Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Floating Point
Normally our HPC benchmarking is centered around OpenFoam, a CFD software we have used for a number of articles over the years. However, since we moved to Ubuntu 16.04, we could not get it to work anymore. So we decided to change our floating point intensive benchmark for now. For our latest article, we're testing with C-ray, POV-Ray, and NAMD.
The idea is to measure:
- A FP benchmark that is running out of the L1 (C-ray)
- A FP benchmark that is running out of the L2 (POV-Ray)
- And one that is using the memory subsytem quite often (NAMD)
Floating Point: C-ray
C-ray is an extremely simple ray-tracer which is not representative of any real world raytracing application. In fact, it is essentially a floating point benchmark that runs out of the L1-cache. Luckily it is not as synthetic and meaningless as Whetstone, as you can actually use the software to do simple raytracing.
We use the standard benchmarking resolution (3840x2160) and the "sphfract" file to measure performance. The binary was precompiled.
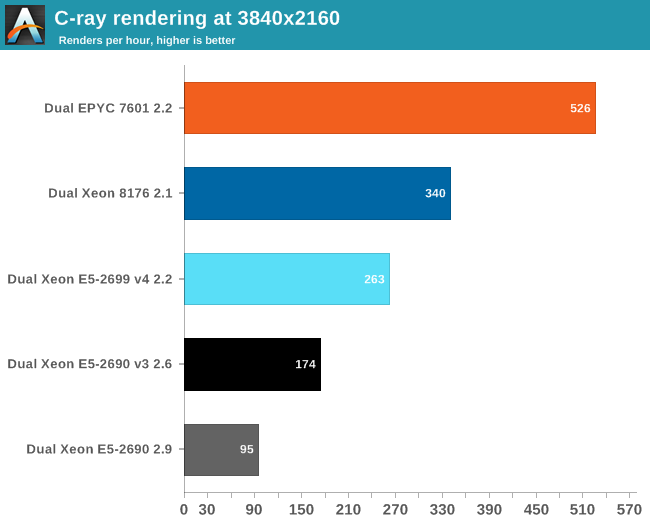
Wow. What just happened? It looks like a landslide victory for the raw power of the four FP pipes of Zen: the EPYC chip is no less than 50% faster than the competition. Of course, it is easy to feed FP units if everything resides in the L1. Next stop, POV-Ray.
Floating Point: POV-Ray 3.7
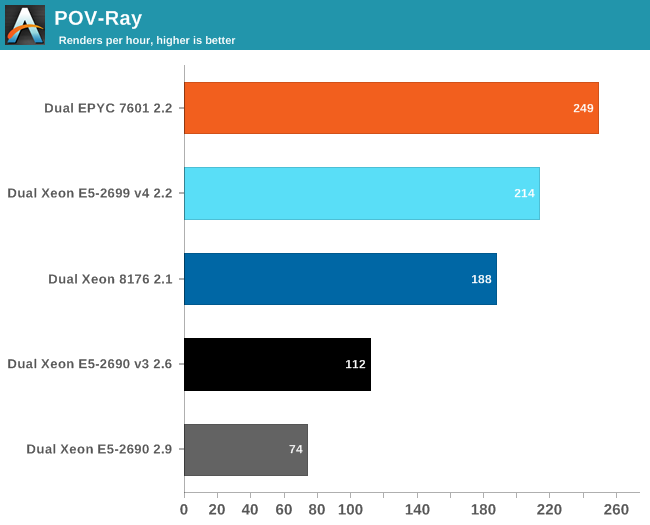
POV-Ray is known to run mostly out of the L2-cache, so the massive DRAM bandwidth of the EPYC CPU does not play a role here. Nevertheless, the EPYC CPU performance is pretty stunning: about 16% faster than Intel's Xeon 8176. But what if AVX and DRAM access come in to play? Let us check out NAMD.
Floating Point: NAMD
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization on thousands of cores. NAMD is also part of SPEC CPU2006 FP. In contrast with previous FP benchmarks, the NAMD binary is compiled with Intel ICC and optimized for AVX.
First, we used the "NAMD_2.10_Linux-x86_64-multicore" binary. We used the most popular benchmark load, apoa1 (Apolipoprotein A1). The results are expressed in simulated nanoseconds per wall-clock day. We measure at 500 steps.
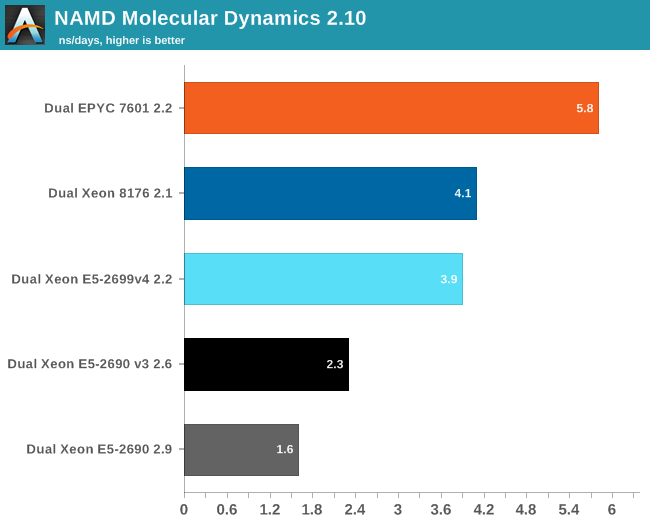
Again, the EPYC 7601 simply crushes the competition with 41% better performance than Intel's 28-core. Heavily vectorized code (like Linpack) might run much faster on Intel, but other FP code seems to run faster on AMD's newest FPU.
