AMD's Future in Servers: New 7000-Series CPUs Launched and EPYC Analysis
by Ian Cutress on June 20, 2017 4:00 PM EST- Posted in
- CPUs
- AMD
- Enterprise CPUs
- EPYC
- Whitehaven
- 1P
- 2P
Power
As with the Ryzen parts, EPYC will support 0.25x multipliers for P-state jumps of 25 MHz. With sufficient cooling, different workloads will be able to move between the base frequency and the maximum boost frequency in these jumps – AMD states that by offering smaller jumps it allows for smoother transitions rather than locking PLLs to move straight up and down, providing a more predictable performance implementation. This links into AMD’s new strategy of performance determinism vs power determinism.
Each of the EPYC CPUs include two new modes, one based on power and one based on performance. When a system configured at boot time to a specific maximum power, performance may vary based on the environment but the power is ultimately limited at the high end. For performance, the frequency is guaranteed, but not the power. This enables AMD customers to plan in advance without worrying about how different processors perform with regards voltage/frequency/leakage, or helps provide deterministic performance in all environments. This is done at the system level at boot time, so all VMs/containers on a system will be affected by this.
This extends into selectable power limits. For EPYC, AMD is offering the ability to run processors at a lower or higher TDP than out of the box – most users are likely familiar with Intel’s cTDP Up and cTDP Down modes on the mobile processors, and this feature by AMD is somewhat similar. As a result, the TDP limits given at the start of this piece can go down 15W or up 20W:
| EPYC TDP Modes | ||
| Low TDP | Regular TDP | High TDP |
| 155W | 180W | 200W |
| 140W | 155W | 175W |
| 105W | 120W | - |
The sole 120W processor at this point is the 8-core EPYC 7251 which is geared towards memory limited workloads that pay licenses per core, hence why it does not get a higher power band to work towards.
Workload-Aware Power Management
One of AMD’s points about the sort of workloads that might be run on EPYC is that sporadic tasks are sometimes hard to judge, or are not latency sensitive. In a non-latency sensitive environment, in order to conserve power, the CPU could spread the workload out across more cores at a lower frequency. We’ve seen this sort of policy before on Intel’s Skylake and up processors, going so far as duty cycling at the efficiency point to conserve power, or in the mobile space. AMD is bringing this to the EPYC line as well.

Rather than staying at the high frequency and continually powering up and down, by reducing the frequency such the cores are active longer, latency is traded for power efficiency. AMD is claiming up to a 10% perf-per-Watt improvement with this feature.
Frequency and voltage can be adjusted for each core independently, helping drive this feature. The silicon implements per-core linear regulators that work with the onboard sensor control to adjust the AVFS for the workload and the environment. We are told that this helps reduce the variability from core-to-core and chip-to-chip, with regulation supported with 2mV accuracy. We’ve seen some of this in Carrizo and Bristol Ridge already, although we are told that the goal for per-core VDO was always meant to be EPYC.
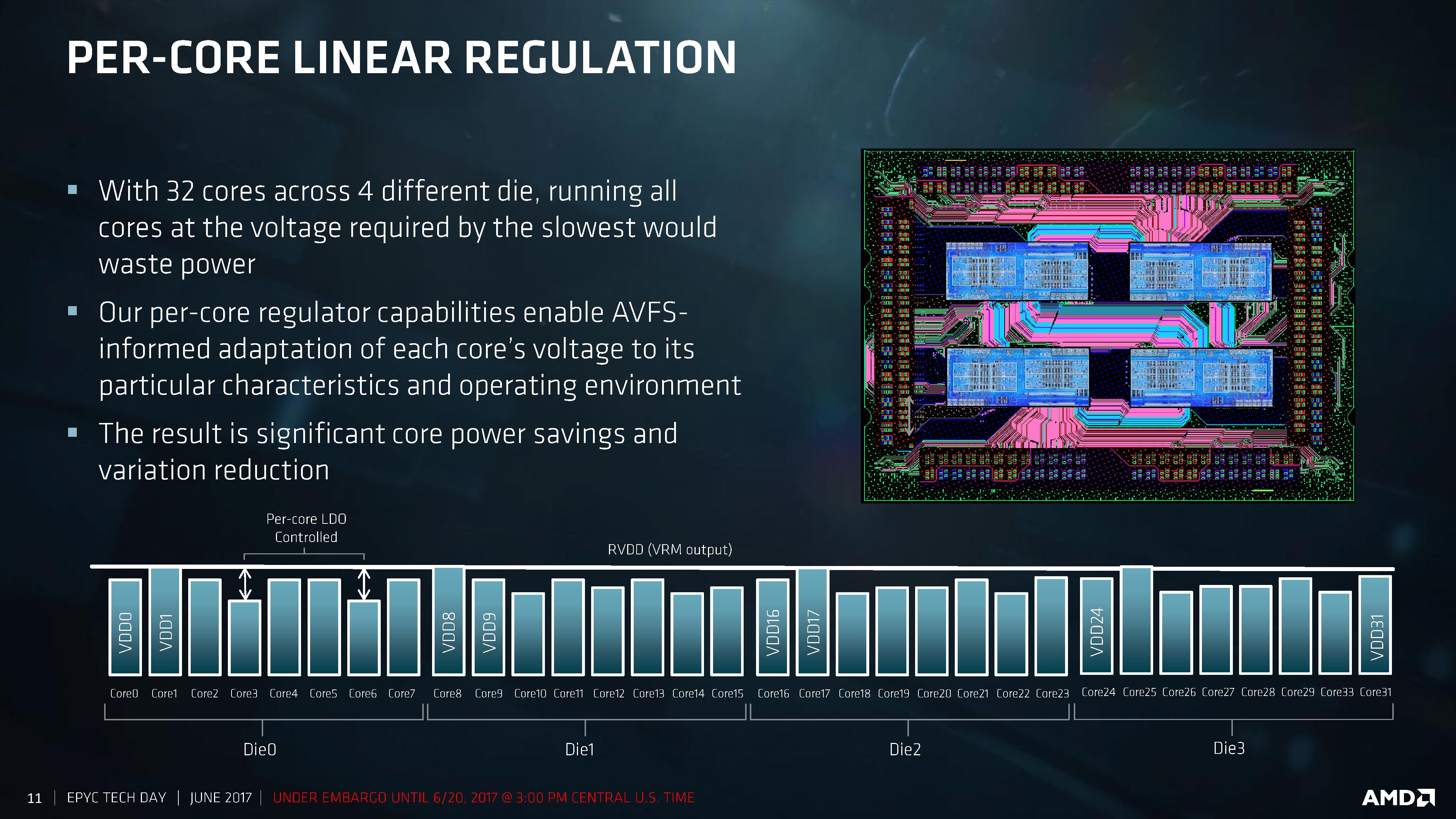
This can not only happen on the core, but also on the Infinity Fabric links between the CPU dies or between the sockets. By modulating the link width and analyzing traffic patterns, AMD claims another 8% perf-per-Watt for socket-to-socket communications.
