The AMD Ryzen Threadripper 1950X and 1920X Review: CPUs on Steroids
by Ian Cutress on August 10, 2017 9:00 AM ESTCreator Mode and Game Mode
*This page was updated on 8/17. A subsequent article with new information has been posted.
Due to the difference in memory latency between the two pairs of memory channels, AMD is implementing a ‘mode’ strategy for users to select depending on their workflow. The two modes are called Creator Mode (default), and Game Mode, and control two switches in order to adjust the performance of the system.
The two switches are:
- Legacy Compatibility Mode, on or off (off by default)
- Memory Mode: UMA vs NUMA (UMA by default)
The first switch disables the cores in one fo the silicon dies, but retains access to the DRAM channels and PCIe lanes. When the LCM switch is off, each core can handle two threads and the 16-core chip now has a total of 32 threads. When enabled, the system cuts half the cores, leaving 8 cores and 16 threads. This switch is primarily for compatibility purposes, as certain games (like DiRT) cannot work with more than 20 threads in a system. By reducing the total number of threads, these programs will be able to run. Turning the cores in one die off also alleviates some potential pressure in the core microarchitecture for cross communication.
The second switch, Memory Mode, puts the system into a unified memory architecture (UMA) or a non-unified memory architecture (NUMA) mode. Under the default setting, unified, the memory and CPU cores are seen as one massive block to the system, with maximum bandwidth and an average latency between the two. This makes it simple for code to understand, although the actual latency for a single instruction will be a good +20% faster or slower than the average, depending on which memory bank it is coming from.

NUMA still gives the system the full memory, but splits the memory and cores into into two NUMA banks depending on which pair of memory channels is nearest the core that needs the memory. The system will keep the data for a core as near to it as possible, giving the lowest latency. For a single core, that means it will fill up the memory nearest to it first at half the total bandwidth but a low latency, then the other half of the memory at the same half bandwidth at a higher latency. This mode is designed for latency sensitive workloads that rely on the lower latency removing a bottleneck in the workflow. For some code this matters, as well as some games – low latency can affect averages or 99th percentiles for game benchmarks.
The confusing thing about this switch is that AMD is calling it ‘Memory Access Mode’ in their documents, and labeling the two options as Local and Distributed. This is easier to understand than the SMT switch, in that the Local setting focuses on the latency local to the core (NUMA), and the Distributed setting focuses on the bandwidth to the core (UMA), with Distributed being default.
- When Memory Access Mode is Local, NUMA is enabled (Latency)
- When Memory Access Mode is Distributed, UMA is enabled (Bandwidth, default)
So with that in mind, there are four ways to arrange these two switches. AMD has given two of these configurations specific names to help users depending on how they use their system: Creator Mode is designed to give as many threads as possible and as much memory bandwidth as possible. Game Mode is designed to optimize for latency and compatibility, to drive game frame rates.
| AMD Threadripper Options | |||||
| Words That Make Sense | Marketing Spiel | ||||
| Ryzen Master Profile |
Two Dies or One Die |
Memory Mode |
Legacy Compatibility Mode |
Memory Access Mode |
|
| Creator Mode | Two | UMA | Off | Distributed | |
| - | Two | NUMA | Off | Local | |
| - | One | UMA | On | Distributed | |
| Game Mode | One | NUMA | On | Local | |
There are two ways to select these modes, although this is also a confusing element to this situation.

The way I would normally adjust these settings is through the BIOS, however the BIOS settings do not explicitly state ‘Creator Mode’ and ‘Game Mode’. They should give immediate access for the Memory Mode, where ASUS has used the Memory Access naming for Local and Distributed, not NUMA and UMA. For the Legacy Compatibility Mode, users will have to dive several screens down into the Zen options and manually switch off eight of the cores, if the setting is going to end up being visible to the user. This makes Ryzen Master the easiest way to implement Game Mode.
While we were testing Threadripper, AMD updated Ryzen Master several times to account for the latest updates, so chances are that by the time you are reading this, things might have changed again. But the crux is that Creator Mode and Game Mode are not separate settings here either. Instead, AMD is labelling these as ‘profiles’. Users can select the Creator Mode profile or the Game Mode profile, and within those profiles, the two switches mentioned above (labelled as Legacy Compatibility Mode and Memory Access Mode) will be switched as required.
