Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Intel's New On-Chip Topology: A Mesh
Since the introduction of the "Nehalem" CPU architecture – and the Xeon 5500 that started almost a decade-long reign for Intel in the datacenter – Intel's engineers have relied upon a low latency, high bandwidth ring to connect their cores with their caches, memory controllers, and I/O controllers.
Intel's most recent adjustment to their ring topology came with the Ivy Bridge-EP (Xeon E5 2600 v2) family of CPUs. The top models were the first with three columns of cores connected by a dual ring bus, which utilized both outer and inner rings. The rings moved data in opposite directions (clockwise/counter-clockwise) in order to minimize latency by allowing data to take the shortest path to the destination. As data is brought onto the ring infrastructure, it must be scheduled so that it does not collide with previous data.
The ring topology had a lot of advantages. It ran very fast, up to 3 GHz. As result, the L3-cache latency was pretty low: if the core is lucky enough to find the data in its own cache slice, only one extra cycle is needed (on top of the normal L1-L2-L3 latency). Getting a cacheline of another slice can cost up to 12 cycles, with an average cost of 6 cycles.
However the ring model started show its limits on the high core count versions of the Xeon E5 v3, which had no less than four columns of cores and LLC slices, making scheduling very complicated: Intel had to segregate the dual ring buses and integrate buffered switches. Keeping cache coherency performant also became more and more complex: some applications gained quite a bit of performance by choosing the right snoop filter mode (or alternatively, lost a lot of performance if they didn't pick the right mode). For example, our OpenFOAM benchmark performance improved by almost 20% by choosing "Home Snoop" mode, while many easy to scale, compute-intensive applications preferred "Cluster On Die" snooping mode.
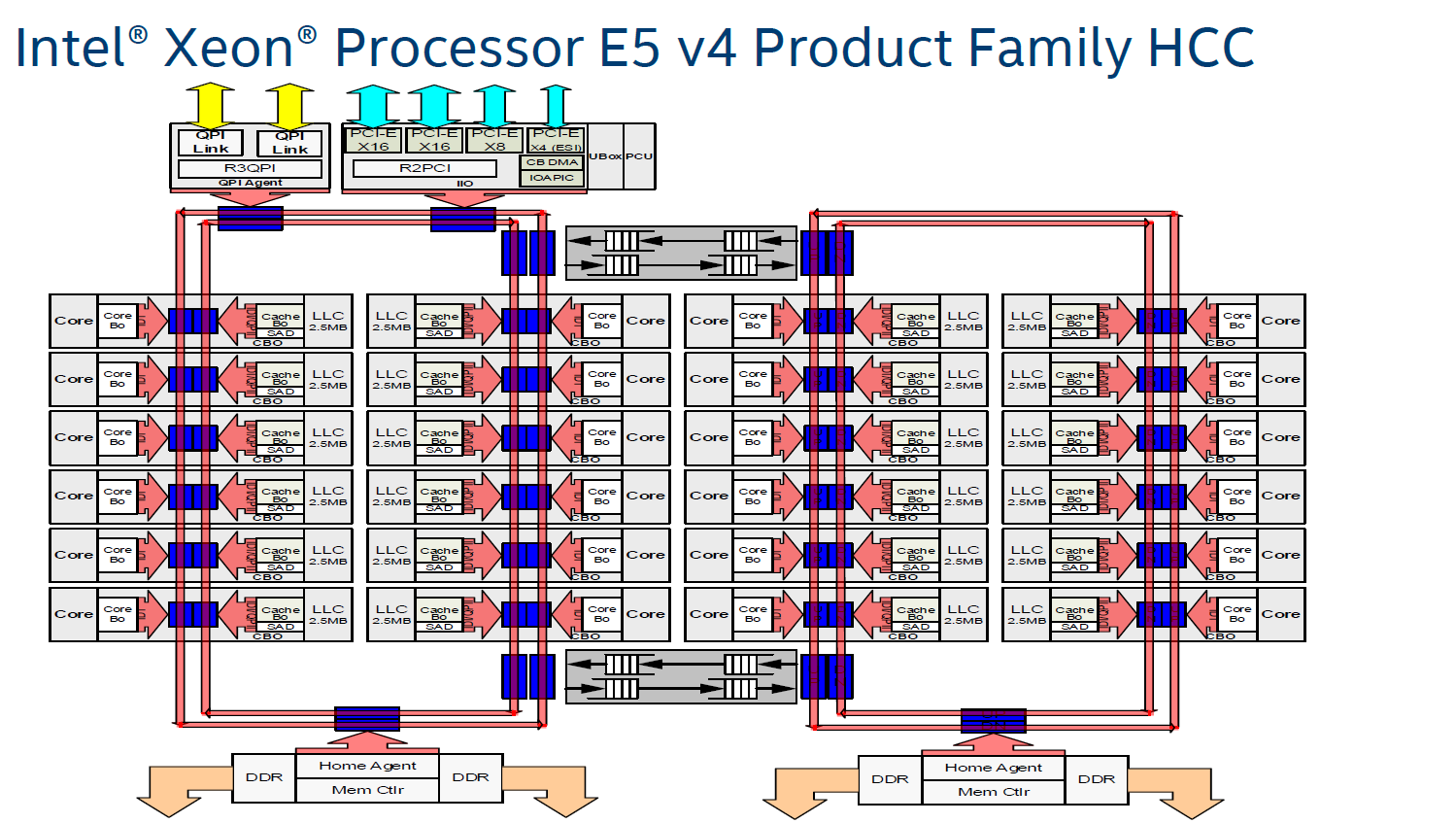
In other words, placing 22 (E7:24) cores, several PCIe controllers, and several memory controllers was close to the limit what a dual ring could support. In order to support an even larger number of cores than the Xeon v4 family, Intel would have to add a third ring, and ultimately connecting 3 rings with 6 columns of cores each would be overly complex.
Given that, it shouldn't come as a surprise that Intel's engineers decided to use a different topology for Skylake-SP to connect up to 28 cores with the "uncore." Intel's new solution? A mesh architecture.
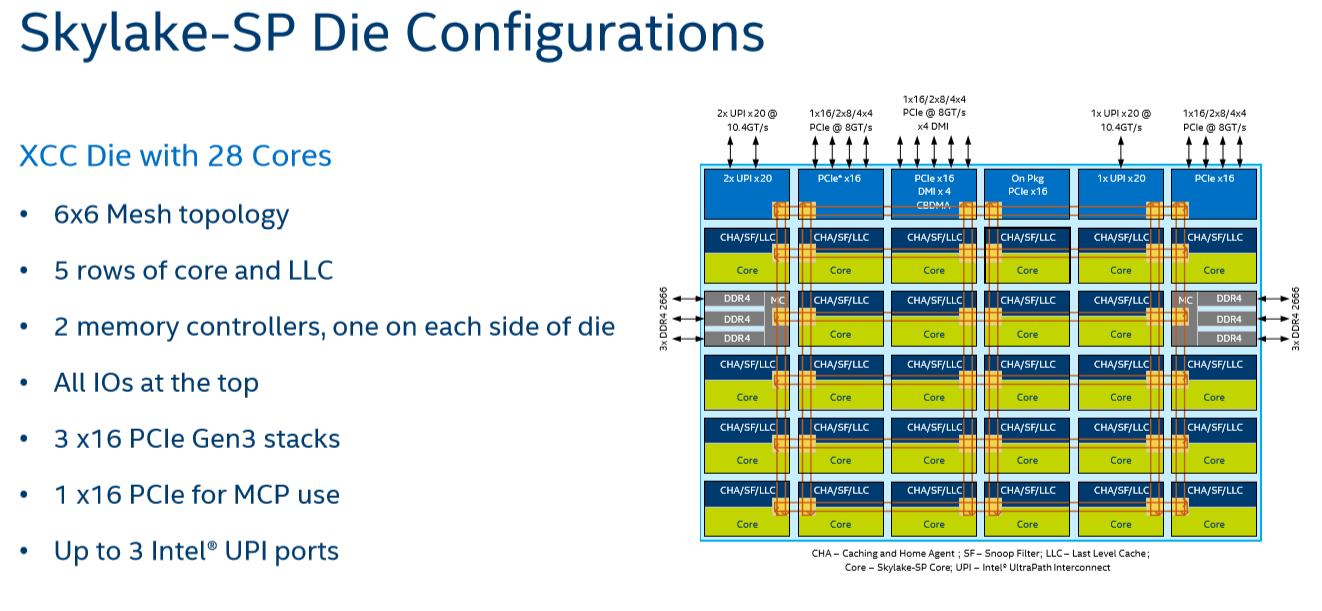
Under Intel's new topology, each node – a caching/home agent, a core, and a chunk of LLC – is interconnected via a mesh. Conceptually it is very similar to the mesh found on Xeon Phi, but not quite the same. In the long-run the mesh is far more scalable than Intel's previous ring topology, allowing Intel to connect many more nodes in the future.
