Retesting AMD Ryzen Threadripper’s Game Mode: Halving Cores for More Performance
by Ian Cutress on August 17, 2017 12:01 PM ESTConclusions
In this mini-test, we compared AMD’s Game Mode as originally envisioned by AMD. Game Mode sits as an extra option in the AMD Ryzen Master software, compared to Creator Mode which is enabled by default. Game Mode does two things: firstly, it adjusts the memory configuration. Rather than seeing the DRAM as one uniform block of memory with an ‘average’ latency, the system splits the memory into near memory closest to the active CPU, and far memory for DRAM connected via the other silicon die. The second thing that Game Mode does is disable the cores on one of the silicon dies, but retains the PCIe lanes, IO, and DRAM support. This disables cross-die thread migration, offers faster memory for applications that need it, and aims to lower the latency of the cores used for gaming by simplifying the layout. The downside of Game Mode is raw performance when peak CPU is needed: by disabling half the cores, any throughput limited task is going to be cut by losing half of the throughput resources. The argument here is that Game mode is designed for games, which rarely use above 8 cores, while optimizing the memory latency and PCIe connectivity.
A simpler way to imagine Game Mode is this: enabling Game Mode brings the top tier Threadripper 1950X down to the level of a Ryzen 7 processor for core count at around the same frequency, but still gets the benefits of quad channel memory and all 60 PCIe lanes for add-in cards. In this mode, the CPU will preferentially use the lower latency memory available first, attempting to ensure a better immediate experience. You end up with an uber-Ryzen 7 for connectivity.

AMD states that a Threadripper in Game Mode will have lower latency than a Ryzen 7, as well as a higher boost and larger boost window (up to 4 cores rather than 2)
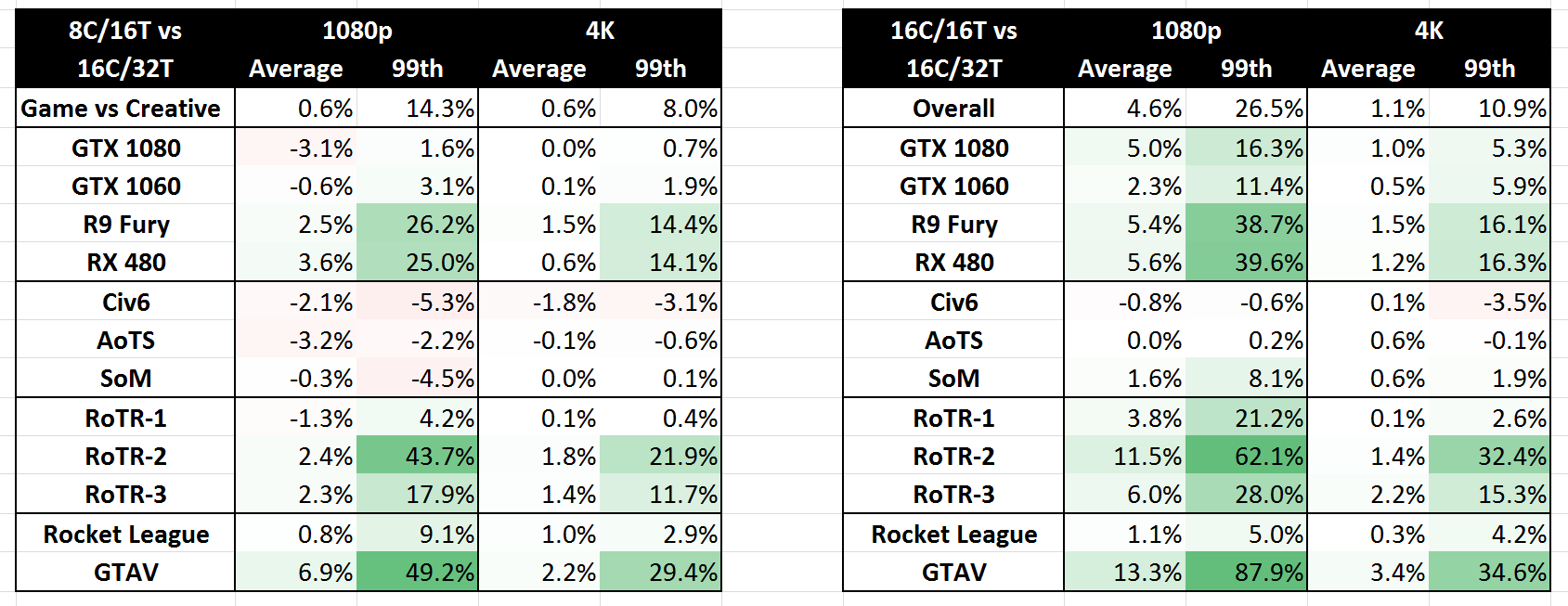
In our testing, we did the full gamut of CPU and CPU Gaming tests, at 1080p and 4K with Game Mode enabled.
