Analyzing Falkor’s Microarchitecture: A Deep Dive into Qualcomm’s Centriq 2400 for Windows Server and Linux
by Ian Cutress on August 20, 2017 11:00 AM EST- Posted in
- CPUs
- Qualcomm
- Enterprise
- SoCs
- Enterprise CPUs
- ARMv8
- Centriq
- Centriq 2400
The SoC: 48 Falcor Cores, DDR4, PCIe
Two decades ago, when processors were a single core with external memory controllers, external caches, and external IO, routing was comparatively easier than what we have today. Now we have many core systems, multiple cache levels of different varieties, more IO than we can shake a stick at, and it all has to communicate with each other in a low power, low latency and high bandwidth way using a variety of interfaces. For the Centriq 2400, Qualcomm is implementing a number of enterprise requirements as well as integrating its own developed fabric.
For those that have been following our Intel/AMD coverage of late, we discussed how internal coherent fabrics are changing: Intel has moved from a ring-bus topology to a per-core networking mesh, and AMD uses its scalable Infinity Fabric within a die, between dies, between sockets, and from GPUs to memory. In the mobile space, coherent fabrics like ARMs CCI/CCN are typically all the rage, and ARM allows its partners to modify and tune those IPs as they need to (and most do). Rather than using off-the-shelf IP, Qualcomm has stated that its new interconnect is homegrown.
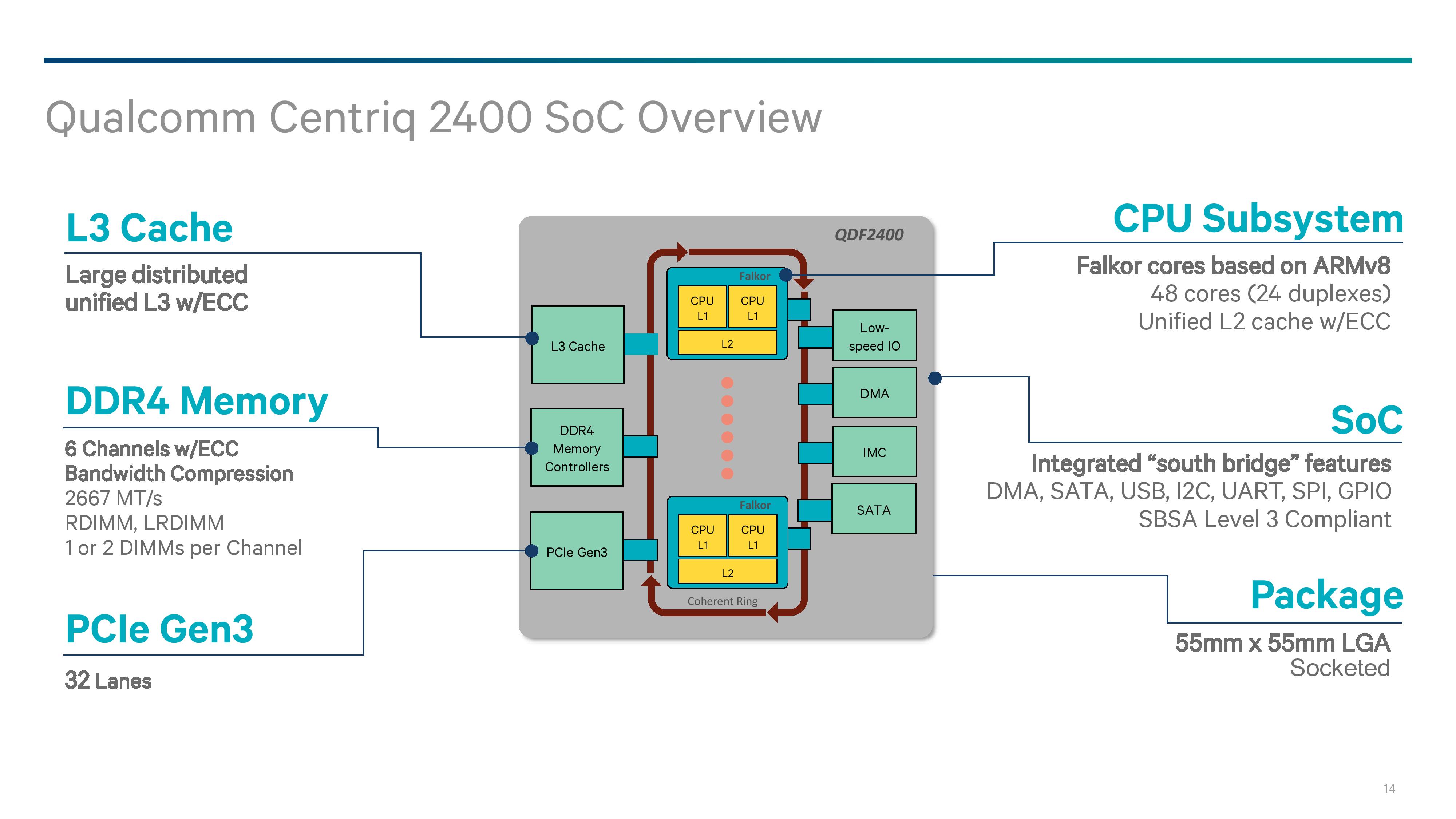
The Qualcomm System Bus (QSB) is a proprietary protocol based, bidirectional segmented ring bus. While Qualcomm shows a ring bus in the image above, we are told that the segmented ring bus might not exactly look like a ring inside the chip – by creating a segmented core-to-core design, it means the cores might not be in a ring at all, with some elements sprouting from off shoots and cores having more than one direction to travel. If Qualcomm were to share a false-color die shot, this would likely be visible. The QSB also allows for multicast on read as well as shortest path routing, which again sounds more like a mesh based networking implementation. Qualcomm quotes a >250GB/s aggregate bandwidth for the QSB.
On the Fabric is everything the system needs: cores, cache, memory, PCIe and IO.
The Centriq family will implement a pair of Falkor cores into a Falkor ‘Duplex’, where each core with have a private L1 cache and a shared L2 cache with ECC. We’ll cover the Falkor design in the next few pages.