Cache Performance
As an academic exercise, Creator Mode and Game Mode make sense depending on the workflow. If you don’t need the threads and want the latency bump, Game Mode is for you. The perhaps odd thing about this is that Threadripper is aimed at highly threaded workloads more than gaming, and so losing half the threads in Game Mode might actually be a detriment to a workstation implementation. That being said, users can leave SMT on and still change the memory access mode on its own, although AMD is really focusing more on the Creator and Game mode specifically.
For this review, we tested both Creator (default) and Game modes on the 16-core Threadripper 1950X. As an academic exercise we looked into memory latency in both modes, as well as at higher DRAM frequencies. These latency numbers take the results for the core selected (we chose core 2 in each case) and then stride through to hit L1, L2, L3 and main memory. For UMA systems like in Creator Mode, main memory will be an average between the near and far memory results. We’ve also added in here a Ryzen 5 1600X as an example of a single Zeppelin die, and a 6950X Broadwell for comparison. All CPUs were run at DDR4-2400, which is the maximum supported at two DIMMs per channel.
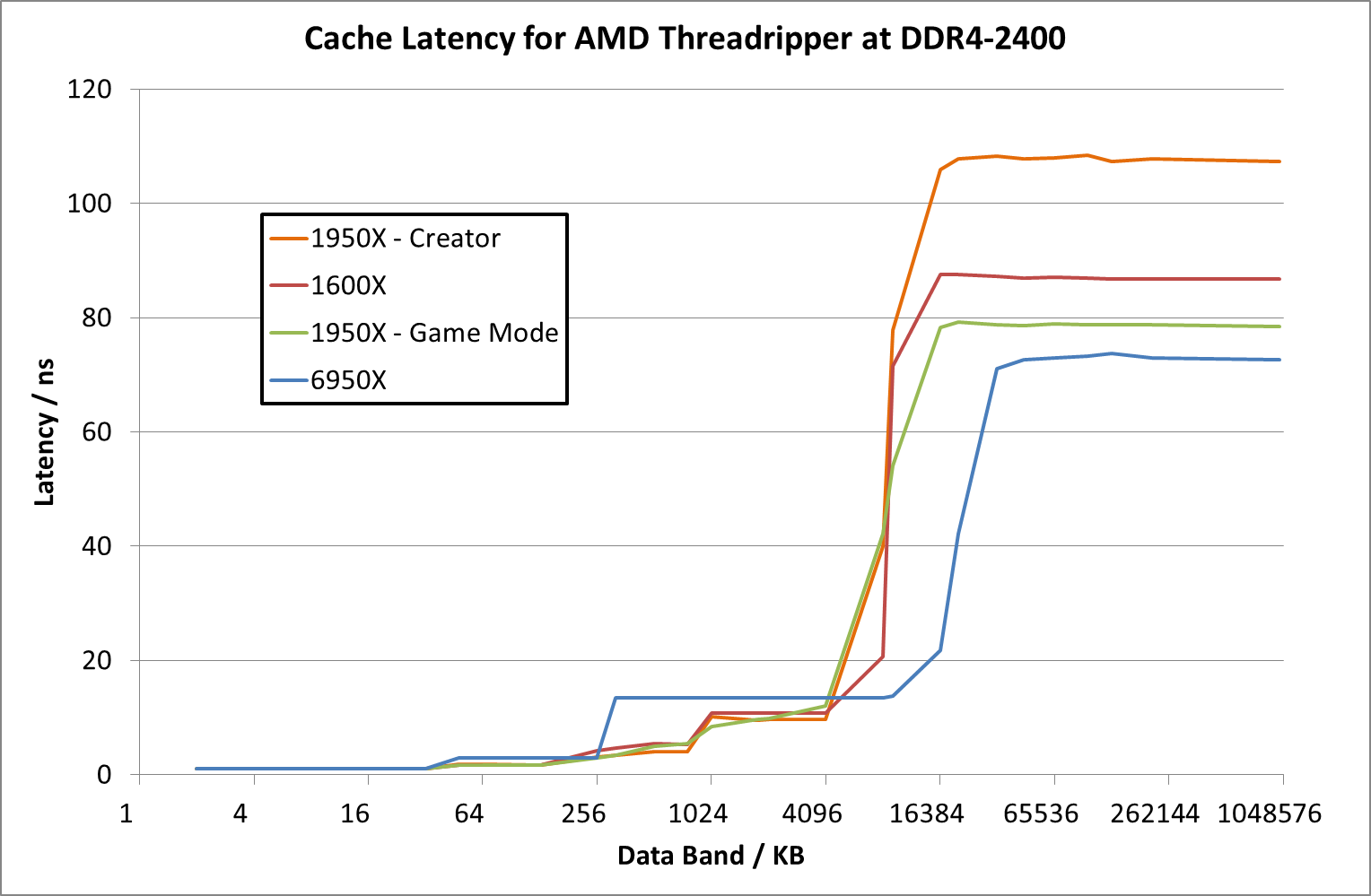
For the 1950X in the two modes, the results are essentially equal until we hit 8MB, which is the L3 cache limit per CCX. After this, the core bounces out to main memory, where the Game mode sits around 79ns while the Creator mode is at 108 ns. By comparison the Ryzen 5 1600X seems to have a lower latency at 8MB (20ns vs 41 ns), and then sits between the Creator and Game modes at 87 ns. It would appear that the bigger downside of Creator mode in this way is the fact that main memory accesses are much slower than normal Ryzen or in Game mode.
