The AMD Ryzen 3 1300X and Ryzen 3 1200 CPU Review: Zen on a Budget
by Ian Cutress on July 27, 2017 9:30 AM EST- Posted in
- CPUs
- AMD
- Zen
- Ryzen
- Ryzen 3
- Ryzen 3 1300X
- Ryzen 3 1200
Benchmarking Performance: CPU Rendering Tests
Rendering tests are a long-time favorite of reviewers and benchmarkers, as the code used by rendering packages is usually highly optimized to squeeze every little bit of performance out. Sometimes rendering programs end up being heavily memory dependent as well - when you have that many threads flying about with a ton of data, having low latency memory can be key to everything. Here we take a few of the usual rendering packages under Windows 10, as well as a few new interesting benchmarks.
All of our benchmark results can also be found in our benchmark engine, Bench.
Corona 1.3: link
Corona is a standalone package designed to assist software like 3ds Max and Maya with photorealism via ray tracing. It's simple - shoot rays, get pixels. OK, it's more complicated than that, but the benchmark renders a fixed scene six times and offers results in terms of time and rays per second. The official benchmark tables list user submitted results in terms of time, however I feel rays per second is a better metric (in general, scores where higher is better seem to be easier to explain anyway). Corona likes to pile on the threads, so the results end up being very staggered based on thread count.
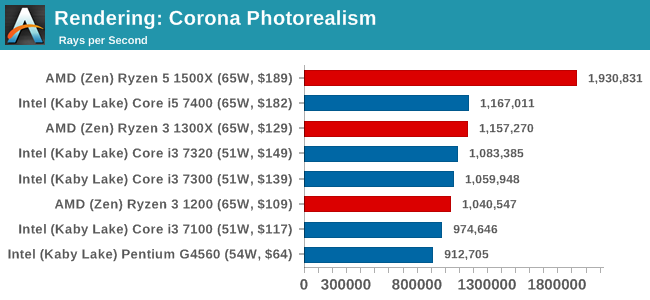
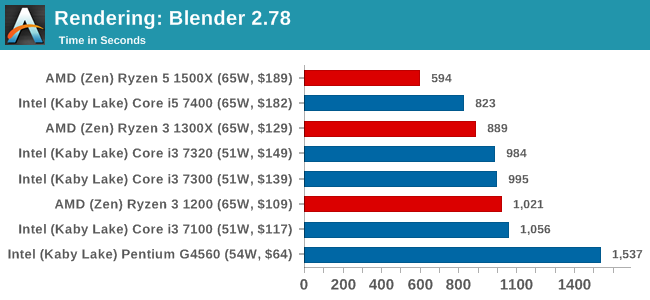
Blender 2.78: link
For a render that has been around for what seems like ages, Blender is still a highly popular tool. We managed to wrap up a standard workload into the February 5 nightly build of Blender and measure the time it takes to render the first frame of the scene. Being one of the bigger open source tools out there, it means both AMD and Intel work actively to help improve the codebase, for better or for worse on their own/each other's microarchitecture.
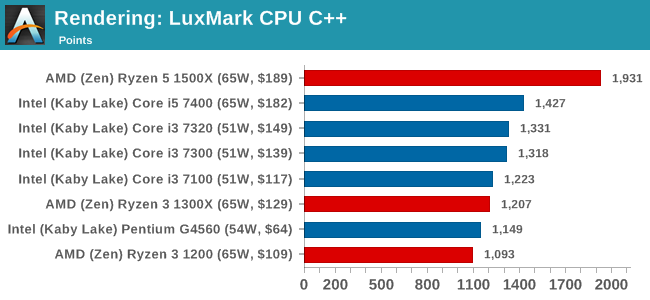
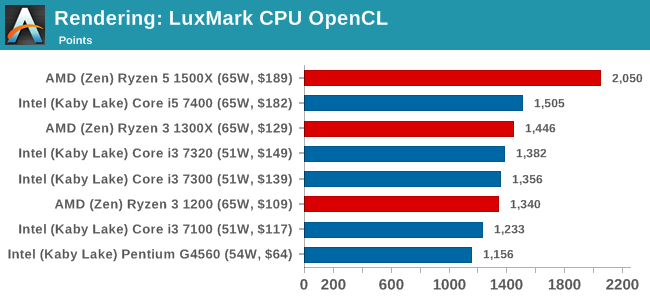
LuxMark v3.1: Link
As a synthetic, LuxMark might come across as somewhat arbitrary as a renderer, given that it's mainly used to test GPUs, but it does offer both an OpenCL and a standard C++ mode. In this instance, aside from seeing the comparison in each coding mode for cores and IPC, we also get to see the difference in performance moving from a C++ based code-stack to an OpenCL one with a CPU as the main host.