On the CPU results, they were perhaps to be expected: single threaded tests with Game Mode enabled performed similar to Ryzen 7 and the 1950X, but multithreaded tests were almost halved to the 1950X, and slightly slower than the Ryzen 7 1800X due to the lower all-core turbo.
The CPU gaming tests were instead a mixed bunch. Any performance difference from Game Mode over Creator Mode was highly dependant on the game, on the graphics card, and on the resolution. Overall, the results could be placed into buckets:
- Noted minor losses in Civilization 6, Ashes of the Singularity and Shadow of Mordor
- Minor loss to minor gain on GTX 1080 and GTX 1060 overall in all games
- Minor gain for AMD cards on Average Frame Rates, particularly RoTR and GTA
- Sizeable (10-25%) gain for AMD cards on 99th Percentile Frame Rates, particularly RoTR and GTA
- Gains are more noticable for 1080p gaming than 4K gaming
- Most gains across the board are on 99th Percentile data
Which leads to the following conclusions
- No real benefit on GTX 1080 or GTX 1060, stay in Creator Mode
- Benefits for Rise of the Tomb Raider, Rocket League and GTA
- Benefit more at 1080p, but still gains at 4K
The pros and cons of enabling Game Mode are meant to be along the lines of faster and lower latency gaming, at the expense of raw compute power. The fact that it requires a reboot to switch between Creator Mode and Game Mode is a main detractor - if it were a simple in-OS switch, then it could be enabled for specific titles on specific graphics cards just before the game is launched. This will not ever be possible, due to how PCs decide what resources are available when. That being said however, perhaps AMD has missed a trick here.
Could AMD have Implemented Game Mode Differently?
By virtue of misinterpreting AMD's slide deck, and testing a bunch of data with SMT disabled instead, we have an interesting avenue as to how users might do something akin to Game Mode but not specifically AMD's game mode. This also leads to the question if AMD implemented and labeled the Game Mode environment in the right way.
By enabling NUMA and disabling SMT, the 16C/32T chip moves down to 16C/16T. It still has 16 full cores, but has to deal with communication across the two eight-core silicon dies. Nonetheless it still satisfies the need for cores to access the lowest latency memory near to that specific core, as well as enabling certain games that need fewer total threads to actually work. It should, by the description alone, enable the 'legacy' part of legacy gaming.
The underlying performance analysis between the two modes becomes this:
When in 16C/16T mode, performance in CPU benchmarks was higher than in 8C/16T mode.
When in 16C/16T mode, performance in CPU gaming benchmarks was higher than in 8C/16T mode.
Some of the suggestions from comparing AMD's defined 8C/16T Game Mode for CPU gaming actually change when in 16C/16T mode: games that saw slight regressions with 8 cores became neutral at 16C or even had slight improvements, particularly at 1080p.
One of the main detractors to the 8C/16T mode is that it requires a full restart in order to enable it. Disabling SMT could theoretically be done at the OS level before certain games come in to play. If the OS is able to determine which core IDs are associated to standard threads and which ones would be hyperthreads, it is perhaps possible for the OS just to refuse to dispatch threads in flight to the hyperthreads, allowing only one thread per core. (There's a small matter of statically shared resources to deal with as well.) The mobile world deals with thread migration between fast cores and slow cores every day, and some cores can be hotplug disabled on the fly. One could postulate that Windows could do something similar with the equivalent of hyperthreads.
Would this issue need to be solved by Windows, or by AMD? I suspect a combination of both, really.
Update:
Robert Hallock on AMD's Threadripper webcast has stated that Windows Scheduler is not capable of specifically zeroing out a full die to have the same effect. The UMA/NUMA implementation can be managed with Windows Scheduler to assign threads to where the data is (or assign data to where the threads are), but as far as fully disabling a die in the OS requires a restart.








