Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Closing Thoughts
First of all, we have to emphasize that we were only able to spend about a week on the AMD server, and about two weeks on the Intel system. With the complexity of both server hardware and especially server software, that is very little time. There is still a lot to test and tune, but the general picture is clear.
We can continue to talk about Intel's excellent mesh topology and AMD strong new Zen architecture, but at the end of the day, the "how" will not matter to infrastructure professionals. Depending on your situation, performance, performance-per-watt, and/or performance-per-dollar are what matters.
The current Intel pricing draws the first line. If performance-per-dollar matters to you, AMD's EPYC pricing is very competitive for a wide range of software applications. With the exception of database software and vectorizable HPC code, AMD's EPYC 7601 ($4200) offers slightly less or slightly better performance than Intel's Xeon 8176 ($8000+). However the real competitor is probably the Xeon 8160, which has 4 (-14%) fewer cores and slightly lower turbo clocks (-100 or -200 MHz). We expect that this CPU will likely offer 15% lower performance, and yet it still costs about $500 more ($4700) than the best EPYC. Of course, everything will depend on the final server system price, but it looks like AMD's new EPYC will put some serious performance-per-dollar pressure on the Intel line.
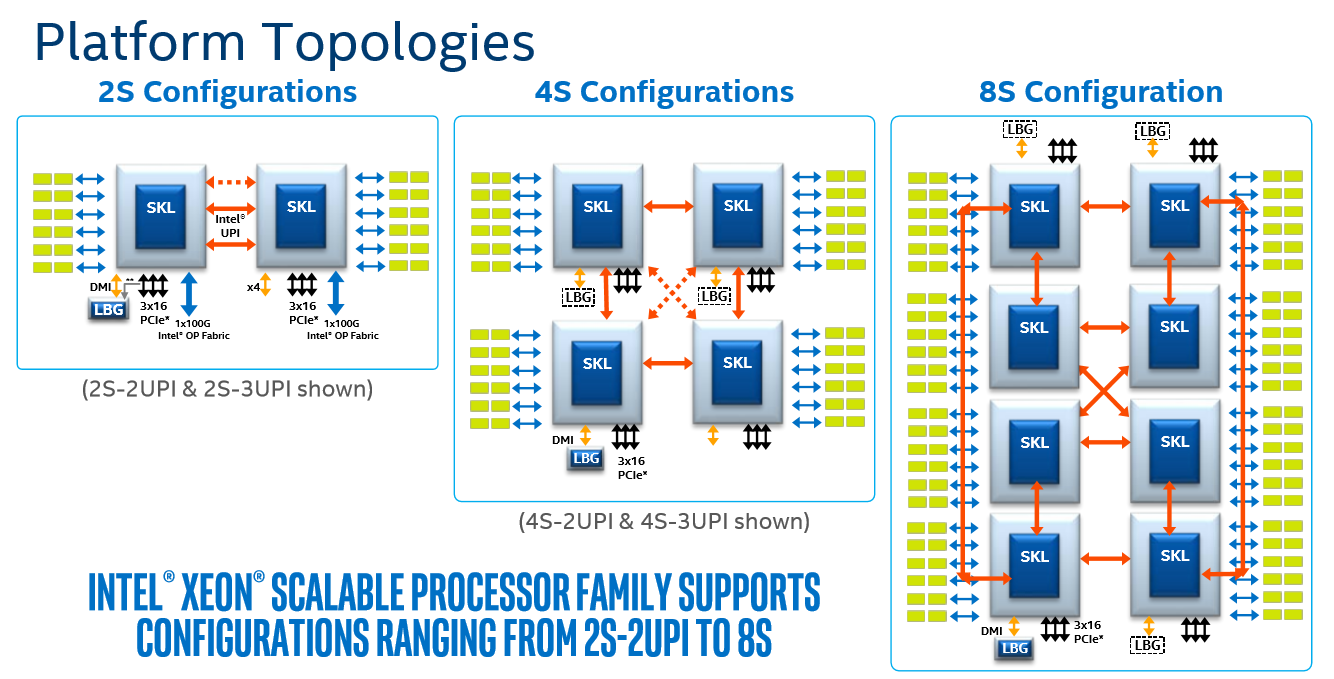
The Intel chip is indeed able to scale up in 8 sockets systems, but frankly that market is shrinking fast, and dual socket buyers could not care less.
