Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Floating Point
Normally our HPC benchmarking is centered around OpenFoam, a CFD software we have used for a number of articles over the years. However, since we moved to Ubuntu 16.04, we could not get it to work anymore. So we decided to change our floating point intensive benchmark for now. For our latest article, we're testing with C-ray, POV-Ray, and NAMD.
The idea is to measure:
- A FP benchmark that is running out of the L1 (C-ray)
- A FP benchmark that is running out of the L2 (POV-Ray)
- And one that is using the memory subsytem quite often (NAMD)
Floating Point: C-ray
C-ray is an extremely simple ray-tracer which is not representative of any real world raytracing application. In fact, it is essentially a floating point benchmark that runs out of the L1-cache. Luckily it is not as synthetic and meaningless as Whetstone, as you can actually use the software to do simple raytracing.
We use the standard benchmarking resolution (3840x2160) and the "sphfract" file to measure performance. The binary was precompiled.
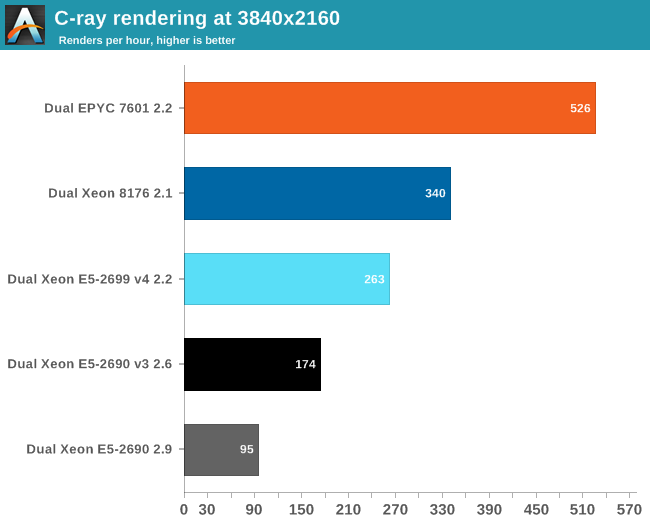
Wow. What just happened? It looks like a landslide victory for the raw power of the four FP pipes of Zen: the EPYC chip is no less than 50% faster than the competition. Of course, it is easy to feed FP units if everything resides in the L1. Next stop, POV-Ray.
Floating Point: POV-Ray 3.7
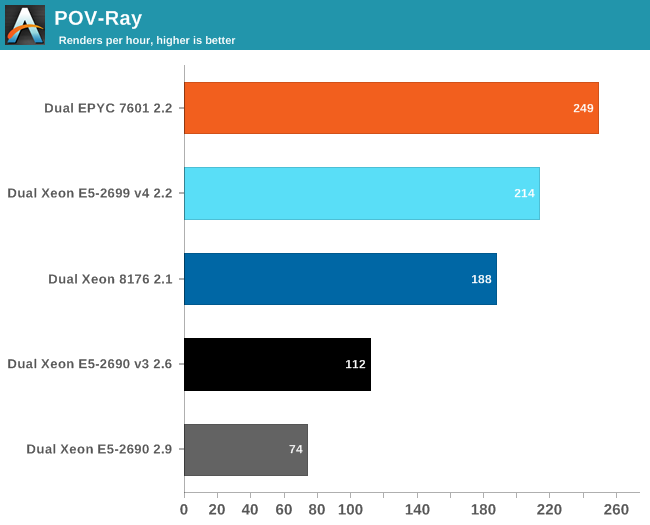
POV-Ray is known to run mostly out of the L2-cache, so the massive DRAM bandwidth of the EPYC CPU does not play a role here. Nevertheless, the EPYC CPU performance is pretty stunning: about 16% faster than Intel's Xeon 8176. But what if AVX and DRAM access come in to play? Let us check out NAMD.
Floating Point: NAMD
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization on thousands of cores. NAMD is also part of SPEC CPU2006 FP. In contrast with previous FP benchmarks, the NAMD binary is compiled with Intel ICC and optimized for AVX.