How does it compare to the ring architecture? The Ring could run at up to 3 GHz, while the current mesh and L3-cache runs at at between 1.8GHZ and 2.4GHz. On top of that, the mesh inside the top Skylake-SP SKUs has to support more cores, which further increases the latency. Still, according to Intel the average latency to the L3-cache is only 10% higher, and the power usage is lower.

A core that access an L3-cache slice that is very close (like the ones vertically above each other) gets an additional latency of 1 cycle per hop. An access to a cache slice that is vertically 2 hops away needs 2 cycles, and one that is 2 hops away horizontally needs 3 cycles. A core from the bottom that needs to access a cache slice at the top needs only 4 cycles. Horizontally, you get a latency of 9 cycles at the most. So despite the fact that this Mesh connects 6 extra cores verse Broadwell-EP, it delivers an average latency in the same ballpark (even slightly better) as the former's dual ring architecture with 22 cores (6 cycles average).
Meanwhile the worst case scenario – getting data from the right top node to the bottom left node – should demand around 13 cycles. And before you get too concerned with that number, keep in mind that it compares very favorably with any off die communication that has to happen between different dies in (AMD's) Multi Chip Module (MCM), with the Skylake-SP's latency being around one-tenth of EPYC's. It is crystal clear that there will be some situations where Intel's server chip scales better than AMD's solution.
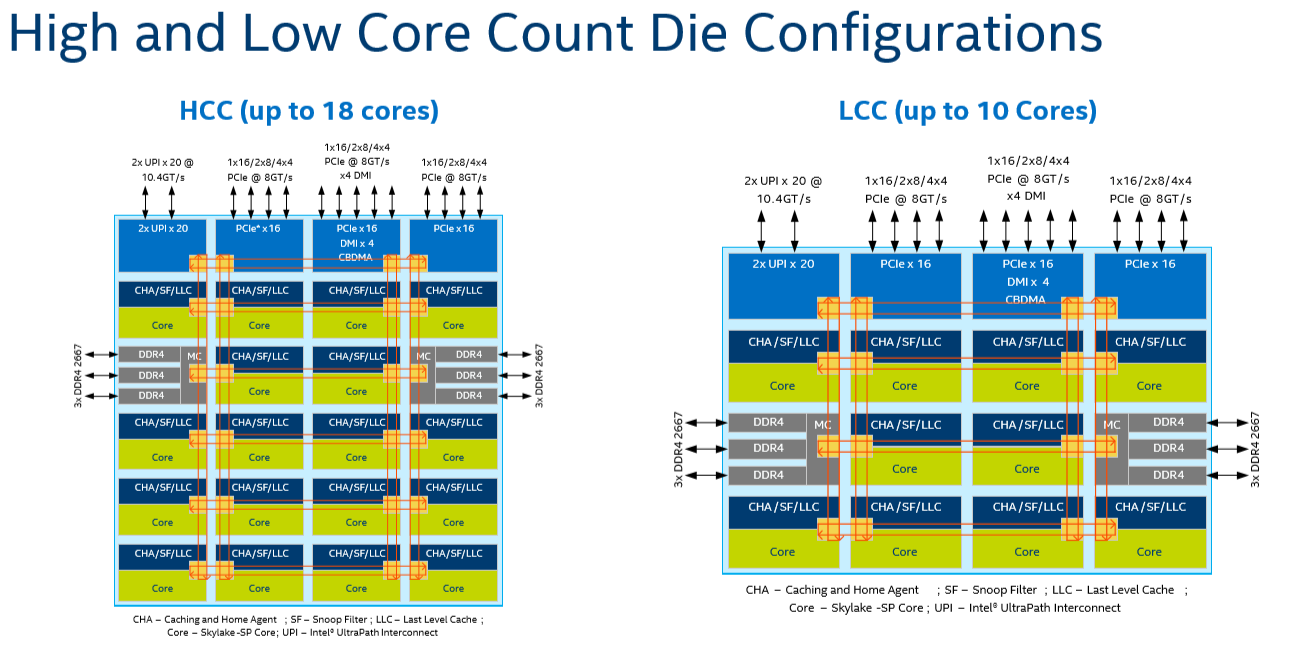
There are other advantages that help Intel's mesh scale: for example, caching and home agents are now distributed, with each core getting one. This reduces snoop traffic and reduces snoop latency. Also, the number of snoop modes is reduced: no longer do you need to choose between home snoop or early snoop. A "cluster-on-die" mode is still supported: it is now called sub-NUMA Cluster or SNC. With SNC you can divide the huge Intel server chips into two NUMA domains to lower the latency of the LLC (but potentially reduce the hitrate) and limit the snoop broadcasts to one SNC domain.








219 Comments
View All Comments
psychobriggsy - Tuesday, July 11, 2017 - link
Indeed it is a ridiculous comment, and puts the earlier crying about the older Ubuntu and GCC into context - just an Intel Fanboy.In fact Intel's core architecture is older, and GCC has been tweaked a lot for it over the years - a slightly old GCC might not get the best out of Skylake, but it will get a lot. Zen is a new core, and GCC has only recently got optimisations for it.