For our first shot with this benchmark, we used version 2.10 to be able to compare to our older data set. Version 2.12 seems to make better use of "Intel's compiler vectorization and auto-dispatch has improved performance for Intel processors supporting AVX instructions". So let's try again:
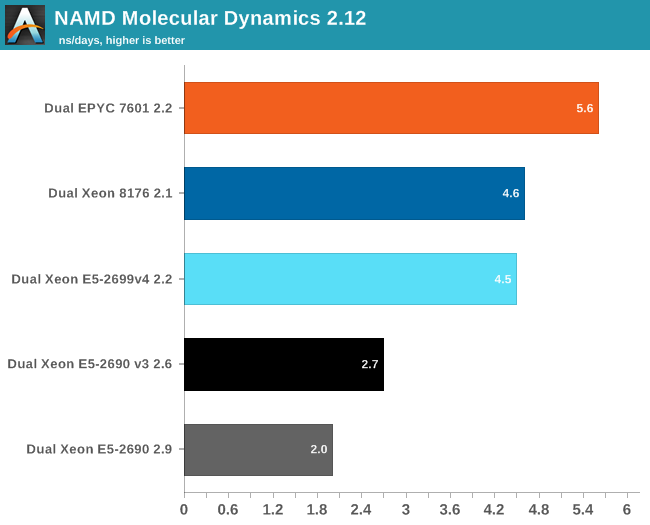
The older Xeons see a perforance boost of about 25%. The improvement on the new Xeons is a lot lower: about 13-15%. Remarkable is that the new binary is slower on the EPYC 7601: about 4%. That simply begs for more investigation: but the deadline was too close. Nevertheless, three different FP tests all point in the same direction: the Zen FP unit might not have the highest "peak FLOPs" in theory, there is lots of FP code out there that runs best on EPYC.








219 Comments
View All Comments
ddriver - Wednesday, July 12, 2017 - link
LOL, buthurt intel fanboy claims that the only unbiased benchmark in the review is THE MOST biased benchmark in the review, the one that was done entirely for the puprpose to help intel save face.Because if many core servers running 128 gigs of ram are primarily used to run 16 megabyte databases in the real world. That's right!
Beany2013 - Tuesday, July 11, 2017 - link
Sure, test against Ubuntu 17.04 if you only plan to have your server running till January. When it goes end of life. That's not a joke - non LTS Ubuntu released get nine months patches and that's it.https://wiki.ubuntu.com/Releases
16.04 is supported till 2021, it's what will be used in production by people who actually *buy* and *use* servers and as such it's a perfectly representative benchmark for people like me who are looking at dropping six figures on this level of hardware soon and want to see how it performs on...goodness, realistic workloads.
rahvin - Wednesday, July 12, 2017 - link
This is a silly argument. No one running these is going to be running bleeding edge software, compiling special kernels or putting optimizing compiler flags on anything. Enterprise runs on stable verified software and OS's. Your typical Enterprise Linux install is similar to RHEL 6 or 7 or it's variants (some are still running RHEL 5 with a 2.6 kernel!). Both RHEL6 and 7 have kernels that are 5+ years old and if you go with 6 it's closer to 10 year old.Enterprises don't run bleeding edge software or compile with aggressive flags, these things create regressions and difficult to trace bugs that cost time and lots of money. Your average enterprise is going to care about one thing, that's performance/watt running something like a LAMP stack or database on a standard vanilla distribution like RHEL. Any large enterprise is going to take a review like this and use it as data point when they buy a server and put a standard image on it and test their own workloads perf/watt.
Some of the enterprises who are more fault tolerant might run something as bleeding edge as an Ubuntu Server LTS release. This review is a fair review for the expected audience, yes every writer has a little bias but I'd dare you to find it in this article, because the fanboi's on both sides are complaining that indicates how fair the review is.
jjj - Tuesday, July 11, 2017 - link
Do remember that the future is chiplets, even for Intel.The 2 are approaching that a bit differently as AMD had more cost constrains so they went with a 4 cores CCX that can be reused in many different prods.
Highly doubt that AMD ever goes back to a very large die and it's not like Intel could do a monolithic 48 cores on 10nm this year or even next year and that would be even harder in a competitive market. Sure if they had a Cortex A75 like core and a lot less cache, that's another matter but they are so far behind in perf/mm2 that it's hard to even imagine that they can ever be that efficient.
coder543 - Tuesday, July 11, 2017 - link
Never heard the term "chiplet" before. I think AMD has adequately demonstrated the advantages (much higher yield -> lower cost, more than adequate performance), but I haven't heard Intel ever announce that they're planning to do this approach. After the embarrassment that they're experiencing now, maybe they will.Ian Cutress - Tuesday, July 11, 2017 - link
Look up Intel's EMIB. It's an obvious future for that route to take as process nodes get smaller.Threska - Saturday, July 22, 2017 - link
We may see their interposer (like used with their GPUs) technology being used.jeffsci - Tuesday, July 11, 2017 - link
Benchmarking NAMD with pre-compiled binaries is pretty silly. If you can't figure out how to compile it for each every processor of interest, you shouldn't be benchmarking it.CajunArson - Tuesday, July 11, 2017 - link
On top of all that, they couldn't even be bothered to download and install a (completely free) vanilla version that was released this year. Their version of NAMD 2.10 is from *2014*!http://www.ks.uiuc.edu/Development/Download/downlo...
tamalero - Tuesday, July 11, 2017 - link
Do high level servers update their versions constantly?I know that most of the critical stuff, only patch serious vulnerabilities and not update constantly to newer things just because they are available.