First, we used the "NAMD_2.10_Linux-x86_64-multicore" binary. We used the most popular benchmark load, apoa1 (Apolipoprotein A1). The results are expressed in simulated nanoseconds per wall-clock day. We measure at 500 steps.
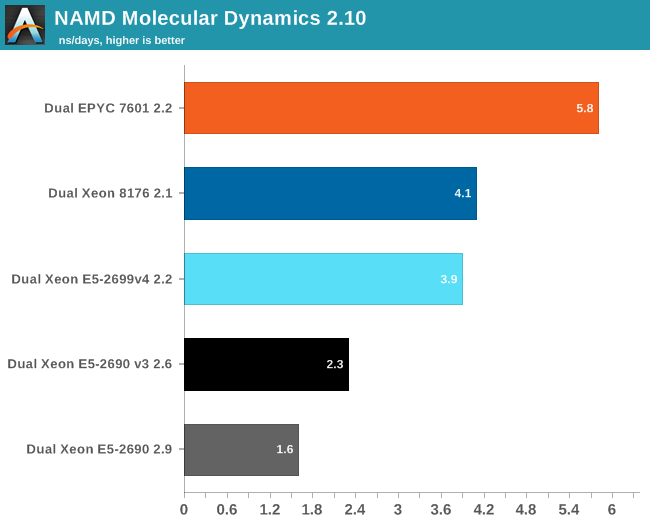
Again, the EPYC 7601 simply crushes the competition with 41% better performance than Intel's 28-core. Heavily vectorized code (like Linpack) might run much faster on Intel, but other FP code seems to run faster on AMD's newest FPU.
For our first shot with this benchmark, we used version 2.10 to be able to compare to our older data set. Version 2.12 seems to make better use of "Intel's compiler vectorization and auto-dispatch has improved performance for Intel processors supporting AVX instructions". So let's try again:
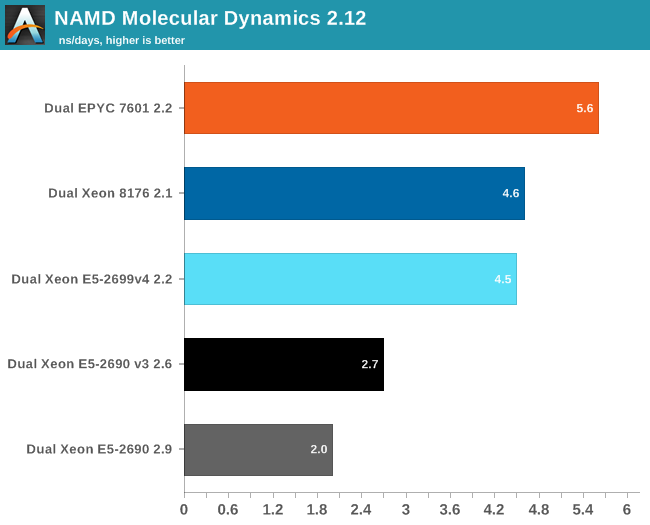
The older Xeons see a perforance boost of about 25%. The improvement on the new Xeons is a lot lower: about 13-15%. Remarkable is that the new binary is slower on the EPYC 7601: about 4%. That simply begs for more investigation: but the deadline was too close. Nevertheless, three different FP tests all point in the same direction: the Zen FP unit might not have the highest "peak FLOPs" in theory, there is lots of FP code out there that runs best on EPYC.








