Intel Shipping Nervana Neural Network Processor First Silicon Before Year End
by Nate Oh on October 18, 2017 8:00 AM EST
This week at the Wall Street Journal’s D.Live 2017, Intel unveiled their Nervana Neural Network Processor (NNP), formerly known as Lake Crest, and announced plans to ship first silicon before the end of 2017. As a high-performance ASIC custom-designed and optimized for deep learning workloads, the NNP is the first generation of a new Intel product family, oriented for neural network training. From the beginning, the NNP and its Nervana Engine predecessor have aimed at displacing GPUs in the machine learning and AI space, where applications can range from weather prediction and autonomous vehicles to targeted advertising on social media.
Under development for the past three and a half years, the NNP originated as the Nervana Engine deep learning ASIC, which was announced in May 2016 and had all the marquee features of the NNP: HBM2, FlexPoint, cacheless software memory management, and a high-speed interconnect. Not too long after, Nervana was acquired by Intel in August 2016. Later that November during Intel’s AI Day, the Nervana Engine rematerialized to the public as Lake Crest, with first silicon due in 1H 2017. In that sense, the product has been delayed, although Intel noted that preliminary silicon exists today. Nevertheless, Intel commented that the NNP will be initially delivered to select customers, of which Facebook is one. In fact Intel has outright stated that they collaborated with Facebook in developing the NNP.

In terms of the bigger picture, while the past year has seen many announcements on neural network hardware accelerators, it is important to note that these processors and devices operate at different performance levels with different workloads and scenarios, and consequently machine learning performance consists of more than a single operation or metric. Accelerators may be on the sensor module or device itself (also known as on the ‘edge’) or farther away in the datacenters and the ‘cloud.’ Certain hardware may be training deep neural network models, a computationally intensive task, and/or running inference, applying these trained network models and putting them into practice. For Intel's NNP today, the coprocessor is aimed at the datacenter training market, competing with solutions like NVIDIA’s high-performance Volta-based Tesla products.

This segmentation can be seen in Intel’s own AI product stack, which includes Movidius hardware for computer vision and Altera for FPGAs, as well as Mobileye for automotive. The offerings are bisected again with the datacenter, which formally encompasses Xeon, Xeon Phi, Arria FPGAs, and now the NNP. For the NNP family, although the product announced today is a discrete accelerator, the in-development successor Knights Crest will be a bootable Xeon processor with integrated Nervana technology. While Intel referred to an internal NNP product roadmap and mentioned multiple NNP generations in the pipeline, it is not clear whether the next-generation NNP will be based on Knights Crest or an enhanced Lake Crest.
