Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
AMD's EPYC Server CPU
If you have read Ian's articles about Zen and EPYC in detail, you can skip this page. For those of you who need a refresher, let us quickly review what AMD is offering.
The basic building block of EPYC and Ryzen is the CPU Complex (CCX), which consists of 4 vastly improved "Zen" cores, connected to an L3-cache. In a full configuration each core technically has its own 2 MB of L3, but access to the other 6 MB is rather speedy. Within a CCX we measured 13 ns to access the first 2 MB, and 15 to 19 ns for the rest of the 8 MB L3-cache, a difference that's hardly noticeable in the grand scheme of things. The L3-cache acts as a mostly exclusive victim cache.
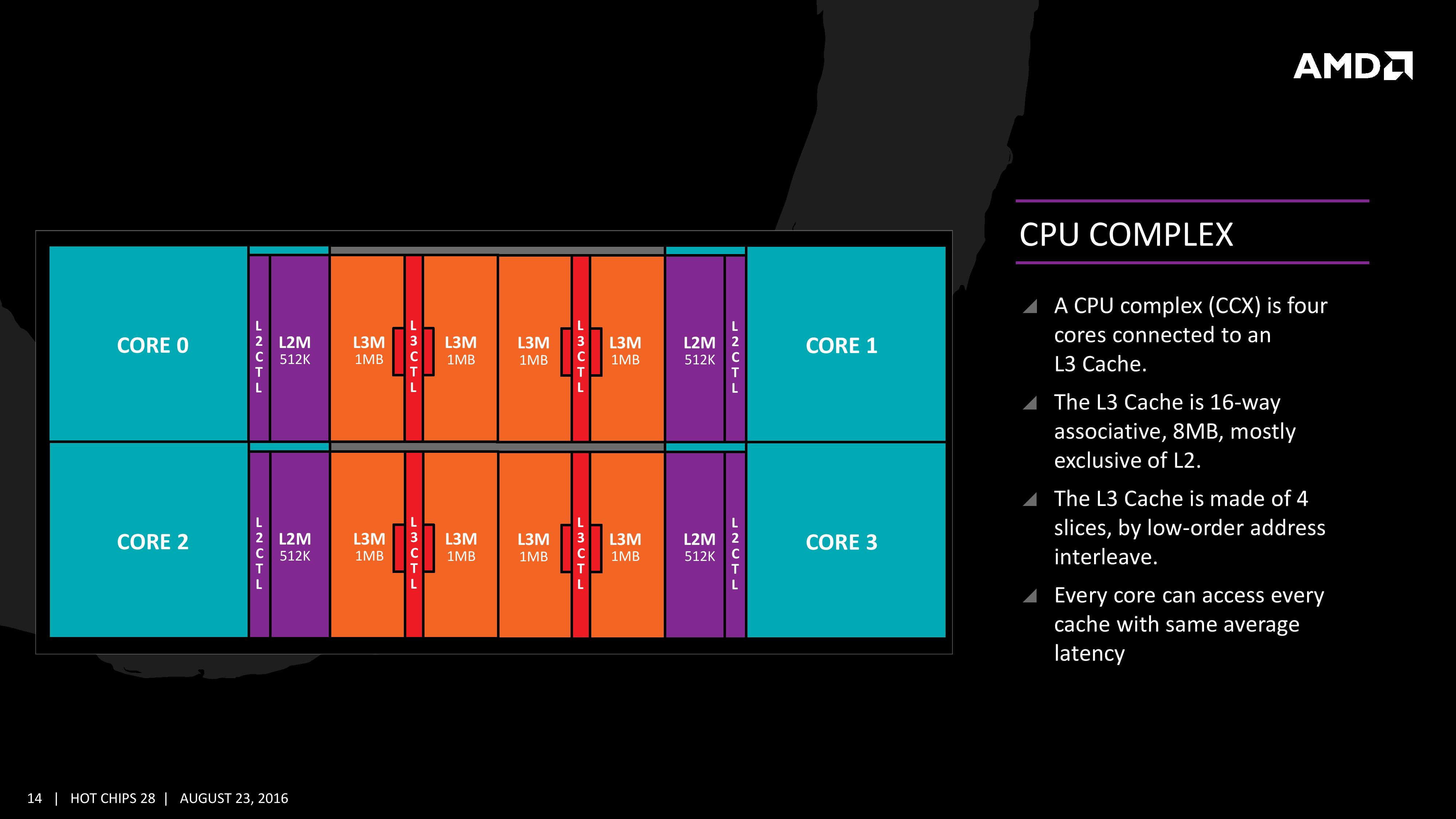
Two CCXes make up one Zeppelin die. A custom fabric – AMD's Infinity Fabric – ties together two CCXes, the two 8 MB L3-caches, 2 DDR4-channels, and the integrated PCIe lanes. That topology is not without some drawbacks though: it means that there are two separate 8 MB L3 caches instead of one single 16 MB LLC. This has all kinds of consequences. For example the prefetchers of each core make sure that data of the L3 is brought into the L1 when it is needed. Meanwhile each CCX has its own separate (not inside the L3, so no capacity hit) and dedicated SRAM snoop directory (keeping track of 7 possible states). In other words, the local L3-cache communicates very quickly with everything inside the same CCX, but every data exchange between two CCXes comes with a tangible latency penalty.
Moving further up the chain, the complete EPYC chip is a Multi Chip Module(MCM) containing 4 Zeppelin dies.
