Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Memory Subsystem: Bandwidth
Measuring the full bandwidth potential with John McCalpin's Stream bandwidth benchmark is getting increasingly difficult on the latest CPUs, as core and memory channel counts have continued to grow. We compiled the stream 5.10 source code with the Intel compiler (icc) for linux version 17, or GCC 5.4, both 64-bit. The following compiler switches were used on icc:
icc -fast -qopenmp -parallel (-AVX) -DSTREAM_ARRAY_SIZE=800000000
Notice that we had to increase the array significantly, to a data size of around 6 GB. We compiled one version with AVX and one without.
The results are expressed in gigabytes per second.
Meanwhile the following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=800000000
Notice that the DDR4 DRAM in the EPYC system ran at 2400 GT/s (8 channels), while the Intel system ran its DRAM at 2666 GT/s (6 channels). So the dual socket AMD system should theoretically get 307 GB per second (2.4 GT/s* 8 bytes per channel x 8 channels x 2 sockets). The Intel system has access to 256 GB per second (2.66 GT/s* 8 bytes per channel x 6 channels x 2 sockets).
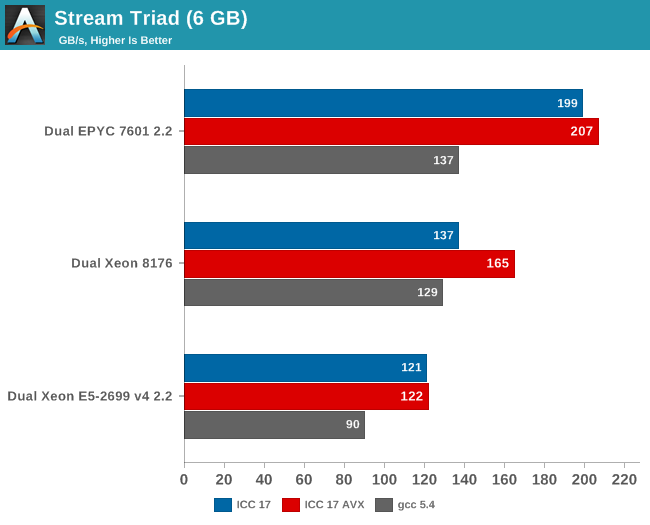
AMD told me they do not fully trust the results from the binaries compiled with ICC (and who can blame them?). Their own fully customized stream binary achieved 250 GB/s. Intel claims 199 GB/s for an AVX-512 optimized binary (Xeon E5-2699 v4: 128 GB/s with DDR-2400). Those kind of bandwidth numbers are only available to specially tuned AVX HPC binaries.
Our numbers are much more realistic, and show that given enough threads, the 8 channels of DDR4 give the AMD EPYC server a 25% to 45% bandwidth advantage. This is less relevant in most server applications, but a nice bonus in many sparse matrix HPC applications.
Maximum bandwidth is one thing, but that bandwidth must be available as soon as possible. To better understand the memory subsystem, we pinned the stream threads to different cores with numactl.
| Pinned Memory Bandwidth (in MB/sec) | |||
| Mem Hierarchy |
AMD "Naples" EPYC 7601 DDR4-2400 |
Intel "Skylake-SP" Xeon 8176 DDR4-2666 |
Intel "Broadwell-EP" Xeon E5-2699v4 DDR4-2400 |
| 1 Thread | 27490 | 12224 | 18555 |
| 2 Threads, same core same socket |
27663 | 14313 | 19043 |
| 2 Threads, different cores same socket |
29836 | 24462 | 37279 |
| 2 Threads, different socket | 54997 | 24387 | 37333 |
| 4 threads on the first 4 cores same socket |
29201 | 47986 | 53983 |
| 8 threads on the first 8 cores same socket |
32703 | 77884 | 61450 |
| 8 threads on different dies (core 0,4,8,12...) same socket |
98747 | 77880 | 61504 |
The new Skylake-SP offers mediocre bandwidth to a single thread: only 12 GB/s is available despite the use of fast DDR-4 2666. The Broadwell-EP delivers 50% more bandwidth with slower DDR4-2400. It is clear that Skylake-SP needs more threads to get the most of its available memory bandwidth.
