The AMD Radeon RX Vega 64 & RX Vega 56 Review: Vega Burning Bright
by Ryan Smith & Nate Oh on August 14, 2017 9:00 AM ESTRapid Packed Math: Fast FP16 Comes to Consumer Cards (& INT16 Too!)
Arguably AMD’s marquee feature from a compute standpoint for Vega is Rapid Packed Math. Which is AMD’s name for packing two FP16 operations inside of a single FP32 operation in a vec2 style. This is similar to what NVIDIA has done with their high-end Pascal GP100 GPU (and Tegra X1 SoC), which allows for potentially massive improvements in FP16 throughput. If a pair of instructions are compatible – and by compatible, vendors usually mean instruction-type identical – then those instructions can be packed together on a single FP32 ALU, increasing the number of lower-precision operations that can be performed in a single clock cycle. This is an extension of AMD’s FP16 support in GCN 3 & GCN 4, where the company supported FP16 data types for the memory/register space savings, but FP16 operations themselves were processed no faster than FP32 operations.

The purpose of integrating fast FP16 and INT16 math is all about power efficiency. Processing data at a higher precision than is necessary unnecessarily burns power, as the extra work required for the increased precision accomplishes nothing of value. In this respect fast FP16 math is another step in GPU designs becoming increasingly min-maxed; the ceiling for GPU performance is power consumption, so the more energy efficient a GPU can be, the more performant it can be.
Taking advantage of this feature, in turn, requires several things. It requires API support and it requires compiler support, but above all it requires code that explicitly asks for FP16 data types. The reason why that matters is two-fold: virtually no existing programs use FP16s, and not everything that is FP32 is suitable for FP16. In the compute world especially, precisions are picked for a reason, and compute users can be quite fussy on the matter. Which is why fast FP64-capable GPUs are a whole market unto themselves. That said, there are whole categories of compute tasks where the high precision isn’t necessary; deep learning is the poster child right now, and for Vega Instinct AMD is practically banking on it.
As for gaming, the situation is more complex still. While FP16 operations can be used for games (and in fact are somewhat common in the mobile space), in the PC space they are virtually never used. When PC GPUs made the jump to unified shaders in 2006/2007, the decision was made to do everything at FP32 since that’s what vertex shaders typically required to begin with, and it’s only recently that anyone has bothered to look back. So while there is some long-term potential here for Vega’s fast FP16 math to become relevant for gaming, at the moment it doesn’t do much outside of a couple of benchmarks and some AMD developer relations enhanced software. Vega will, for the present, live and die in the gaming space primarily based on its FP32 performance.
The biggest obstacle for AMD here in the long-term is in fact NVIDIA. NVIDIA also supports native FP16 operations, however unlike AMD, they restrict it to their dedicated compute GPUs (GP100 & GV100). GP104, by comparison, offers a painful 1/64th native FP16 rate, making it just useful enough for compatibility/development purposes, but not fast enough for real-world use. So for AMD there’s a real risk of developers not bothering with FP16 support when 70% of all GPUs sold similarly don’t support it. It will be an uphill battle, but one that can significantly improve AMD’s performance if they can win it, and even more so if NVIDIA chooses not to budge on their position.

Though overall it’s important to keep in mind here that even in the best case scenario, only some operations in a game are suitable for FP16. So while FP16 execution is twice as fast as FP32 execution on paper specifically for a compute task, the percentage of such calculations in a game will be lower. In AMD’s own slide deck, they illustrate this, pointing out that using 16-bit functions makes specific rendering steps of 3DMark Serra 20-25% faster, and those are just parts of a whole.
Moving on, AMD is also offering limited native 8-bit support via a pair of specific instructions. On Vega the Quad Sum of Absolute Differences (QSAD) and its masked variant can be executed on Vega in a highly packed form using 8-bit integers. SADs are a rather common image processing operation, and are particularly relevant for AMD’s Instinct efforts since they are used in image recognition (a major deep learning task).

Finally, let’s talk about API support for FP16 operations. The situation isn’t crystal-clear across the board, but for certain types of programs, it’s possible to use native FP16 operations right now.
Surprisingly, native FP16 operations are not currently exposed to OpenCL, according to AIDA64. So within a traditional AMD compute context, it doesn’t appear to be possible to use them. This obviously is not planned to remain this way, and while AMD hasn’t been able to offer more details by press time, I expect that they’ll expose FP16 operations under OpenCL (and ROCm) soon enough.
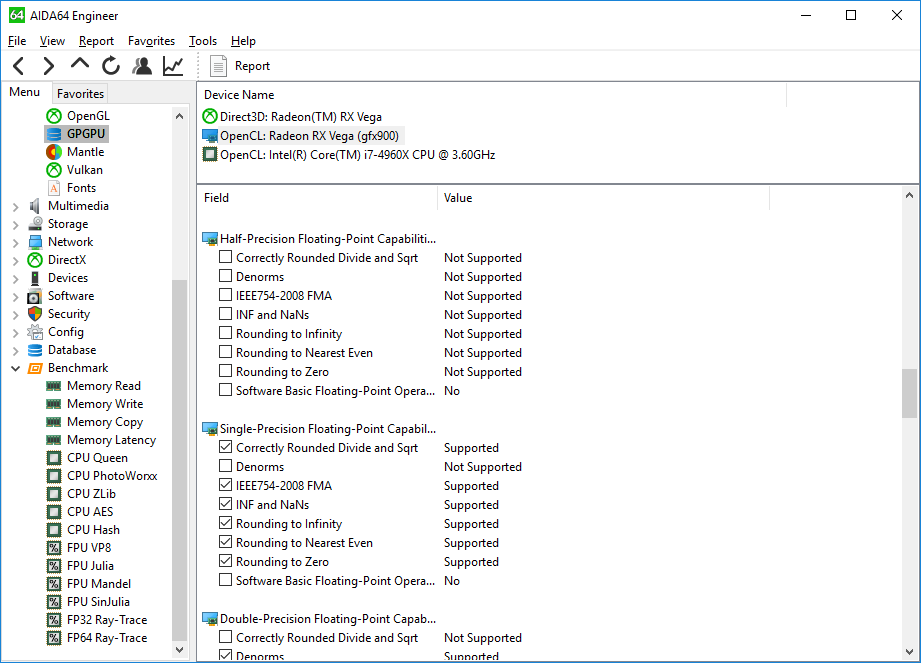
Meanwhile, High Level Shader Model 5.x, which is used in DirectX 11 and 12, does support native FP16 operations. And so does Vulkan, for that matter. So it is possible to use FP16 right now, even in games. Running SiSoftware’s Sandra GP GPU benchmark with a DX compute shader shows a clear performance advantage, albeit not a complete 2x advantage, with the switch to FP16 improving compute throughput by 70%.

However based on some other testing, I suspect that native FP16 support may only be enabled/working for compute shaders at this time, and not for pixel shaders. In which case AMD may still have some work to do. But for developers, the message is clear: you can take advantage of fast FP16 performance today.








213 Comments
View All Comments