Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Intel's New On-Chip Topology: A Mesh
Since the introduction of the "Nehalem" CPU architecture – and the Xeon 5500 that started almost a decade-long reign for Intel in the datacenter – Intel's engineers have relied upon a low latency, high bandwidth ring to connect their cores with their caches, memory controllers, and I/O controllers.
Intel's most recent adjustment to their ring topology came with the Ivy Bridge-EP (Xeon E5 2600 v2) family of CPUs. The top models were the first with three columns of cores connected by a dual ring bus, which utilized both outer and inner rings. The rings moved data in opposite directions (clockwise/counter-clockwise) in order to minimize latency by allowing data to take the shortest path to the destination. As data is brought onto the ring infrastructure, it must be scheduled so that it does not collide with previous data.
The ring topology had a lot of advantages. It ran very fast, up to 3 GHz. As result, the L3-cache latency was pretty low: if the core is lucky enough to find the data in its own cache slice, only one extra cycle is needed (on top of the normal L1-L2-L3 latency). Getting a cacheline of another slice can cost up to 12 cycles, with an average cost of 6 cycles.
However the ring model started show its limits on the high core count versions of the Xeon E5 v3, which had no less than four columns of cores and LLC slices, making scheduling very complicated: Intel had to segregate the dual ring buses and integrate buffered switches. Keeping cache coherency performant also became more and more complex: some applications gained quite a bit of performance by choosing the right snoop filter mode (or alternatively, lost a lot of performance if they didn't pick the right mode). For example, our OpenFOAM benchmark performance improved by almost 20% by choosing "Home Snoop" mode, while many easy to scale, compute-intensive applications preferred "Cluster On Die" snooping mode.
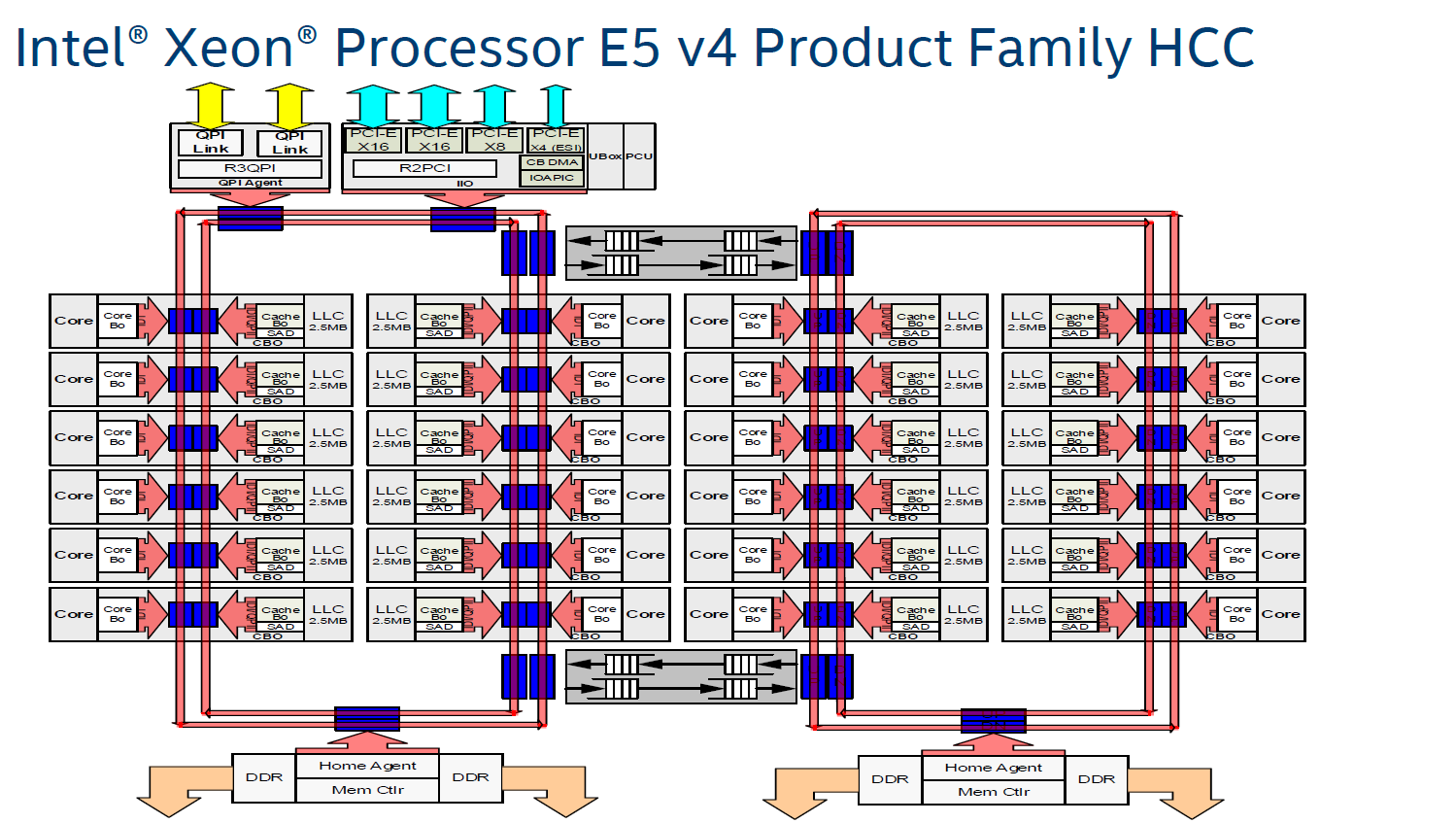
In other words, placing 22 (E7:24) cores, several PCIe controllers, and several memory controllers was close to the limit what a dual ring could support. In order to support an even larger number of cores than the Xeon v4 family, Intel would have to add a third ring, and ultimately connecting 3 rings with 6 columns of cores each would be overly complex.