Performance-Per-Watt Claims
For the EPYC system, AMD is claiming power efficiency results in terms of SPEC, compiled on GCC 6.2:
| AMD Claims 2P EPYC 7601 vs 2P E5-2699A V4 |
||
| SPECint | SPECfp | |
| Performance | 1.47x | 1.75x |
| Average Power | 0.96x | 0.99x |
| Total System Level Energy | 0.88x | 0.78x |
| Overall Perf/Watt | 1.54x | 1.76x |
Comparing a 2P high-end EPYC 7601 server against Intel’s current best 2P E5-2699A v4 arrangement, AMD is claiming a 1.54x perf/watt for integer performance and 1.76x perf/watt on floating point performance, giving more performance for a lower average power resulting in overall power gains. Again, we cannot confirm these numbers, so we look forward to testing.








131 Comments
View All Comments
davegraham - Tuesday, June 20, 2017 - link
I'm waiting to see consumer sites benchmark a server CPU against retail CPUs and then crow about clocks, etc. ;) it'll be done, it'll be vicious, and people will take it as the gospel truth. heck, let's just get the Cinebench testing done ASAP and call it day ;)Gothmoth - Tuesday, June 20, 2017 - link
yeah why is anandtech reporting about server hardware. nobody is interested in that.just let us take AMDs numbers as gospel.... a interpolate threadripper numbers until august.
SkiBum1207 - Tuesday, June 20, 2017 - link
Excuse me? There are us who use servers to make money - we definitely care about Anandtech's analysis of enterprise hardware.davegraham - Tuesday, June 20, 2017 - link
I am interested in Ian's take but I test this hardware on my own using the toolsets available to me. While I appreciate Johan's insights, I find most of the consumer sites (as Anandtech is one of them) to be reaching when they try to provide realistic workload testing. StorageReview.com does a decent job (mostly), but I'm finding that most reviews, sadly, are hit and miss against test benches and their applicability is...dubious at best.and like LurkingSince97 infers, spec-int is a fanboy benchmark ;)
D
at80eighty - Tuesday, June 20, 2017 - link
did you discover the site yesterday?davegraham - Tuesday, June 20, 2017 - link
lol. who, me? nope. ;)at80eighty - Wednesday, June 21, 2017 - link
sorry, the comment threading is not helpful - i directed that question to Gothmoth's absurd postdeltaFx2 - Wednesday, June 21, 2017 - link
Plenty of people are interested in it, and those people do their own benchmarking. They don't visit Anandtech or Tom's hardware to get this information.LurkingSince97 - Tuesday, June 20, 2017 - link
Except that nobody runs spec-int on their servers.AMD made two mistakes:
1. spec-int should not be used to compare servers across architectures. Instead, run real software that people use on servers. Virtualization benchmarks, JVM stuff, databases, whatever. Real world things.
2. Trying to modify spec-int results (I guess, by using GCC instead of intel's compiler, and compensating for the stuff their compiler does). Yeah, a lot of the tricks that some compilers use on spec-int are absolutely garbage and would not make real-world applications faster -- just spec-int. But there is no objective way to disentangle that. So stay away from it.
IanHagen - Tuesday, June 20, 2017 - link
Intel's compiler cripples code on AMD and VIA chipsAnti-competitive at the machine code level
https://www.theinquirer.net/inquirer/news/1567108/...
Intel finally agrees to pay $15 to Pentium 4 owners over AMD Athlon benchmarking shenanigans
https://www.extremetech.com/computing/193480-intel...
FTC Settles Charges of Anticompetitive Conduct Against Intel
https://www.ftc.gov/news-events/press-releases/201...