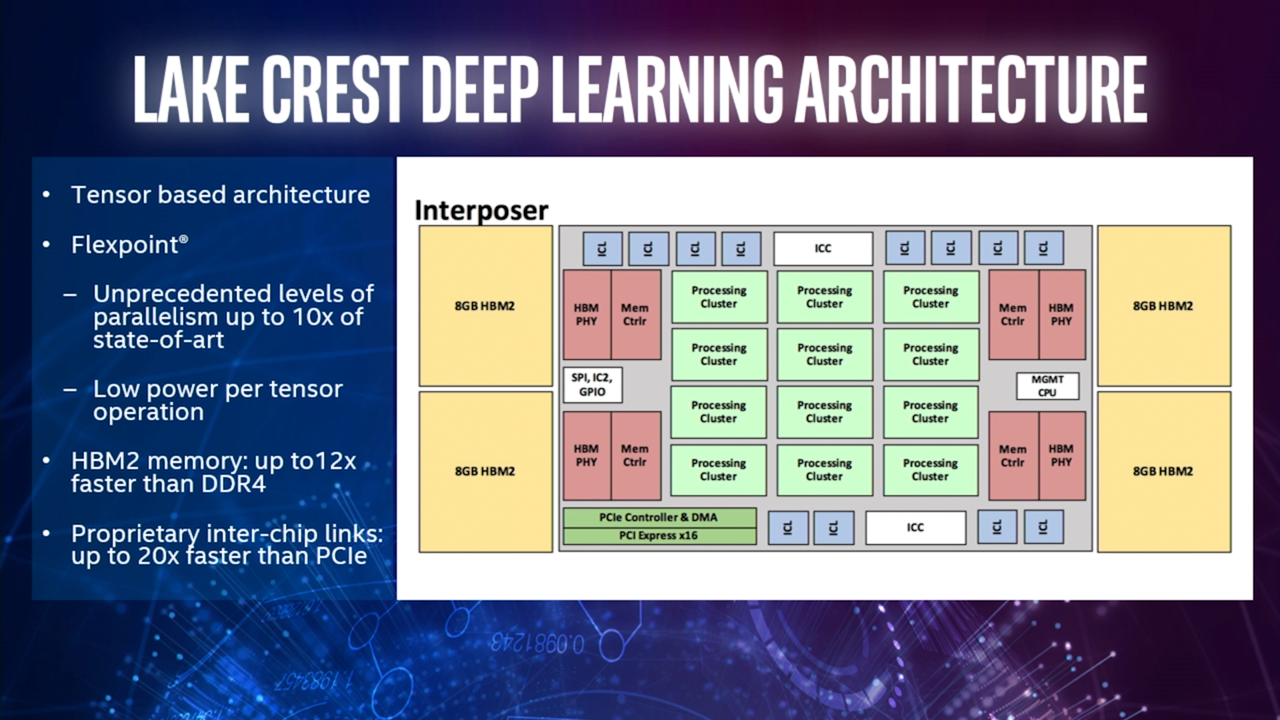
On the technical side of matters, the details remain the same from previous reports. Intel states that the NNP does not have a "standard cache hierarchy," however it does still have on-chip memory for performance reasons (I expect serving as registers and the like). Managing that memory is done by software, taking advantage of deep learning workloads where operations and memory accesses are mostly known before execution. Subsequently, the lack of cache controllers and coherency logic frees up die space. Otherwise for off-die memory, the processor has 32GB of HBM2 (4 8-Hi 1GB stacks) on the shared interposer, resulting in 8 terabits/s of access bandwidth.
Bringing to mind Google's TPU and NVIDIA's Tensor Cores, the NNP's tensor-based architecture is another example of how optimizations for deep learning workloads are reflected in the silicon. The NNP also utilizes Nervana’s numerical format called FlexPoint, described as in-between floating point and fixed point precision. Essentially, a shared exponent is used for blocks of data so that scalar computations can be implemented as fixed-point multiplications and additions. In turn, this allows the multiply-accumulate circuits to be shrunk and the design made denser, increasing the NNP’s parallelism while reducing power. And according to Intel, the cost of lower precision is mitigated by the inherent noise in inferencing.

The focus on parallelism continues with the NNP’s proprietary high-bandwidth low-latency chip-to-chip interconnect in the form of 12 bi-directional links. Additionally, the interconnect uses a fabric on the chip that includes the links, such that inter-ASIC and intra-ASIC communications are functionally identical "from a programming perspective." This permits the NNP to support true model parallelism as compute can be effectively distributed, taking advantage of the parallel nature of deep neural networks. Additional processors can combine to act as a single virtual processor with near linear speedup, where, for example, 8 ASICs could be combined in a torus configuration as shown above.
Presumably, the NNP will be fabricated on the TSMC 28nm process that Lake Crest was intended for; just after the acquisition, the Nervana CEO noted that production of the 28nm TSMC processors was still planned for Q1 2017. In any case, 16nm was explicitly mentioned as a future path when the Nervana Engine was first announced, and the CEO had also expressed interest in not only Intel’s 14nm processes, but also its 3D XPoint technology.
Source: Intel








25 Comments
View All Comments
aeolist - Wednesday, October 18, 2017 - link
Probably because the company making the ASIC had a lot of the design work done before the Intel buyout and moving it to a different fab entirely would not have been worthwhile.I'd assume 1-2 generations down the line they'll be fabbed by Intel directly.