EasyListening - Wednesday, July 12, 2017 - link
I thought he was joking, but I didn't find it funny. So dumb.... makes me sad.blublub - Tuesday, July 11, 2017 - link
I kinda miss Infinity Fabric on my Haswell CPU and it seems to only have on die - so why is that missing on Haswell wehen Ryzen is an exact copy?blublub - Tuesday, July 11, 2017 - link
Your actually sound similar to JuanRGA at SAKevin G - Wednesday, July 12, 2017 - link
@CajunArson The cache hierarchy is radically different between these designs as well as the port arrangement for dispatch. Scheduling on Ryzen is split between execution resources where as Intel favors a unified approach.bill.rookard - Tuesday, July 11, 2017 - link
Well, that is something that could be figured out if they (anandtech) had more time with the servers. Remember, they only had a week with the AMD system, and much like many of the games and such, optimizing is a matter of run test, measure, examine results, tweak settings, rinse and repeat. Considering one of the tests took 4 hours to run, having only a week to do this testing means much of the optimization is probably left out.They went with a 'generic' set of relative optimizations in the interest of time, and these are the (very interesting) results.
CoachAub - Wednesday, July 12, 2017 - link
Benchmarks just need to be run on as level as a field as possible. Intel has controlled the market so long, software leans their way. Who was optimizing for Opteron chips in 2016-17? ;)theeldest - Tuesday, July 11, 2017 - link
The compiler used isn't meant to be the the most optimized, but instead it's trying to be representative of actual customer workloads.Most customer applications in normal datacenters (not google, aws, azure, etc) are running binaries that are many years behind on optimizations.
So, yes, they can get better performance. But using those optimizations is not representative of the market they're trying to show numbers for.
CajunArson - Tuesday, July 11, 2017 - link
That might make a tiny bit of sense if most of the benchmarks run were real-world workloads and not C-Ray or POV-Ray.The most real-world benchmark in the whole setup was the database benchmark.
coder543 - Tuesday, July 11, 2017 - link
The one benchmark that favors Intel is the "most real-world"? Absolutely, I want AnandTech to do further testing, but your comments do not sound unbiased.