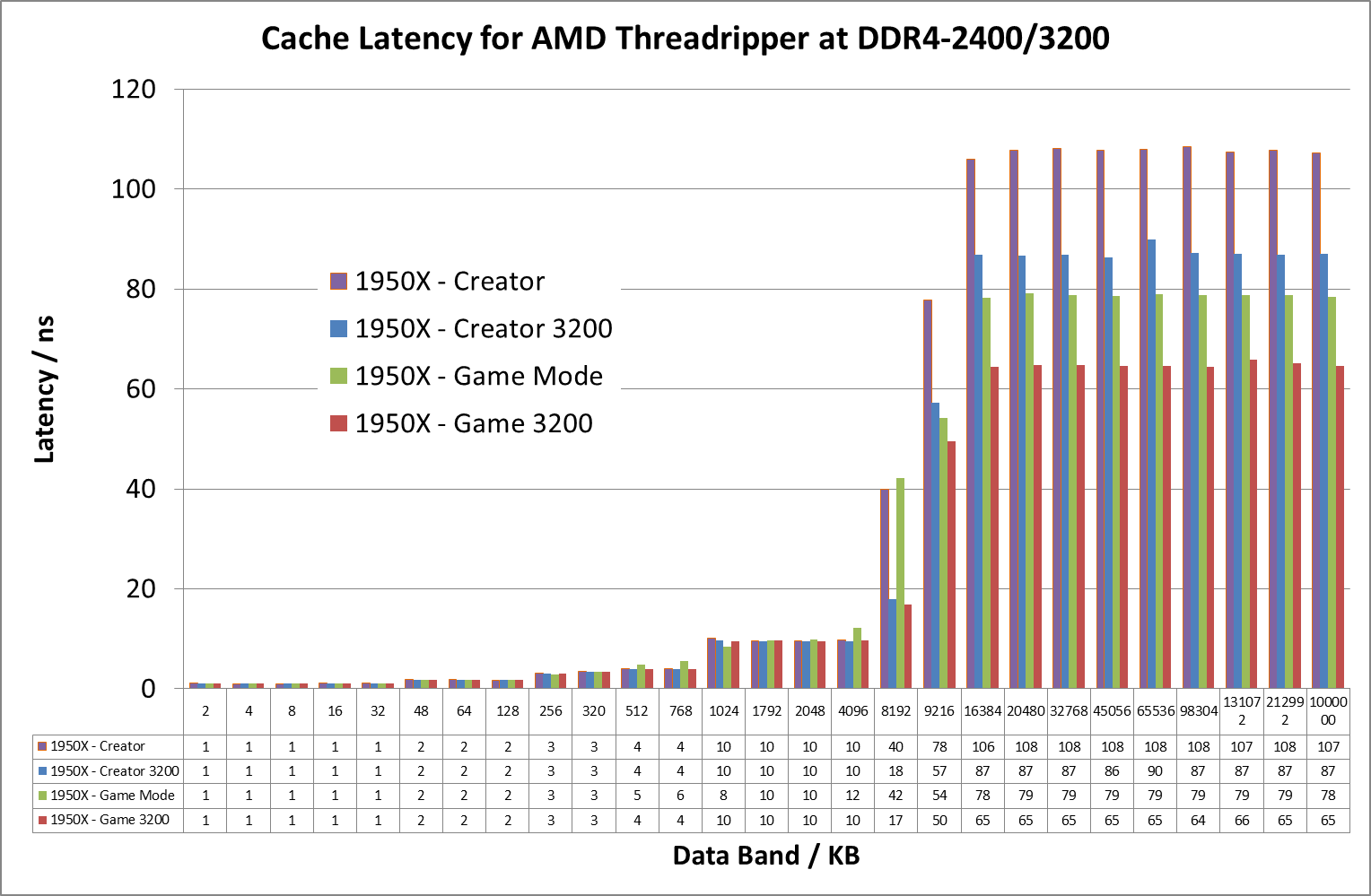
If we crank up the DRAM frequency to DDR4-3200 for the Threadripper 1950X, the numbers change a fair bit:
Click for larger image
Up until the 8MB boundary where L3 hits main memory, everything is pretty much equal. At 8MB however, the latency at DDR4-2400 is 41ns compared to 18ns at DDR4-3200. Then out into full main memory sees a pattern: Creator mode at DDR4-3200 is close to Game Mode at DDR4-2400 (87ns vs 79ns), but taking Game mode to DDR4-3200 drops the latency down to 65ns.