woggs - Wednesday, October 18, 2017 - link
Intel factories are MONSTERS that churn out one thing in mega-volume at high margin. That cannot be interrupted by low-margin, low volume, experimental toys. If it takes off, this can change, but requires starting the architecture and design with the target being an intel FAB from day 1, which would likely be a hand-me-down from CPU or chipset first and later a purpose built factory. Long way off, if ever.Yojimbo - Saturday, October 21, 2017 - link
Intel knows what's at stake with AI. They didn't buy Nervana just to play with toys. NVIDIA is trading at a trailing 12 month stock price to earnings ratio (P/E) of over 50 when the industry average is under half that, largely because of the expected future opportunity of AI. Intel's P/E is 15.4, BTW. Intel's market capitalization (share price times number of shares outstanding) is $190 billion while NVIDIA's is $118 billion, even though Intel has much higher revenues. Intel's growth has been slow since the late 90s (their revenue has doubled in the 18 years since 1999, I think I read recently), and they desperately want to tap into the big growth opportunities in the market to stay relevant and hopefully to grow.What aeolist said was most likely correct. They will move to Intel's 14 nm process with the next generation of this chip. They would have had to delay the release of the chip if they tried to move it over to Intel's fabs after Intel's August 2016 purchase of Nervana Systems.
mode_13h - Wednesday, October 25, 2017 - link
You're forgetting that Intel actually runs a foundry business for 3rd party IP. So, they must be setup to do smaller runs than their x86 parts.FunBunny2 - Wednesday, October 18, 2017 - link
Big Brother's, or Dear Leader's, next Big Hammer.andrewaggb - Wednesday, October 18, 2017 - link
Well I'm definitely curious how fast it'll be and how much it'll cost. Having used nvidia graphics cards for training it's much faster than a cpu but still not what I'd call fast. And there's the CUDA problem... hopefully intel can integrate this with tensorflow, caffe, torch, opencv, etc.Yojimbo - Saturday, October 21, 2017 - link
In order to get the most speed, there need to be libraries well-optimized for a particular architecture, which takes a lot of work and benefits from intimate knowledge of the architecture, especially if you want speed boosts available to the public quickly..Intel will have to make specialized libraries to plug into the deep learning frameworks in order to take advantage of this chip, much like NVIDIA provides CUDA libraries optimized for their GPUs. With either this Nervana chip or with NVIDIA's GPUs using CUDA, I would think that if you want to switch hardware you are going to have to change libraries. Maybe Intel can write libraries that work well with both NNP and AVX-512, but are you really going to switch from NNP to AVX-512 for your training? Correct me if I'm wrong, but I'd guess no. Maybe you'd want to use an AMD GPU. Intel is not going to be targeting AMD GPUs with their libraries.
Besides, doesn't it seem likely that OpenCL libraries that are decent on both NVIDIA and AMD GPUs are more likely to exist than something that is decent on this NNP ASIC and something else?
Nate Oh - Monday, October 23, 2017 - link
Intel has Nervana's neon framework that supports CPU, MKL, and GPU backends, which now also utilizes Intel's Math Kernel Library (MKL). neon v2.1.0 actually includes AVX-512 support for SKL and KNM in DL workloads,[1] and their latest docs state support for Pascal, Maxwell, and Kepler[2]. neon's been kicking around for a bit, too, and I believe it (used) to have a reputation of being faster but less versatile/powerful than the other more popular frameworks.In the NNP announcements, there was no mention of neon but it seems logical that neon will support it, and that NNP may be custom-designed for it.
[1] https://www.intelnervana.com/neon-2-1/
[2] http://neon.nervanasys.com/docs/latest/overview.ht...
Yojimbo - Thursday, October 26, 2017 - link
Yes, Nervana has the expertise to make such a framework. But my point was the following. The original poster said "And there's the CUDA problem..." I don't understand how switching from a general purpose architecture to an ASIC solves "the CUDA problem", which I assumed to mean "the amount that one is locked into using the current architecture of choice".Using an NNP or a GPU, one will still be tied into the libraries one links to the same amount, and be able to take advantage of the reusable part from the back end framework the same amount. So unless by "the CUDA problem" he means just the existence of CUDA itself, and has in mind a "final solution", what exactly is the problem that the use of Intel's NNP solves?
mode_13h - Wednesday, October 25, 2017 - link
"Intel will have to make specialized libraries to plug into the deep learning frameworks in order to take advantage of this chip"The big players (Intel, AMD, and Nvidia) already have optimized backends for popular frameworks like Caffe, Caffe2, TensorFlow, etc. The smaller players (Movidius, for one) have proprietary frameworks that let you import models from the standard frameworks.