Given that, it shouldn't come as a surprise that Intel's engineers decided to use a different topology for Skylake-SP to connect up to 28 cores with the "uncore." Intel's new solution? A mesh architecture.
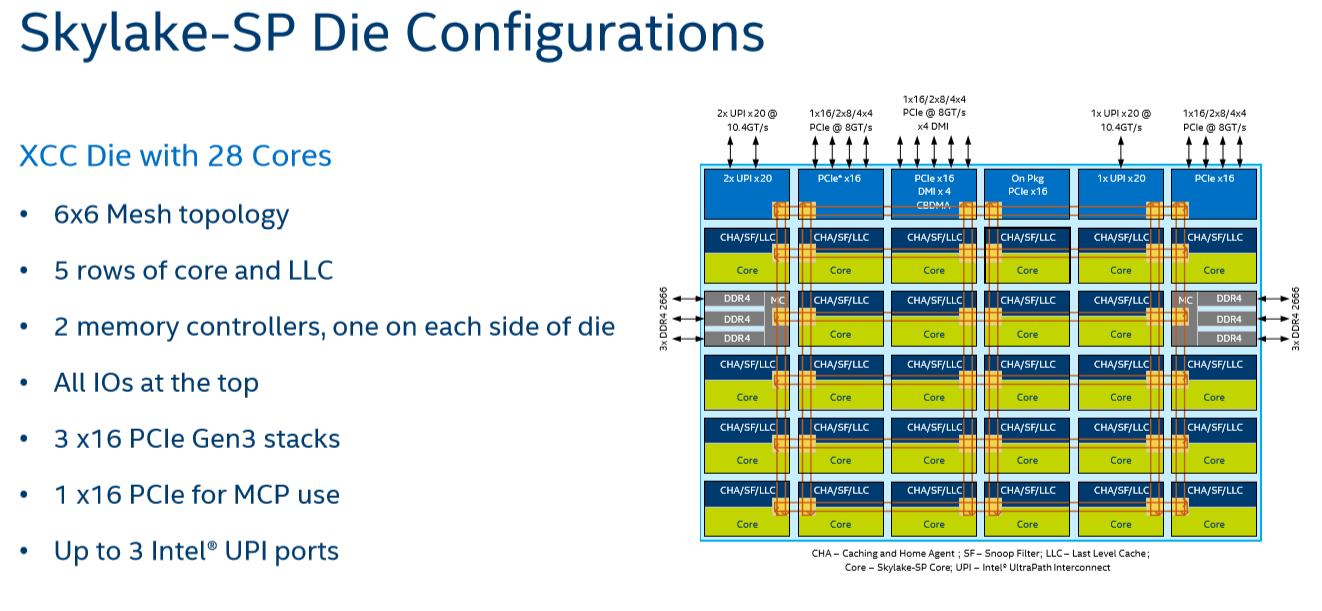
Under Intel's new topology, each node – a caching/home agent, a core, and a chunk of LLC – is interconnected via a mesh. Conceptually it is very similar to the mesh found on Xeon Phi, but not quite the same. In the long-run the mesh is far more scalable than Intel's previous ring topology, allowing Intel to connect many more nodes in the future.
