and use the I/O offered by each.eek2121 - Tuesday, November 28, 2017 - link
I would be interested to see how AMD EPYC processors with lower core counts perform in the database benchmarks, as they should have few NUMA nodes.CajunArson - Tuesday, November 28, 2017 - link
Wrong. You clearly don't understand how Epyc works. Literally every Epyc chip has the same number of NUMA nodes regardless of core count from the 7601 all the way down to the super-stripped down parts.Each chip has 4 dies that produce the same number of NUMA nodes, AMD just turns off cores on the lower-end parts.
Maybe you should have actually learned about what Epyc was instead of wasting your time posting ignorant attacks on other people's posts.
eek2121 - Tuesday, November 28, 2017 - link
The same goes for you. My ignorance with EPYC stems from poor availability and the lack of desire to learn about EPYC. You seem to have a full time job trolling on AnandTech. Go troll somewhere else.IGTrading - Tuesday, November 28, 2017 - link
Chill guys :)Reading your posts I see you're both right, just using examples of different use cases.
P.S. Cajun seems like a bit of an avid Intel supporter as well, but he's right : in AVX512 and in some particular software, Intel offers excellent performance.
But that comes at a price, plus some more power consumption, plus the inability to upgrade (considering what Intel usually does to its customers) .
iwod - Tuesday, November 28, 2017 - link
poor availability - do dell offer AMD now?