104 Comments
View All Comments
Lieutenant Tofu - Friday, August 18, 2017 - link
"... we get an interesting metric where the 1950X still comes out on top due to the core counts, but because the 1920X has fewer cores per CCX, it actually falls behind the 1950X in Game Mode and the 1800X despite having more cores. "Would you mind elaborating on this? How does the proportion of cores per CCX affect performance?
JasonMZW20 - Sunday, August 20, 2017 - link
The only thing I can think of is CCX cache locality. Given a choice, you want more cores per CCX to keep data on that CCX rather than using cross-communication between CCXes through L2/L3. Once you have to communicate with the other CCX, you automatically incur a higher average latency penalty, which in some cases, is also a performance penalty (esp. if data keeps moving between the two CCXes).Lieutenant Tofu - Friday, August 18, 2017 - link
On the compile test (prev page):"... we get an interesting metric where the 1950X still comes out on top due to the core counts, but because the 1920X has fewer cores per CCX, it actually falls behind the 1950X in Game Mode and the 1800X despite having more cores. "
Would you mind elaborating on this? How does the proportion of cores per CCX affect performance?
rhoades-brown - Friday, August 18, 2017 - link
This gaming mode intrigues me greatly- the article states that the PCIe lanes and memory controller is still enabled, but the cores are turned off as shown in this diagram:http://images.anandtech.com/doci/11697/kevin_lensi...
If these are two complete processors on one package (as the diagrams and photos show), what impact does having gaming mode enabled and a PCIe device connected to the PCIe controller on the 'inactive' side? The NUMA memory latency seems to be about 1.35 surely this must affect the PCIe devices too- further how much bandwidth is there between the two processors? Opteron processors use HyperTransport for communication, do these do the same?
I work in the server world and am used to NUMA systems- for two separate processor packages in a 2 socket system, cross-node memory access times is normally 1.6x that of local memory access. For ESXi hosts, we also have particular PCIe slots that we place hardware in, to ensure that the different controllers are spread between PCIe controllers ensuring the highest level of availability due to hardware issue and peek performance (we are talking HBAs, Ethernet adapters, CNAs here). Although, hardware reliability is not a problem in the same way in a Threadripper environment, performance could well be.
I am intrigued to understand how this works in practice. I am considering building one of these systems out for my own home server environment- I yet to see any virtualisation benchmarks.
versesuvius - Friday, August 18, 2017 - link
So, what is a "Game"? Uses DirectX? Makes people act stupidly? Is not capable of using what there is? Makes available hardware a hindrance to smooth computing? Looks like a lot of other apps (that are not "Game") can benefit from this "Gaming Mode".msroadkill612 - Friday, August 18, 2017 - link
A shame no Vega GPU in the mix :(It may have revealed interesting synergies between sibling ryzen & vega processors as a bonus.
BrokenCrayons - Friday, August 18, 2017 - link
The only interesting synergy you'd get from a Threadripper + Vega setup is an absurdly high electrical demand and an angry power supply. Nothing makes less sense than throwing a 180W CPU plus a 295W GPU at a job that can be done with a 95W CPU and a 180W GPU just as well in all but a few many-threaded workloads (nevermind the cost savings on the CPU for buying Ryzen 7 or a Core i7).versesuvius - Friday, August 18, 2017 - link
I am not sure if I am getting it right, but apparently if the L3 cache on the first Zen core is full and the core has to go to the second core's L3 cache there is an increase in latency. But if the second core is power gated and does not take any calls, then the increase in latency is reduced. Is it logical to say that the first core has to clear it with the second core before it accesses the second core's cache and if the second core is out it does not have to and that checking with the second core does not take place and so latency is reduced? Moving on if the data is not in the second core's cache then the first core has to go to DRAM accessing which supposedly does not need clearance from the second core. Or does it always need to check first with the second core and then access even the DRAM?BlackenedPies - Friday, August 18, 2017 - link
Would Threadripper be bottlenecked by dual channel RAM due to uneven memory access between dies? Is the optimal 2 DIMM setup one per die channel or two on one die?Fisko - Saturday, August 19, 2017 - link
Anyone working on daily basis just to view and comment pdf won't use acrobat DC. Exception can be using OCR for pdf. Pdfxchange viewer uses more threads and opens pdf files much faster than Adobe DC. I regularly open files from 25 to 80 mb of CAD pdf files and difference is enormous.