How does it compare to the ring architecture? The Ring could run at up to 3 GHz, while the current mesh and L3-cache runs at at between 1.8GHZ and 2.4GHz. On top of that, the mesh inside the top Skylake-SP SKUs has to support more cores, which further increases the latency. Still, according to Intel the average latency to the L3-cache is only 10% higher, and the power usage is lower.

A core that access an L3-cache slice that is very close (like the ones vertically above each other) gets an additional latency of 1 cycle per hop. An access to a cache slice that is vertically 2 hops away needs 2 cycles, and one that is 2 hops away horizontally needs 3 cycles. A core from the bottom that needs to access a cache slice at the top needs only 4 cycles. Horizontally, you get a latency of 9 cycles at the most. So despite the fact that this Mesh connects 6 extra cores verse Broadwell-EP, it delivers an average latency in the same ballpark (even slightly better) as the former's dual ring architecture with 22 cores (6 cycles average).
Meanwhile the worst case scenario – getting data from the right top node to the bottom left node – should demand around 13 cycles. And before you get too concerned with that number, keep in mind that it compares very favorably with any off die communication that has to happen between different dies in (AMD's) Multi Chip Module (MCM), with the Skylake-SP's latency being around one-tenth of EPYC's. It is crystal clear that there will be some situations where Intel's server chip scales better than AMD's solution.
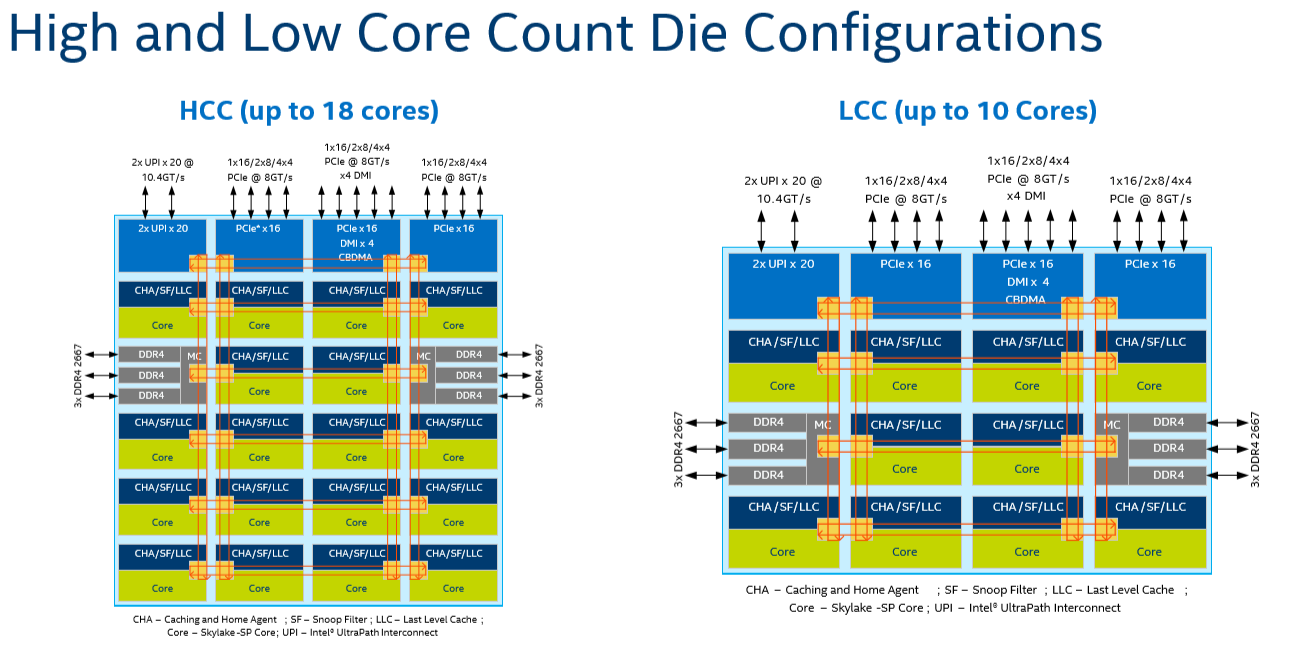
There are other advantages that help Intel's mesh scale: for example, caching and home agents are now distributed, with each core getting one. This reduces snoop traffic and reduces snoop latency. Also, the number of snoop modes is reduced: no longer do you need to choose between home snoop or early snoop. A "cluster-on-die" mode is still supported: it is now called sub-NUMA Cluster or SNC. With SNC you can divide the huge Intel server chips into two NUMA domains to lower the latency of the LLC (but potentially reduce the hitrate) and limit the snoop broadcasts to one SNC domain.








