Dissecting Intel's EPYC Benchmarks: Performance Through the Lens of Competitive Analysis
by Johan De Gelas & Ian Cutress on November 28, 2017 9:00 AM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Skylake-SP
- Xeon Platinum
- EPYC
- EPYC 7601
HPC Benchmarks
Discussing HPC benchmarks feels always like opening a can of worms to me. Each benchmark requires a thorough understanding of the software and performance can be tuned massively by using the right compiler settings. And to make matters worse: in many cases, these workloads can be run much faster on a GPU or MIC, making CPU benchmarking in some situations irrelevant.
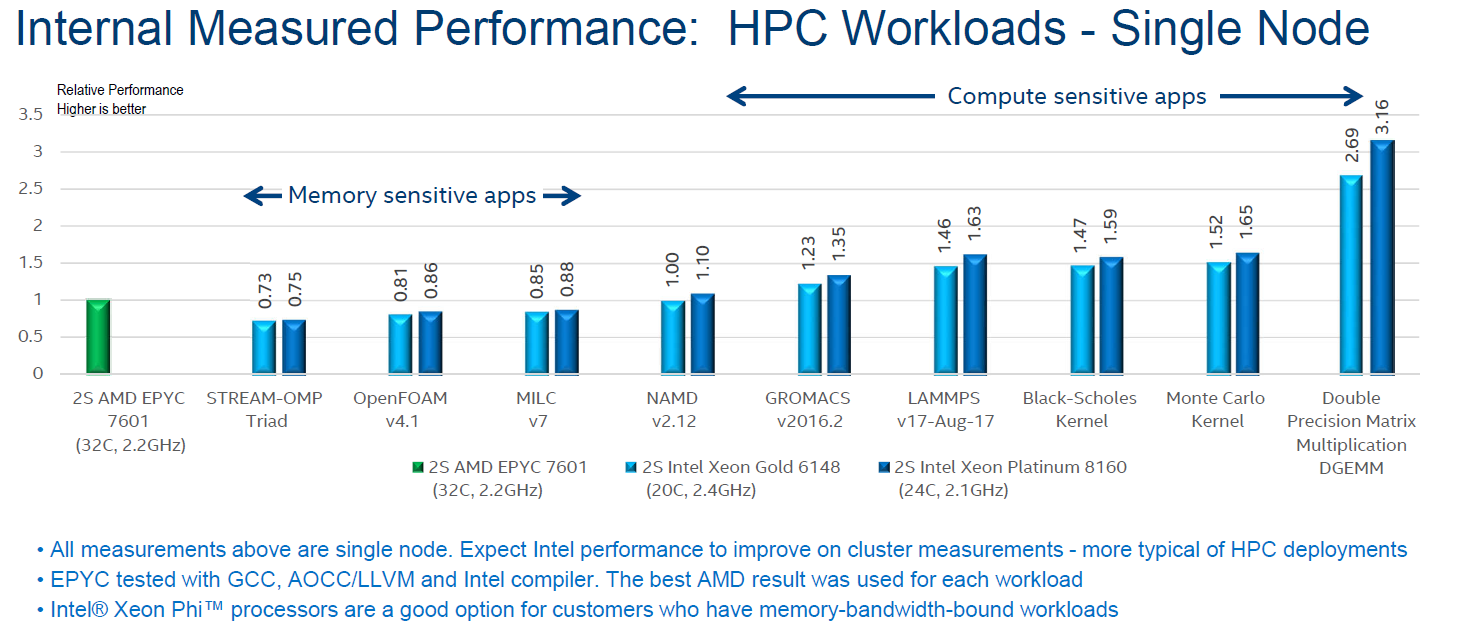
NAMD (NAnoscale Molecular Dynamics) is a molecular dynamics application designed for high-performance simulation of large biomolecular systems. It is rather memory bandwidth limited, as even with the advantage of an AVX-512 binary, the Xeon 8160 does not defeat the AVX2-equipped AMD EPYC 7601.
LAMMPS is classical molecular dynamics code, and an acronym for Large-scale Atomic/Molecular Massively Parallel Simulator. GROMACS (for GROningen MAchine for Chemical Simulations) primarily does simulations for biochemical molecules (bonded interactions). Intel compiled the AMD version with the Intel compiler and AVX2. The Intel machines were running AVX-512 binaries.
