Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Memory Subsystem: Bandwidth
Measuring the full bandwidth potential with John McCalpin's Stream bandwidth benchmark is getting increasingly difficult on the latest CPUs, as core and memory channel counts have continued to grow. We compiled the stream 5.10 source code with the Intel compiler (icc) for linux version 17, or GCC 5.4, both 64-bit. The following compiler switches were used on icc:
icc -fast -qopenmp -parallel (-AVX) -DSTREAM_ARRAY_SIZE=800000000
Notice that we had to increase the array significantly, to a data size of around 6 GB. We compiled one version with AVX and one without.
The results are expressed in gigabytes per second.
Meanwhile the following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=800000000
Notice that the DDR4 DRAM in the EPYC system ran at 2400 GT/s (8 channels), while the Intel system ran its DRAM at 2666 GT/s (6 channels). So the dual socket AMD system should theoretically get 307 GB per second (2.4 GT/s* 8 bytes per channel x 8 channels x 2 sockets). The Intel system has access to 256 GB per second (2.66 GT/s* 8 bytes per channel x 6 channels x 2 sockets).
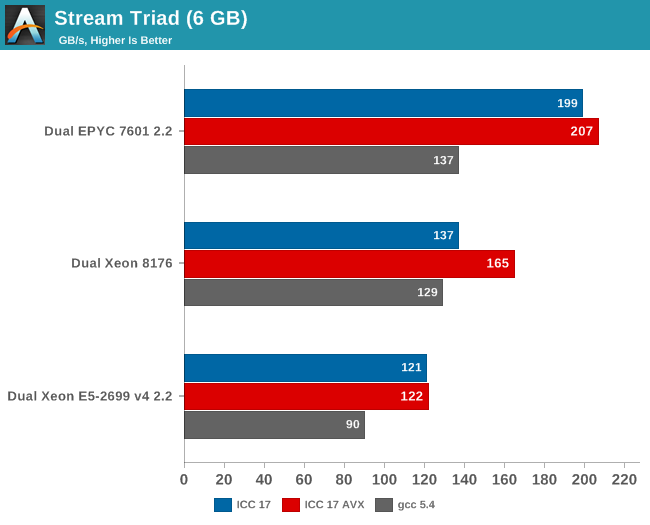
AMD told me they do not fully trust the results from the binaries compiled with ICC (and who can blame them?). Their own fully customized stream binary achieved 250 GB/s. Intel claims 199 GB/s for an AVX-512 optimized binary (Xeon E5-2699 v4: 128 GB/s with DDR-2400). Those kind of bandwidth numbers are only available to specially tuned AVX HPC binaries.
Our numbers are much more realistic, and show that given enough threads, the 8 channels of DDR4 give the AMD EPYC server a 25% to 45% bandwidth advantage. This is less relevant in most server applications, but a nice bonus in many sparse matrix HPC applications.
Maximum bandwidth is one thing, but that bandwidth must be available as soon as possible. To better understand the memory subsystem, we pinned the stream threads to different cores with numactl.
| Pinned Memory Bandwidth (in MB/sec) | |||
| Mem Hierarchy |
AMD "Naples" EPYC 7601 DDR4-2400 |
Intel "Skylake-SP" Xeon 8176 DDR4-2666 |
Intel "Broadwell-EP" Xeon E5-2699v4 DDR4-2400 |
| 1 Thread | 27490 | 12224 | 18555 |
| 2 Threads, same core same socket |
27663 | 14313 | 19043 |
| 2 Threads, different cores same socket |
29836 | 24462 | 37279 |
| 2 Threads, different socket | 54997 | 24387 | 37333 |
| 4 threads on the first 4 cores same socket |
29201 | 47986 | 53983 |
| 8 threads on the first 8 cores same socket |
32703 | 77884 | 61450 |
| 8 threads on different dies (core 0,4,8,12...) same socket |
98747 | 77880 | 61504 |
The new Skylake-SP offers mediocre bandwidth to a single thread: only 12 GB/s is available despite the use of fast DDR-4 2666. The Broadwell-EP delivers 50% more bandwidth with slower DDR4-2400. It is clear that Skylake-SP needs more threads to get the most of its available memory bandwidth.
Meanwhile a single thread on a Naples core can get 27,5 GB/s if necessary. This is very promissing, as this means that a single-threaded phase in an HPC application will get abundant bandwidth and run as fast as possible. But the total bandwidth that one whole quad core CCX can command is only 30 GB/s.
Overall, memory bandwidth on Intel's Skylake-SP Xeon behaves more linearly than on AMD's EPYC. All off the Xeon's cores have access to all the memory channels, so bandwidth more directly increases with the number of threads.