Another element we tested while in Game Mode was the latency for near memory and far memory as seen from a single core. Remember this slide from AMD’s deck?

In our testing, we achieved the following:
- At DDR4-2400, 79ns near memory and 136ns far memory (108ns average)
- At DDR4-3200, 65ns near memory and 108ns far memory (87ns average)
Those average numbers are what we get for Creator mode by default, indicating that the UMA mode in Creator mode will just use memory at random between the two.




















347 Comments
View All Comments
verl - Thursday, August 10, 2017 - link
"well above the Ryzen CPUs, and batching the 10C/8C parts from Broadwell-E and Haswell-E respectively"??? From the Power Consumption page.
bongey - Thursday, August 10, 2017 - link
Yep if you use AVX-512 it will down clock to 1.8Ghz and draw 400w just for the CPU alone and 600w from the wall. See der8auer's video title "The X299 VRM Disaster (en)", all x299 motherboards VRMs can be ran into thermal shutdown under avx 512 loads, with just a small overclock, not to mention avx512 crazy power consumption. That is why AMD didn't put avx 512 in Zen, it is power consumption monster.TidalWaveOne - Thursday, August 10, 2017 - link
Glad I went with the 7820X for software development (compiling).raddude9 - Thursday, August 10, 2017 - link
In ars' review they have TR-1950X ahead of the i9-7900X for compilation:https://arstechnica.co.uk/gadgets/2017/08/amd-thre...
In short it's very difficult to test compilation, every project you build has different properties.
emn13 - Thursday, August 10, 2017 - link
Yeah, the discrepency is huge - converted to anandtech's compile's per day the arstechnica benchmark maxes out at a little less than 20, which is a far cry from the we see here.Clearly, the details of the compiler, settings and codebase (and perhaps other things!) matter hugely.
That's unfortunate, because compilation is annoyingly slow, and it would be a boon to know what to buy to ameliorate that.
prisonerX - Thursday, August 10, 2017 - link
This is very compiler dependent. My compiler is blazingly fast on my wimpy hardware becuase it's blazingly clever. Most compilers seem to crawl no matter what they run on.bongey - Thursday, August 10, 2017 - link
Looks like anandtech's benchmark for compiling is bunk, it's just way off from all the other benchmarks out there. Not only that, no other test shows a 20% improvement over the 6950x which is also a 10 core/20 thread cpu. Something tells me the 7900x is completely wrong or has something faster like a different pcie ssd.Chad - Thursday, August 10, 2017 - link
All I know is, for those of us running Plex, SABnzbd, Sonarr, Radarr servers simultaneously (and others), while encoding and gaming all simultaneously, our day has arrived!:)
Ian Cutress - Thursday, August 10, 2017 - link
We checked with Ars as to their method.We use a fixed late March build around v56 under MSVC
Ars use a fixed newer build around v62 via clang-cl using VC++ linking
Same software, different compilers, different methods. Our results are faster than Ars, although Ars' results seem to scale better.
ddriver - Friday, August 11, 2017 - link
Of every review out there, only your "superior testing methodology" presents a picture where TR is slower than SX.