219 Comments
View All Comments
Shankar1962 - Thursday, July 13, 2017 - link
So you think Intel won't release anything new again by then? Intel would be ready for cascadelake by then. None of the big players won't switch to AMD. Skylake alone is enough to beat epyc handsomely and cascadelake will just blow epyc. Its funny people are looking at lab results when real workloads are showing 1.5-1.7x speed improvementPixyMisa - Saturday, July 15, 2017 - link
This IS comparing AMD to Intel's newest CPUs, you idiot. Skylake loses to Epyc outright on many workloads, and is destroyed by Epyc on TCO.Shankar1962 - Sunday, July 16, 2017 - link
Mind your language assholeEither continue the debate or find another place for your shit and ur language
Real workloads don't happen in the labs you moron
Real workloads are specific to each company and Intel is ahead either way
If you have the guts come out with Q3 Q4 2017 and 2018 revenues from AMD
If you come back debating epyc won over skylake if AMD gets 5-10% share then i pity your common sense and your analysis
You are a bigger idiot because you spoiled a healthy thread where people were taking sides by presenting technical perspective
PixyMisa - Tuesday, July 25, 2017 - link
I'm sorry you're an idiot.Shankar1962 - Thursday, July 13, 2017 - link
Does not matter. We can debate this forever but Intel is just ahead and better optimized for real world workloads. Nvidia i agree is a potential threat and ahead in AI workloads which is the future but AMD is just an unnecessary hype. Since the fan boys are so excited with lab results (funny) lets look at Q3,Q4 results to see how many are ordering to test it for future deployment.martinpw - Wednesday, July 12, 2017 - link
I'm curious about the clock speed reduction with AVX-512. If code makes use of these instructions and gets a speedup, will all other code slow down due to lower overall clock speeds? In other words, how much AVX-512 do you have to use before things start clocking down? It feels like it might be a risk that AVX-512 may actually be counterproductive if not used heavily.msroadkill612 - Wednesday, July 12, 2017 - link
(sorry if a repost)Well yeah, but this is where it starts getting weird - 4-6 vega gpuS, hbm2 ram & huge raid nvme , all on the second socket of your 32 core, c/gpu compute ~Epyc server:
https://marketrealist.imgix.net/uploads/2017/07/A1...
from
http://marketrealist.com/2017/07/how-amd-plans-to-...
All these fabric linked processors, can interact independently of the system bus. Most data seems to get point to point in 2 hops, at about 40GBps bi-directional (~40 pcie3 lanes, which would need many hops), and can be combined to 160GBps - as i recall.
Suitably custom hot rodded for fabric rather than pcie3, the nvme quad arrays could reach 16MBps sequential imo on epycs/vegaS native nvme ports.
To the extent that gpuS are increasing their role in big servers, intel and nvidea simply have no answer to amd in the bulk of this market segment.
davide445 - Wednesday, July 12, 2017 - link
Finally real competition in the HPC market. Waiting for the next top500 AMD powered supercomputer.Shankar1962 - Wednesday, July 12, 2017 - link
Intel makes $60billion a year and its official that Skylake was shipping from Feb17 so i do not understand this excitement from AMD fan boys......if it is so good can we discuss the quarterly revenues between these companies? Why is AMD selling for very low prices when you claim superior performance over Intel? You can charge less but almost 40-50% cheap compared to Intel really?AMD exists because they are always inferior and can beat Intel only by selling for low prices and that too for what gaining 5-10% market which is just a matter of time before Intel releases more SKUs to grab it back
What about the software optimizations and extra BOM if someone switches to AMD?
What if AMD goes into hibernation like they did in last 5-6years?
Can you mention one innovation from AMD that changed the world?
Intel is a leader and all the technology we enjoy today happenned because of Intel technology.
Intel is a data center giant have head start have the resources money acquisitions like altera mobileeye movidus infineon nirvana etc and its just impossible that they will lose
Even if all the competent combines Intel will maintain atleast 80% share even 10years from now
Shankar1962 - Wednesday, July 12, 2017 - link
To add onNo one cares about these lab tests. Let's talk about the real world work loads.
Look at what Google AWS ATT etc has to say as they already switched to xeon sky lake
We should not really be debating if we have the clarity that we are talking about AMD getting just 5% -10% share by selling high end products they have for cheap prices....they fo not make too much money by doing that.....they have no other option as thats the only way they can dream of a 5-10% market share
For Analogy think Intel in semiconductor as Apple in selling smartphones
Intel has gross margins of ~63%
They have a solid product portfolio technologies and roadmap .....we can debate this forever but the revenues profits innovations and history between these companies can answer everything