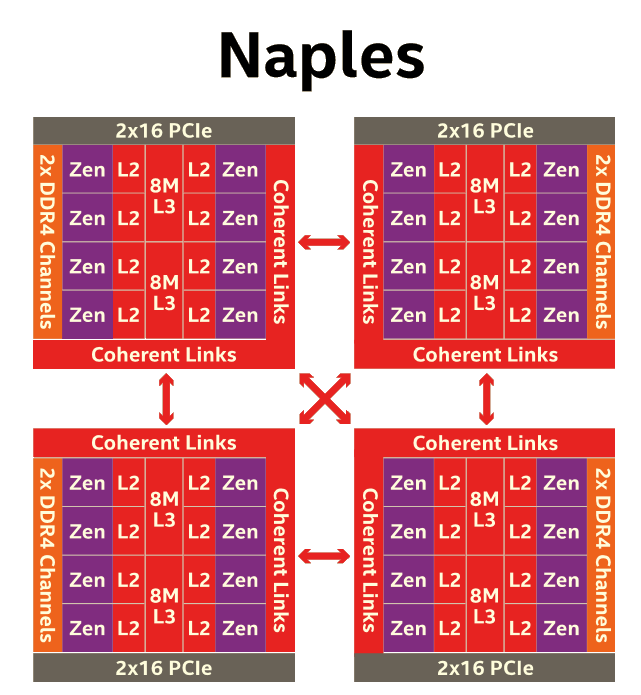
AMD made sure that each die is only one hop apart from the other, ensuring that the off-die latency is as low as reasonably possible.
Meanwhile scaling things up to their logical conclusion, we have 2P configurations. A dual socket EPYC setup is in fact a "virtual octal socket" NUMA system.

AMD gave this "virtual octal socket" topology ample bandwidth to communicate. The two physical sockets are connected by four bidirectional interconnects, each consisting of 16 PCIe lanes. Each of these interconnect links operates at +/- 38 GB/s (or 19 GB/s in each direction).
So basically, AMD's topology is ideal for applications with many independently working threads such as small VMs, HPC applications, and so on. It is less suited for applications that require a lot of data synchronization such as transactional databases. In the latter case, the extra latency of exchanging data between dies and even CCX is going to have an impact relative to a traditional monolithic design.








219 Comments
View All Comments
ddriver - Wednesday, July 12, 2017 - link
LOL, buthurt intel fanboy claims that the only unbiased benchmark in the review is THE MOST biased benchmark in the review, the one that was done entirely for the puprpose to help intel save face.Because if many core servers running 128 gigs of ram are primarily used to run 16 megabyte databases in the real world. That's right!
Beany2013 - Tuesday, July 11, 2017 - link
Sure, test against Ubuntu 17.04 if you only plan to have your server running till January. When it goes end of life. That's not a joke - non LTS Ubuntu released get nine months patches and that's it.https://wiki.ubuntu.com/Releases
16.04 is supported till 2021, it's what will be used in production by people who actually *buy* and *use* servers and as such it's a perfectly representative benchmark for people like me who are looking at dropping six figures on this level of hardware soon and want to see how it performs on...goodness, realistic workloads.
rahvin - Wednesday, July 12, 2017 - link
This is a silly argument. No one running these is going to be running bleeding edge software, compiling special kernels or putting optimizing compiler flags on anything. Enterprise runs on stable verified software and OS's. Your typical Enterprise Linux install is similar to RHEL 6 or 7 or it's variants (some are still running RHEL 5 with a 2.6 kernel!). Both RHEL6 and 7 have kernels that are 5+ years old and if you go with 6 it's closer to 10 year old.Enterprises don't run bleeding edge software or compile with aggressive flags, these things create regressions and difficult to trace bugs that cost time and lots of money. Your average enterprise is going to care about one thing, that's performance/watt running something like a LAMP stack or database on a standard vanilla distribution like RHEL. Any large enterprise is going to take a review like this and use it as data point when they buy a server and put a standard image on it and test their own workloads perf/watt.
Some of the enterprises who are more fault tolerant might run something as bleeding edge as an Ubuntu Server LTS release. This review is a fair review for the expected audience, yes every writer has a little bias but I'd dare you to find it in this article, because the fanboi's on both sides are complaining that indicates how fair the review is.
jjj - Tuesday, July 11, 2017 - link
Do remember that the future is chiplets, even for Intel.The 2 are approaching that a bit differently as AMD had more cost constrains so they went with a 4 cores CCX that can be reused in many different prods.
Highly doubt that AMD ever goes back to a very large die and it's not like Intel could do a monolithic 48 cores on 10nm this year or even next year and that would be even harder in a competitive market. Sure if they had a Cortex A75 like core and a lot less cache, that's another matter but they are so far behind in perf/mm2 that it's hard to even imagine that they can ever be that efficient.
coder543 - Tuesday, July 11, 2017 - link
Never heard the term "chiplet" before. I think AMD has adequately demonstrated the advantages (much higher yield -> lower cost, more than adequate performance), but I haven't heard Intel ever announce that they're planning to do this approach. After the embarrassment that they're experiencing now, maybe they will.Ian Cutress - Tuesday, July 11, 2017 - link
Look up Intel's EMIB. It's an obvious future for that route to take as process nodes get smaller.Threska - Saturday, July 22, 2017 - link
We may see their interposer (like used with their GPUs) technology being used.jeffsci - Tuesday, July 11, 2017 - link
Benchmarking NAMD with pre-compiled binaries is pretty silly. If you can't figure out how to compile it for each every processor of interest, you shouldn't be benchmarking it.CajunArson - Tuesday, July 11, 2017 - link
On top of all that, they couldn't even be bothered to download and install a (completely free) vanilla version that was released this year. Their version of NAMD 2.10 is from *2014*!http://www.ks.uiuc.edu/Development/Download/downlo...
tamalero - Tuesday, July 11, 2017 - link
Do high level servers update their versions constantly?I know that most of the critical stuff, only patch serious vulnerabilities and not update constantly to newer things just because they are available.