219 Comments
View All Comments
twtech - Thursday, July 20, 2017 - link
I'd really like to see some compile-time benchmarks for these CPUs.For my own particular interests, time taken to do a full recompile of the Unreal 4 engine from source would be very useful. But even something more generic like the Linux kernel compiles per hour benchmark could serve as a useful point of reference.
szupek - Friday, July 21, 2017 - link
Meanwhile, the entire world still runs on IBM's DB2 for Datbases and IBM's Z/AS400 Mainframes. The fastest database in the world, by far...oh and the most secure (it's only hackable by standing in front of the console, seriously). Every single credit card transaction. Every single plain ticket. Most medical records and all of wall street. Yup. IBM still owns. So much that most of commenters probably have no idea just how big IBM truly is. If you care about Database speed & security, these processors shouldn't appeal to you.stevefan1999 - Saturday, July 22, 2017 - link
It's impossible for AMD to win completely.Remember kids, public cloud service providers such as Amazon(AWS), Google(GCP) and Joyent would still stick with Intel due to not only the compatibility issues like ecosystem and vendor inconsistency, but also the VM migration and security and module issues, all mentioned in the presentation slides presented by Intel. They are a very serious matter, as they, the public cloud services, are powering the Internet we use everyday, so being stable, consistent and be able to serve a good amount of SLA is vital to the public cloud, we wouldn't expect them to play with the new lad in the hood, the EPYC.
IIRC only the Microsoft(Azure) are using AMD server CPUs partially in some of their datacenters, running various Linux and Windows VMs using Hyper-V, and they have been performing quite well
The cloud services are exploding every year, but with what I've said, I doubt AMD could even kick in the first door at least for 3 to 4 years. This is still a big-win for Intel and what manipulations will Intel do I don't know.
On the other hand, Intel has failed to service the desktop market and they're figuring out how to hold their asses on the Internet infrastructure, never had them know the crusade of EPYC will come this fast.
The server market is quite a big meat, it's a 21 bil market, cool right? But that you will have guaranteed 'server upgrade' every year, is a bigger matter, as those server CPUs are designated to be disposed given the wattage and performance per dollar is lower on the newer CPUs. Those god-damn server operators will keen to replace their CPU (and therefore some serious metal pollution issues). Intel has been exploiting this and gained a big hurdle of money and therefore had their ecosystem grown. This is how Intel defends their platform by vendor lock-in, pathetic.
AMD is now being performance and cost competitive to Intel, but it's still dead in the High Performance Computing campaign unless AMD could provide higher frequencies. Well I have to say I know nothing about HPC, but I remembered the Bulldozer architecture of AMD is actually targeted and marketed for HPC! That's why AMD failed in general-purpose computing market and started the downfall of AMD/Domination of Intel 5 years ago. Even though we know the fate of Bulldozer, but hopefully AMD could still scrap some of the HPC goodies of Bulldozer out and benefits the mankind by accelerating researches such as finding the cures for cancer or solving some precise physics and mathematics.
Well, anyway the cloud, the HPC and the server market are the last resort for Intel and they will definitely hold their last ground. Good luck AMD on crushing the mean and obese Intel!
errorr - Sunday, July 23, 2017 - link
For all the talk about speed and efficiency the problem is about $$$. The sad fact is that what matters most isn't even the price of the cpus which is chump change in the grand scheme of things but how the software licensing costs are determined. Per core or per socket software pricing will matter a lot. The software companies will decide how successful EPYC is. I have a feeling they will be biased slightly toward AMD at the beginning as it is in their interest to foster competition for Intel, or if they are not forward looking enough the end customers might argue that the competition will benefit the SW companies in the long run by continuing to push competition.msroadkill612 - Thursday, July 27, 2017 - link
Whatever, its all pointless if the competition can read your secrets, which is a matter very close to the hearts of the cheque signers.AMD seem to have something very superior to offer in that department.
qweqwe - Tuesday, August 8, 2017 - link
we just did some heavy inhouse hpc-tests with epyc against diff. intel servers.the epyc is the clear winner in terms of performance and power consumption when it
comes to hand-tuned parallel-vector-code examples.
not bad amd !
readonly1 - Friday, October 27, 2017 - link
qweqwe, I totally agree with you. Our inhouse HPC tests get the similar conclusion, after comparing AMD Epyc 7351 (dual socket, 32 cores, 2400Mhz) and Intel SKylake 6154 (dual socket, 36 cores, 3000Mhz). I think AMD clearly wins in the memory bandwidth, which is extremely important for HPC computation.msroadkill612 - Monday, November 13, 2017 - link
7/11/2017 "Microsoft is already deploying AMD's EPYC in their Azure Cloud Datacenters."Interesting. As i have been theorising, a possible reason for the absence of retail epyc is not supply, but demand.
A single sale can soak up production runs.
If so tho, not much sign of big revenues from it yet, but there are other explanations for that. Contra processors for development work e.g.
q.epsilon.p - Sunday, June 10, 2018 - link
power consumption numbers with every benchmark would have been nice, because these parts are server benchmarks, Perf / Watt is one of the primary concerns. And where AMD kinda crush Intel, because it's isn't exactly being honest with it's TDP values nowadays when it comes to Data Centre and HEDT.TDP was traditionally the absolute maximum the CPU would put out as heat, now with a power consumption of 670W I am assuming that the heat being put out by the CPU is more than 165W.