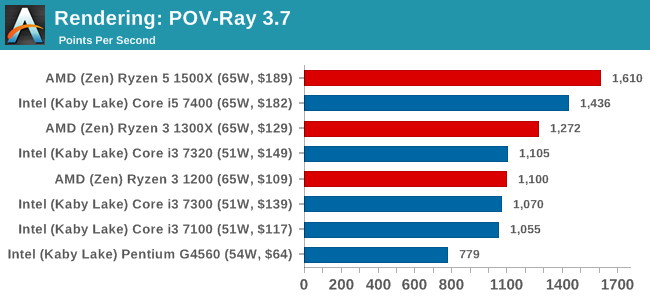
POV-Ray 3.7.1b4: link
Another regular benchmark in most suites, POV-Ray is another ray-tracer but has been around for many years. It just so happens that during the run up to AMD's Ryzen launch, the code base started to get active again with developers making changes to the code and pushing out updates. Our version and benchmarking started just before that was happening, but given time we will see where the POV-Ray code ends up and adjust in due course.
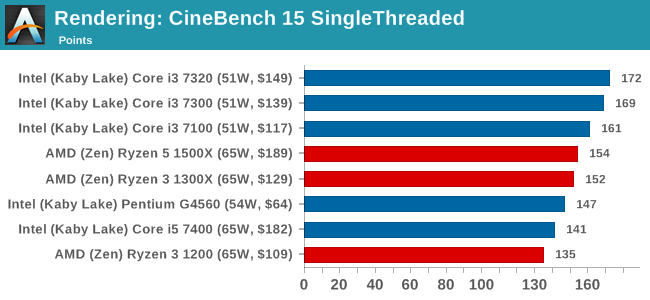
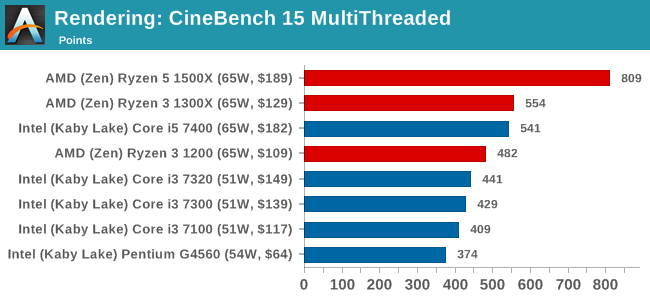
Cinebench R15: link
The latest version of CineBench has also become one of those 'used everywhere' benchmarks, particularly as an indicator of single thread performance. High IPC and high frequency gives performance in ST, whereas having good scaling and many cores is where the MT test wins out.








140 Comments
View All Comments
ampmam - Thursday, July 27, 2017 - link
Great review but biased conclusion.tvdang7 - Thursday, July 27, 2017 - link
No overclock?Oxford Guy - Thursday, July 27, 2017 - link
No, just a RAM underclock.zodiacfml - Thursday, July 27, 2017 - link
overclocking tests on the ryzen 3 1200 please. the only weakness of the chip is for non-gaming or htpc usage as it will require purchasing a discrete graphics card. otherwise, it presents good value for most things like gaming and multi-threaded applications, add overclocking, and it gets even better.kaesden - Thursday, July 27, 2017 - link
one thing to not overlook with the ryzen 1300x is the platform. Its competitive with budget intel offerings and can take a drop in 8 core 16 thread upgrade with no other changes except maybe a better cooling solution, Something intel can't match. Intel has the same "strategy" at their high end with the new X299 platform, but they seem to have lost focus of the big picture. The HEDT platform is too expensive to fit this type of scenario. Anyone who's shelling out the cash for a HEDT system isn't the type of budget user who is going to go for the 7740x. they're just going to get a higher end cpu from the start if they can afford it at all, not to mention the confusion about what features work with what cpu's and what doesn't, etc...TLDR; AMD has a winner of a platform here that will only get better as time goes on.
peevee - Thursday, July 27, 2017 - link
From the tests, looks like Razen 3 does not make much sense. Zen arch provides quite a boost from SMT in practically all applications where performance actually matters (which are all multithreaded for years now), and AMD artificially disabled this feature for that stupid Intel-like market segmentation.Also I am sure there are not that many CPUs where exactly 2 out of 4 cores on each CCX is broken. So in effect, in cases like one CCX has 4 good cores and another has only 2 they kill 2 good cores, kill half of L3, kill hyperthreading...
It would be better to create a separate 1-CCX chip for the line, which would have much higher (more that twice per wafer) yield being half the size, and release 2, 3 and 4 core CPUs as Ryzen 2, 3 and 4 accordingly. With hyperthreading and everything. I am sure it does not cost "tens of millions of dollars" to create a new mask as even completely custom chips cost less, let alone that simple derivative.
Oxford Guy - Thursday, July 27, 2017 - link
"It would be better to create a separate 1-CCX chip for the line"Or, it could be explained by this article why AMD can't release a Zen chip with 1 CCX enabled and one disabled. Instead, we just get "obviously".
silverblue - Friday, July 28, 2017 - link
He did explain it. Page 1.Oxford Guy - Saturday, July 29, 2017 - link
Where?All I see is this: "Number 3 leads to a lop-sided silicon die, and obviously wasn’t chosen."
That is not an explanation.
peevee - Tuesday, August 1, 2017 - link
That is still be half the yield per wafer compared to a dedicated 1-CCX line. Twice the cost. Cost matters.And the 3rd chip must be 1CCX+1GPU. SMT must be on everywhere though, it is too good to artificially lower value of your product by disabling it by segmentation.