For the L3 cache, Qualcomm has not quoted a size but has said that it will scale with the number of cores on the chip. In the above slide it states that it is a distributed unified cache, which can be confusing. Ultimately the cache is fully accessible from all cores, unless a QoS policy is in play, but the cache is likely segmented to allow for the relevant QoS policy tags to bind certain regions to certain cores/VMs. Despite it saying unified, it means that there will be partitions of the L3 around the QSB interconnect. The L3 will be with ECC as well.
Memory controllers are also accessed from the QSB interconnect, with the Centriq 2400 supporting six memory channels of up to DDR4-2667 at up to 2 DIMMs per channel. Support will include RDIMM and LRDIMM, which would suggest up to 1.5TB of LRDIMM support per socket using 128GB LRDIMMs, similar to Intel’s premium memory offerings.
Connectivity comes via 32 lanes of PCIe 3.0, which falls below that offered by Intel (32-44, fewer when chipset level Quick Assist or 10GbE is being used), AMD (128 PCIe in 1P or 2P), X-Gene 3 (42), or Cavium. We probed Qualcomm on features such as NVMe, NVMe RAID, and fall-over support, although in our limited time briefing there was not time to cover it – we might hear more while we are at Hot Chips this week.
Qualcomm has designed the chip as a true SoC such that it doesn’t need a chipset. We’ve confirmed that this is on-die connectivity, rather than via a multi-chip package add-in. The information we have states that the chip will support the usual array of SATA, USB, I2C, UART, GPIO and DMA, although how much of anything has not been stated.








41 Comments
View All Comments
dennisAustin - Thursday, August 31, 2017 - link
Interesting...when I first read about it nearly a half-decade ago - even Intel and AMD have shorter design cycles _and_ x86 architecture is orders of magnitude more complex than ARM's. The target market for "Lunesta" or "Centriq?" is the data center, not angry birds, Spec, or HPC. ARMs RAS specification is in its infancy at best and likely scantly implemented in Lunesta.It was a great concept - but the window of opportunity has long sense passed - 5ish years in and likely $1B+ invested, it's a non starter. My advice - drop the IBM managers, re-hire managers with technical backgrounds -- remember this product is being driven by the same guy who said "who needs 64 bits?" -- unfortunate