219 Comments
View All Comments
Shankar1962 - Thursday, July 13, 2017 - link
So you think Intel won't release anything new again by then? Intel would be ready for cascadelake by then. None of the big players won't switch to AMD. Skylake alone is enough to beat epyc handsomely and cascadelake will just blow epyc. Its funny people are looking at lab results when real workloads are showing 1.5-1.7x speed improvementPixyMisa - Saturday, July 15, 2017 - link
This IS comparing AMD to Intel's newest CPUs, you idiot. Skylake loses to Epyc outright on many workloads, and is destroyed by Epyc on TCO.Shankar1962 - Sunday, July 16, 2017 - link
Mind your language assholeEither continue the debate or find another place for your shit and ur language
Real workloads don't happen in the labs you moron
Real workloads are specific to each company and Intel is ahead either way
If you have the guts come out with Q3 Q4 2017 and 2018 revenues from AMD
If you come back debating epyc won over skylake if AMD gets 5-10% share then i pity your common sense and your analysis
You are a bigger idiot because you spoiled a healthy thread where people were taking sides by presenting technical perspective
PixyMisa - Tuesday, July 25, 2017 - link
I'm sorry you're an idiot.Shankar1962 - Thursday, July 13, 2017 - link
Does not matter. We can debate this forever but Intel is just ahead and better optimized for real world workloads. Nvidia i agree is a potential threat and ahead in AI workloads which is the future but AMD is just an unnecessary hype. Since the fan boys are so excited with lab results (funny) lets look at Q3,Q4 results to see how many are ordering to test it for future deployment.martinpw - Wednesday, July 12, 2017 - link
I'm curious about the clock speed reduction with AVX-512. If code makes use of these instructions and gets a speedup, will all other code slow down due to lower overall clock speeds? In other words, how much AVX-512 do you have to use before things start clocking down? It feels like it might be a risk that AVX-512 may actually be counterproductive if not used heavily.msroadkill612 - Wednesday, July 12, 2017 - link
(sorry if a repost)Well yeah, but this is where it starts getting weird - 4-6 vega gpuS, hbm2 ram & huge raid nvme , all on the second socket of your 32 core, c/gpu compute ~Epyc server:
https://marketrealist.imgix.net/uploads/2017/07/A1...
from
http://marketrealist.com/2017/07/how-amd-plans-to-...
All these fabric linked processors, can interact independently of the system bus. Most data seems to get point to point in 2 hops, at about 40GBps bi-directional (~40 pcie3 lanes, which would need many hops), and can be combined to 160GBps - as i recall.
Suitably custom hot rodded for fabric rather than pcie3, the nvme quad arrays could reach 16MBps sequential imo on epycs/vegaS native nvme ports.
To the extent that gpuS are increasing their role in big servers, intel and nvidea simply have no answer to amd in the bulk of this market segment.
davide445 - Wednesday, July 12, 2017 - link
Finally real competition in the HPC market. Waiting for the next top500 AMD powered supercomputer.Shankar1962 - Wednesday, July 12, 2017 - link
Intel makes $60billion a year and its official that Skylake was shipping from Feb17 so i do not understand this excitement from AMD fan boys......if it is so good can we discuss the quarterly revenues between these companies? Why is AMD selling for very low prices when you claim superior performance over Intel? You can charge less but almost 40-50% cheap compared to Intel really?AMD exists because they are always inferior and can beat Intel only by selling for low prices and that too for what gaining 5-10% market which is just a matter of time before Intel releases more SKUs to grab it back
What about the software optimizations and extra BOM if someone switches to AMD?
What if AMD goes into hibernation like they did in last 5-6years?
Can you mention one innovation from AMD that changed the world?
Intel is a leader and all the technology we enjoy today happenned because of Intel technology.
Intel is a data center giant have head start have the resources money acquisitions like altera mobileeye movidus infineon nirvana etc and its just impossible that they will lose
Even if all the competent combines Intel will maintain atleast 80% share even 10years from now
Shankar1962 - Wednesday, July 12, 2017 - link
To add onNo one cares about these lab tests. Let's talk about the real world work loads.
Look at what Google AWS ATT etc has to say as they already switched to xeon sky lake
We should not really be debating if we have the clarity that we are talking about AMD getting just 5% -10% share by selling high end products they have for cheap prices....they fo not make too much money by doing that.....they have no other option as thats the only way they can dream of a 5-10% market share
For Analogy think Intel in semiconductor as Apple in selling smartphones
Intel has gross margins of ~63%
They have a solid product portfolio technologies and roadmap .....we can debate this forever but the revenues profits innovations and history between these companies can answer everything