Meanwhile a single thread on a Naples core can get 27,5 GB/s if necessary. This is very promissing, as this means that a single-threaded phase in an HPC application will get abundant bandwidth and run as fast as possible. But the total bandwidth that one whole quad core CCX can command is only 30 GB/s.
Overall, memory bandwidth on Intel's Skylake-SP Xeon behaves more linearly than on AMD's EPYC. All off the Xeon's cores have access to all the memory channels, so bandwidth more directly increases with the number of threads.








219 Comments
View All Comments
ddriver - Tuesday, July 11, 2017 - link
Gotta love the "you don't care about the xeon prices" part thou. Now that intel don't have a performance advantage, and their product value at the high end is half that of amd, AT plays the "intel is the better brand" card. So expected...OZRN - Wednesday, July 12, 2017 - link
You need some perspective. Database licensing for Oracle happens per core, where Intel's performance is frequently better in a straight line and since they achieve it on lower core count it's actually better value for the use case. Higher per-CPU cost is not so much of a concern when you pay twice as much for a processor license to cover those cores.I'm an AMD fan and I made this account just for you, sweetheart, but don't blind yourself to the truth just because Intel has a history of shady business. In most regards this is a balanced review, and where it isn't, they tell you why it might not be. Chill out.
ddriver - Thursday, July 13, 2017 - link
You are such a clown. Nobody, I repeat, NOBODY on this planet uses 64 core 128 thread 512 gigabytes of ram servers to run a few MB worth of database. You telling me to get pespective thus can mean only two things, that you are a buthurt intel fanboy troll or that you are in serious need of head examination. Or maybe even both. At any rate, that perfectly explains your ridiculously low standards for "balanced review".Notmyusualid - Friday, July 14, 2017 - link
It seems no matter what opinion someone presents that might exhibit Intel in a better light - you are going to hate it anyway.What a life you must lead.
OZRN - Friday, July 14, 2017 - link
No, they don't. They use them to host gigabytes to terabytes worth of mission critical databases, with specified amounts of cores dedicated to seperate environments of hard partitioned data manipulation. I've done some quick math for you and in an average setup of Enterprise Edition of Oracle DB, with only the usually reported options and extras, this type of database would cost over $3.7m to run on *64 cores alone*. At this point, where is your hardware sunk costs argument?Also, I don't think anyone here is impressed by your ability to immediately personally insult people making valid points. Good luck finding your head that deep in your colon.
CajunArson - Tuesday, July 11, 2017 - link
"All of our testing was conducted on Ubuntu Server "Xenial" 16.04.2 LTS (Linux kernel 4.4.0 64 bit). The compiler that ships with this distribution is GCC 5.4.0."I'd recommend using a more updated distro and especially a more up to date compiler (GCC 5.4 is only a bug-fix release of a compiler from *2015*) if you want to see what these parts are truly capable of.
Phoronix does heavy-duty Linux reviews and got some major performance boosts on the i9 7900X simply by using up to date distros: http://www.phoronix.com/scan.php?page=article&...
Considering that Purley is just an upscaled version of the i9 7900X, I wouldn't be surprised to see different results.
CajunArson - Tuesday, July 11, 2017 - link
As a followup to my earlier comment, that Phoronix story, for example, shows a speedup factor of almost 5X on the C-ray benchmark simply by using a modern distro with some tuning for the more modern Skylake architecture.I'm not saying Purley would have a 5X speedup on C-ray per-say, but I'd be shocked if it didn't get a good boost using modern software that's actually designed for the Skylake architecture.
CoachAub - Wednesday, July 12, 2017 - link
Keywords: "actually designed for the Skylake architecture". Will there be optimizations for AMD Epyc chips?mkozakewich - Friday, July 14, 2017 - link
If it's a reasonable optimization, it makes sense to include it in the benchmark. If I were building these systems, I'd want to see benchmarks that resembled as closely as possible my company's workflow. (Which may be for older software or newer software; neither are inherently more relevant, though benchmarks on newer software will usually be relevant further into the future.)CajunArson - Tuesday, July 11, 2017 - link
And another followup: The time kernel compilation on the i9 7900X got almost a factor of 2 speedup over the Ubuntu 16.04 using more modern distros.