For these three tests, the CPU benchmarks results do not really matter. NAMD runs about 8 times faster on an NVIDIA P100. LAMMPS and GROMACS run about 3 times faster on a GPU, and also scale out with multiple GPUs.
Monte Carlo is a numerical method that uses statistical sampling techniques to approximate solutions to quantitative problems. In finance, Monte Carlo algorithms are used to evaluate complex instruments, portfolios, and investments. This is a compute bound, double precision workload that does not run faster on a GPU than on Intel's AVX-512 capable Xeons. In fact, as far as we know the best dual socket Xeons are quite a bit faster than the P100 based Tesla. Some of these tests are also FP latency sensitive.
Black-Scholes is another popular mathematical model used in finance. As this benchmark is also double precision, the dual socket Xeons should be quite competitive compared to GPUs.
So only the Monte Carlo and Black Scholes are really relevant, showing that AVX-512 binaries give the Intel Xeons the edge in a limited number of HPC applications. In most HPC cases, it is probably better to buy a much more affordable CPU and to add a GPU or even a MIC.
The Caveats
Intel drops three big caveats when reporting these numbers, as shown in the bullet points at the bottom of the slide.
Firstly is that these are single node measurements: One 32-core EPYC vs 20/24-core Intel processors. Both of these CPUs, the Gold 6148 and the Platinum 8160, are in the ball-park pricing of the EPYC. This is different to the 8160/8180 numbers that Intel has provided throughout the rest of the benchmarking numbers.
The second is the compiler situation: in each benchmark, Intel used the Intel compiler for Intel CPUs, but compiled the AMD code on GCC, LLVM and the Intel compiler, choosing the best result. Because Intel is going for peak hardware performance, there is no obvious need for Intel to ensure compiler parity here. Compiler choice, as always, can have a substantial effect on a real-world HPC can of worms.
The third caveat is that Intel even admits that in some of these tests, they have different products oriented to these workloads because they offer faster memory. But as we point out on most tests, GPUs also work well here.








105 Comments
View All Comments
beginner99 - Tuesday, November 28, 2017 - link
CPU price or server price are almost always irrelevant because the software running on them costs at least an order of magnitude more than the hardware itself. So you get the fastest server you need / the software profits from.ddriver - Tuesday, November 28, 2017 - link
Not necessarily, there is a lot of free and opensource software that is enterprise-capable.Also "the fastest server" actually sell in very small quantities. Clearly the cpu cost is not irrelevant as you claim. And clearly if it was irrelevant, intel would not even bother offering low price skus, which actually constitute the bulk of it sales, in terms of quantity as well as revenue.
yomamafor1 - Tuesday, November 28, 2017 - link
128GB for 32 core is suspiciously low.... For that kind of core count, generally the server has 512GB or above.Also, 128GB of memory in this day and age is definitely not $1,500 tops. Maybe in early 2016, but definitely not this year, and definitely not next year.
And from what I've seen, the two biggest cost factors in an enterprise grade server is the SSDs and memory. Generally memory accounts for 20% of the server cost, while SSD accounts for about 30%.
CPU generally accounts for 10% of the cost. Not insignificant, but definitely not "makes up half of the machine's budget".
AMD has a very hard battle to get back into the datacenter. Intel is already competing aggressively.
ddriver - Tuesday, November 28, 2017 - link
Care to share with us your "correct ram amount per cpu core" formula? There I was, thinking that the amount of ram necessary was determined by the use case, turns out it is a product of core count.bcronce - Tuesday, November 28, 2017 - link
In general a server running VMs is memory limited well before CPU limited.ddriver - Tuesday, November 28, 2017 - link
Not necessarily. It depends on what kind of work will those VMs be doing. Visualized or bare metal, configuration details are dictated by the target use case. Sure, you can also build universal machines and cram them full of as much cores and memory they can take, but that is very cost ineffective.I can think of a usage scenario that will be most balanced with a quad core cpu and 1 terabyte of ram. Lots of data, close to no computation taking place, just data reads and writes. A big in-memory database server.