Meanwhile, although we have yet to test it, AMD's single socket offering looks even more attractive. We estimate that a single EPYC 7551P would indeed outperform many of the dual Silver Xeon solutions. Overall the single-socket EPYC gives you about 8 cores more at similar clockspeeds than the 2P Intel, and AMD doesn't require explicit cross socket communication - the server board gets simpler and thus cheaper. For price conscious server buyers, this is an excellent option.
However, if your software is expensive, everything changes. In that case, you care less about the heavy price tags of the Platinum Xeons. For those scenarios, Intel's Skylake-EP Xeons deliver the highest single threaded performance (courtesy of the 3.8 GHz turbo clock), high throughput without much (hardware) tuning, and server managers get the reassurance of Intel's reliable track record. And if you use expensive HPC software, you will probably get the benefits of Intel's beefy AVX 2.0 and/or AVX-512 implementations.
The second consideration is the type of buyer. It is clear that you have to tune more and work harder to get the best performance out of AMD EPYC CPUs. In many ways it is basically a "virtual octal socket" solution. For enterprises with a small infrastructure crew and server hardware on premise, spending time on hardware tuning is not an option most of the time. For the cloud vendors, the knowledge will be available and tuning for EPYC will be a one-time investment. Microsoft is already deploying AMD's EPYC in their Azure Cloud Datacenters.
Looking Towards the Future
Looking towards the future, Intel has the better topology to add more cores in future CPU generations. However AMD's newest core is a formidable opponent. Scalar floating point operations are clearly faster on the AMD core, and integer performance is – at the same clock – on par with Intel's best. The dual CCX layout and quad die setup leave quite a bit of performance on the table, so it will be interesting how much AMD has learned from this when they launch the 7 nm "Rome" successor. Their SKU line-up is still very limited.

All in all, it must be said that AMD executed very well and delivered a new server CPU that can offer competitive performance for a lower price point in some key markets. Server customers with non-scalar sparse matrix HPC and Big Data applications should especially take notice.
As for Intel, the company has delivered a very attractive and well scaling product. But some of the technological advances in Skylake-SP are overshadowed by the heavy price tags and somewhat "over the top" market segmentation.








219 Comments
View All Comments
psychobriggsy - Tuesday, July 11, 2017 - link
Indeed it is a ridiculous comment, and puts the earlier crying about the older Ubuntu and GCC into context - just an Intel Fanboy.In fact Intel's core architecture is older, and GCC has been tweaked a lot for it over the years - a slightly old GCC might not get the best out of Skylake, but it will get a lot. Zen is a new core, and GCC has only recently got optimisations for it.
EasyListening - Wednesday, July 12, 2017 - link
I thought he was joking, but I didn't find it funny. So dumb.... makes me sad.blublub - Tuesday, July 11, 2017 - link
I kinda miss Infinity Fabric on my Haswell CPU and it seems to only have on die - so why is that missing on Haswell wehen Ryzen is an exact copy?blublub - Tuesday, July 11, 2017 - link
Your actually sound similar to JuanRGA at SAKevin G - Wednesday, July 12, 2017 - link
@CajunArson The cache hierarchy is radically different between these designs as well as the port arrangement for dispatch. Scheduling on Ryzen is split between execution resources where as Intel favors a unified approach.bill.rookard - Tuesday, July 11, 2017 - link
Well, that is something that could be figured out if they (anandtech) had more time with the servers. Remember, they only had a week with the AMD system, and much like many of the games and such, optimizing is a matter of run test, measure, examine results, tweak settings, rinse and repeat. Considering one of the tests took 4 hours to run, having only a week to do this testing means much of the optimization is probably left out.They went with a 'generic' set of relative optimizations in the interest of time, and these are the (very interesting) results.
CoachAub - Wednesday, July 12, 2017 - link
Benchmarks just need to be run on as level as a field as possible. Intel has controlled the market so long, software leans their way. Who was optimizing for Opteron chips in 2016-17? ;)theeldest - Tuesday, July 11, 2017 - link
The compiler used isn't meant to be the the most optimized, but instead it's trying to be representative of actual customer workloads.Most customer applications in normal datacenters (not google, aws, azure, etc) are running binaries that are many years behind on optimizations.
So, yes, they can get better performance. But using those optimizations is not representative of the market they're trying to show numbers for.
CajunArson - Tuesday, July 11, 2017 - link
That might make a tiny bit of sense if most of the benchmarks run were real-world workloads and not C-Ray or POV-Ray.The most real-world benchmark in the whole setup was the database benchmark.
coder543 - Tuesday, July 11, 2017 - link
The one benchmark that favors Intel is the "most real-world"? Absolutely, I want AnandTech to do further testing, but your comments do not sound unbiased.