Intel Optane SSD DC P4800X 750GB Hands-On Review
by Billy Tallis on November 9, 2017 12:00 PM ESTFine Tuning Performance
The Intel Optane SSD DC P4800X 750GB is expected to perform the same as the 375GB model - and the same as the consumer Optane SSD 900p for that matter. Rather than simply repeat the same tests those drives have already been been subjected to, this review seeks to dig deeper into the performance characteristics of the Optane SSD and explore what it takes to extract the full performance of the drive. There are quite a few esoteric system settings that can have an impact, since a microsecond gained or lost matters more to an Optane SSD than to a flash-based drive.
Multiple Queues
One of the most important features of NVMe that allows for higher performance than the AHCI protocol used for SATA is support for multiple queues of I/O commands. The NVMe protocol allows for up to 64k queues each with up to 64k pending commands, but current hardware cannot actually reach those limits.
Intel's first-generation NVMe controller (used in the P3x00 drives and the SSD 750) supports a total of 32 queues in hardware: the admin queue, and 31 I/O queues. For the P4x00 generation NAND SSDs, the new controller supports 128 queues. However, the Optane SSD controller still only supports 32 queues, because that's more than enough to reach the full performance of the drive even if each queue only contains one command at a time. The Microsemi controller used by the Micron 9100 MAX supports 128 queues, the same as Intel's latest flash SSDs.
Achieving the highest and most consistent performance requires each CPU core that is performing I/O to have its own NVMe queue assigned to it. When multiple cores share the same queue, the synchronization overhead can increase latency and reduce performance consistency. The Linux NVMe driver currently spreads the NVMe queue assignments evenly across all CPU cores. On our server with 36 physical cores, this means that the Intel SSDs with only 31 I/O queues require several cores on each socket to share queues. Rather than patch the kernel to allow for manual queue assignment, the testbed was simply configured to only enable 16 our of 18 cores on each CPU. This caused the OS to assign one queue exclusively per core on CPU #2 that the SSDs are attached to (two cores on CPU #1 share a queue). None of the storage benchmarks in this review would benefit significantly from having two extra cores available, and 16 cores is more than enough to saturate any of these SSDs.
Sector Size
NVMe SSDs are capable of supporting different sector sizes. Everything defaults to the 512-byte sector size for the sake of backwards compatibility, but enterprise NVMe SSDs and many client NVMe SSDs also support 4kB sectors. Many enterprise SSDs also support sector formats that include between 8 and 128 extra bytes of metadata to support end to end data protection. Just as with 4k sector sizes on hard drives, using 4kB sectors on NVMe SSDs can slightly reduce overhead.
Switching between sector sizes is accomplished using the NVMe FORMAT command, which is also used for secure erase operations. On most flash-based SSDs, a NVMe FORMAT command takes only a few seconds. On Optane devices, the drive actually performs a low-level format that touches substantially all of the 3D XPoint memory and takes about as long as filling up the drive sequentially. With the 750GB Optane SSD DC P4800X, a NVMe FORMAT command takes several minutes and requires overriding the default command timeout settings. (Coincidentally, a kernel patch to fix this issue showed up on the linux-nvme mailing list while I was testing the drive.)
Interrupts vs Polling
With the performance offered by Optane SSDs, the CPU can become a bottleneck even when running synthetic storage benchmarks. The latency of 3D XPoint memory is low enough that things like CPU context switches, interrupt handler latency and inter-core synchronization can significantly affect results. We've already covered how the test hardware was configured for high performance, but there's further room to fine tune the software configuration.
There are two main ways for the operating system to find out when the SSD has completed a command. The normal method and the best general-purpose choice is for the OS to wait for the drive to signal an interrupt. Upon receipt of an interrupt, the OS will check the relevant NVMe completion queue and pass along the result to the application. The alternative is polling: while waiting for an I/O operation to complete, the CPU constantly checks the status of the completion queue. This wastes a ton of CPU time and is usually only worthwhile when the CPU has nothing better to do and needs the result as soon as possible. However, polling does shave one or two microseconds off the SSD's latency. When CPU power management is enabled, polling can also keep the processor awake when it is awaiting completion of an I/O command, potentially leading to more significant latency and throughput advantages relative to interrupt-driven I/O.