I can think of a usage scenario that will be most balanced with a 32 core cpu and 64 gigabytes of ram. An average sized data set involved in heavy computation. A render farm node server.
ddriver - Tuesday, November 28, 2017 - link
*virtualized not visualized LOL, did way too many visualizations back in the day, hands now type on autopilot...yomamafor1 - Tuesday, November 28, 2017 - link
It is certainly determined by the use cases, but after interacting with hundreds of companies and their respective workloads, generally higher core counts are mapped to higher memory capacity.Of course, there are always very few fringe use cases that focuses significantly on compute.
Holliday75 - Saturday, December 9, 2017 - link
What about large players like Microsoft Azure or AWS? I have worked with both and neither uses anything close to what you guys talk about in terms of RAM or CPU. Its all about getting the most performance per watt. When you data center has its own substation your electric bill might be kinda high.submux - Thursday, November 30, 2017 - link
I will overlook the rudeness of your comment. I actively work with enterprise hardware and would probably not make comments like that and then recommend outfitting a server with 128GB of RAM. I don't think I've been near anything with as little as that in a long while. 128GB is circa 2012-2013.An enterprise needs 6 servers to ensure one operational node in a redundant environment. This is because in two data centers, you have 3 servers each. In case of a catastrophe, a full data center is lost and while a server is in maintenance and then finally another server fails. Therefore, you need precisely 6 servers to provide a reasonable SLA. 9 servers is technically more correct, in a proper 3 data center design.
If you know anything about storage, you would prefer more servers as more servers provides better storage response times... unless you're using SAN which is pretty much reserved strictly to people who simply don't understand storage and are willing to forfeit price, performance, reliability, stability, etc... to avoid actually taking a computer science education.
In enterprise IT, there are many things to consider. But for your virtualization platform, it's pretty simple. Fit as much capacity as possible in to as few U as possible while never dropping below 6 servers. Of course, I rarely work with less than 500 servers at a time, but I focus on taking messy 10,000+ server environments and shrinking them to 500 or less.
See, each server you add adds cost to operation. This means man-hours. Storage costs. Degradation of performance in the fabrics, etc... it introduces meaningless complexity and requires IT engineers to waste more and more hours building illogical platforms more focused on technology than the business they were implemented for.
If I approach a customer, I tend to let them know that unless they are prepared to invest at least $50,000 per server for 6 servers and $140,000 for the appropriate network, they should deploy using an IaaS solution (not cloud, never call IaaS cloud) where they can share a platform that was built to these requirements. The breaking point where IaaS is less economical than DIY is at about $500,000 with an OpEx investment of $400,000-$600,000 for power, connectivity, human resources, etc... annually and this doesn't even include having experts on the platform running on the data center itself.
So with less than a minimum of $1 million a year investment in just providing infrastructure (VMware, Nutanix, KVM, Hyper-V), not even providing a platform to run on it, you're just pissing the wrong way in the wind tunnel and wasting obscene amounts of money for no apparent reason on dead-end projects run by people who spend money without considering the value provided.
In addition, the people running your data center for that price are increasing in cost and their skillset is aging and decreasing in value over that time.
I haven't even mentioned power, cooling, rack space, cabling, managed PDUs, electricians, plumbers, fire control, etc...
Unless you're working with BIG DATA, an array of 2-4 TB drives for under $10,000 to feed even one 32-core AMD EPYC is such an insanely bad idea, it's borderline criminal stupidity. Let's not even discuss feeding pipelines of 6 32-core current generation CPUs per data center. It would be like trying to feed a blue whale with a teaspoon. In a virtualized configuration a deal EPYC server probably would need 100GB/s+ bandwidth to barely keep ahead of process starvation.
If you have any interest at all in return on investment in enterprise IT, you really need to up your game to make it work on paper.
Now... consider that if you're running a virtual data center... plain vanilla. Retail license cost of Windows Enterprise and VMware (vCenter, NSX, vSAN) for a dual 32-core EPYC is approximately $125,000 a server. Cutting back to dual 24-core with approximately the same performance would save about $30,000 a server in software alone.
I suppose I can go on and on... but let's be pretty clear CajunArson made a fair comment and probably is considering the cost of 1-2TB per server of RAM. Not 128GB which is more of a graphics workstation in 2017.