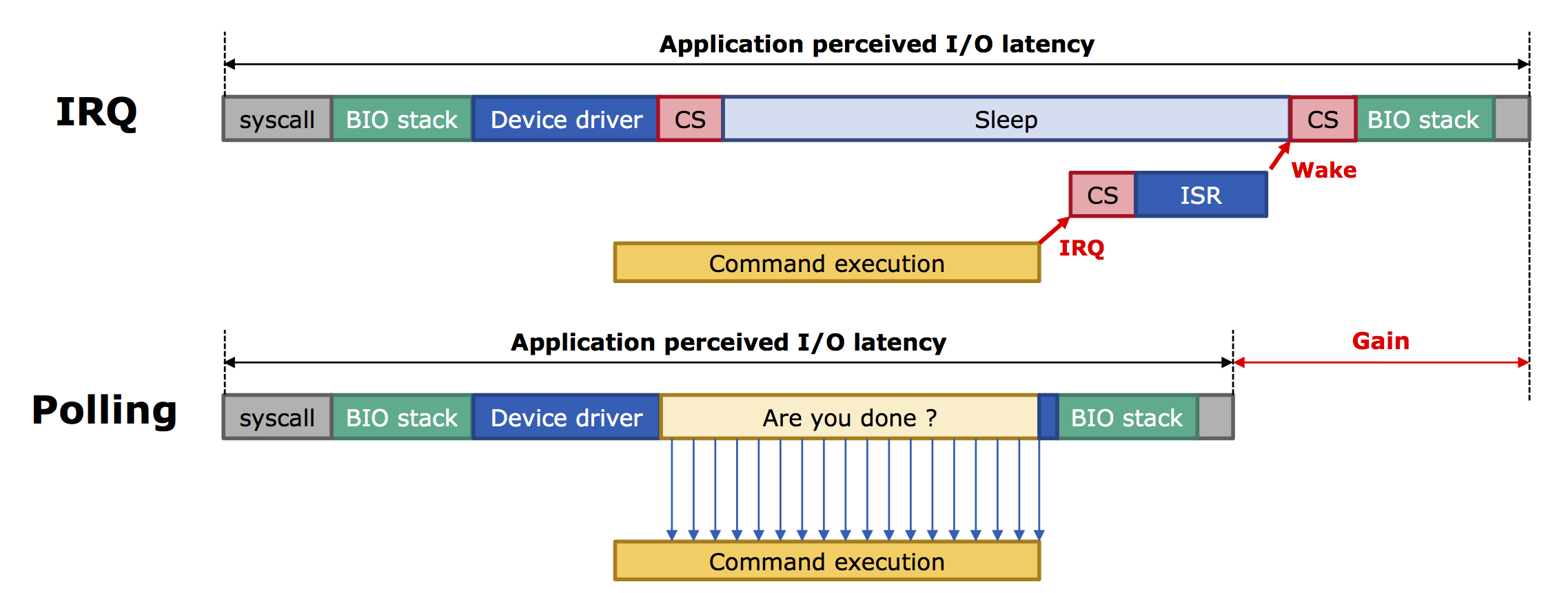 (source: Western Digital)
(source: Western Digital)
Recent Linux kernel versions support a hybrid polling mode, where the OS will estimate how long to sleep or run other tasks before starting to poll for completed I/O. This provides a reasonable balance between storage latency and CPU overhead, at least where storage performance is still a high priority. For this review, all drives were set to use the hybrid polling mode. However, polling is by default not used for most ordinary I/O:
APIs
At the application layer, there are several ways to accomplish I/O. Most methods (like the simple and ancient read() and write() system calls) are synchronous, making a single request at a time and blocking: the thread waits until the I/O operation is done before continuing. When these APIs are used, the only way an application can produce a queue depth greater than 1 is to have multiple threads performing I/O simultaneously.
Most operating systems also have APIs for asynchronous I/O, where the application sends requests to the OS but the application chooses when to check if those requests have completed. This allows a single thread to generate queue depths greater than one. Both asynchronous I/O and multithreaded synchronous I/O allow for high queue depths to be generated by a single application, but they are also more complex to use than simple single-threaded synchronous I/O.
Linux has also recently gained a new set of system calls for performing synchronous I/O and optionally flagging the read or write operation as high priority. This signals the OS to poll for completion of the I/O operations, reducing latency at the expense of burning CPU time instead of idling. These preadv2() and pwritev2() system calls are close to being a drop-in replacement for simple read() and write() system calls, but in most programming languages there's a standard library providing abstracted I/O interfaces, so switching an application to use the new system calls and flag some or all I/Os as high priority is not trivial. Currently, the preadv2() and pwritev2() system calls are the only Linux storage API that can trigger the kernel to use polling instead of waiting for an interrupt.
For application developers seeking to squeeze every last microsecond of latency out of their I/O, Intel created the Storage Performance Development Kit (SPDK), an offshoot of their Data Plane Development Kit (DPDK) for networking. The projects allow applications to directly access storage or network devices without going through the OS kernel's drivers. SPDK is an open-source library that is not tied to Intel hardware and can be used on Linux or FreeBSD to access any vendor's NVMe SSD with its polled mode driver. Using SPDK requires more invasive application changes than any of the above mentioned APIs, but it is also the fastest and most direct way for an application to interact with NVMe SSDs. Due to time constraints, this review does not include benchmarks with SPDK.
I/O Scheduler
Most operating systems include some form of I/O scheduler to determine which operations to send to the disk first when multiple processes need to access the disk. Linux includes several I/O schedulers with various strengths and weaknesses on different workloads. For real-world use, the proper choice of I/O scheduler can make a significant difference in overall performance. However, for benchmarking, I/O schedulers can interfere with attempts to test at specific queue depths and with specific I/O ordering. For this review, all SSDs were set to use the Linux no-op I/O scheduler that does no reordering or throttling, and consequently also has the least CPU overhead.








58 Comments
View All Comments
woggs - Thursday, November 9, 2017 - link
This drive is PCIe 3, so nothing will change because it will link as gen 3. Will need a whole new drive...MajGenRelativity - Thursday, November 9, 2017 - link
I believe OP was talking about a drive that was identical to this in every way, but supporting PCIe 4woggs - Thursday, November 9, 2017 - link
And SSD is a system and would neither over nor under engineer any one piece significantly. So, altering one piece should not be expected to suddenly pop to some much higher performance. Will require a whole new drive.Hurr Durr - Thursday, November 9, 2017 - link
Where is requisite ddriver hysterics session about hypetane?Reflex - Thursday, November 9, 2017 - link
It appears the hysteric is gone at least for the time being. As a result the discussion has been far easier to read.Great drive, can't wait to see future generations where presumably they will increase density and reduce power consumption...
woggs - Thursday, November 9, 2017 - link
Yep!woggs - Thursday, November 9, 2017 - link
(on both counts)Hixbot - Thursday, November 9, 2017 - link
He must be taking the day off. I'm sure he'll flood the comments tomorrow.Makaveli - Thursday, November 9, 2017 - link
If you say his name 3 times he will show up....DON'T DO IT!
abhaxus - Thursday, November 9, 2017 - link
I came here looking for him, and was disappointed.