Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Memory Subsystem: Latency
The performance of modern CPUs depends heavily on the cache subsystem. And some applications depend heavily on the DRAM subsystem too. We used LMBench in an effort to try to measure cache and memory latency. The numbers we looked at were "Random load latency stride=16 Bytes".
| Mem Hierarchy |
AMD EPYC 7601 DDR4-2400 |
Intel Skylake-SP DDR4-2666 |
Intel Broadwell Xeon E5-2699v4 DDR4-2400 |
| L1 Cache cycles | 4 | 4 | 4 |
| L2 Cache cycles | 12 | 14-22 | 12-15 |
| L3 Cache 4-8 MB - cycles | 34-47 | 54-56 | 38-51 |
| 16-32 MB - ns | 89-95 ns | 25-27 ns (+/- 55 cycles?) |
27-42 ns (+/- 47 cycles) |
| Memory 384-512 MB - ns | 96-98 ns | 89-91 ns | 95 ns |
Previously, Ian has described the AMD Infinity Fabric that stitches the two CCXes together in one die and interconnects the 4 different "Zeppelin" dies in one MCM. The choice of using two CCXes in a single die is certainly not optimal for Naples. The local "inside the CCX" 8 MB L3-cache is accessed with very little latency. But once the core needs to access another L3-cache chunk – even on the same die – unloaded latency is pretty bad: it's only slightly better than the DRAM access latency. Accessing DRAM is on all modern CPUs a naturally high latency operation: signals have to travel from the memory controller over the memory bus, and the internal memory matrix of DDR4-2666 DRAM is only running at 333 MHz (hence the very high CAS latencies of DDR4). So it is surprising that accessing SRAM over an on-chip fabric requires so many cycles.
What does this mean to the end user? The 64 MB L3 on the spec sheet does not really exist. In fact even the 16 MB L3 on a single Zeppelin die consists of two 8 MB L3-caches. There is no cache that truly functions as single, unified L3-cache on the MCM; instead there are eight separate 8 MB L3-caches.
That will work out fine for applications that have a footprint that fits within a single 8 MB L3 slice, like virtual machines (JVM, Hypervisors based ones) and HPC/Big Data applications that work on separate chunks of data in parallel (for example, the "map" phase of "map/reduce"). However this kind of setup will definitely hurt the performance of applications that need "central" access to one big data pool, such as database applications and big data applications in the "Shuffle phase".
Memory Subsystem: TinyMemBench
To double check our latency measurements and get a deeper understanding of the respective architectures, we also use the open source TinyMemBench benchmark. The source was compiled for x86 with GCC 5.4 and the optimization level was set to "-O3". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests.
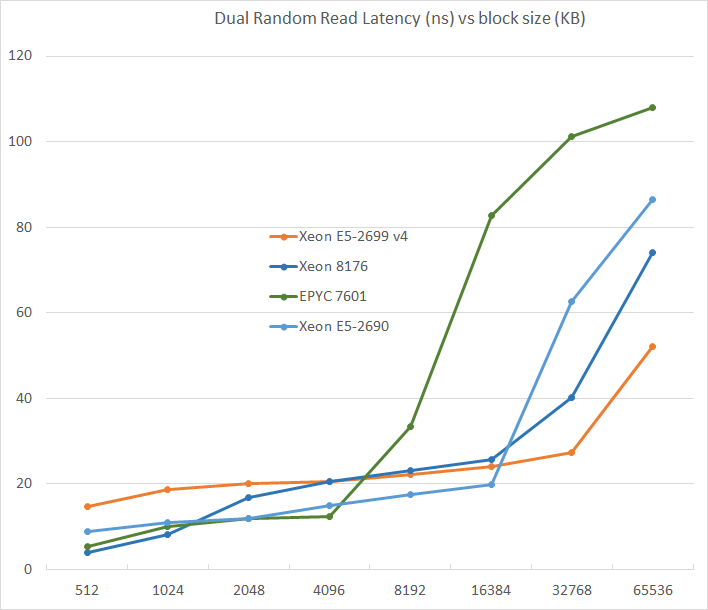
L3-cache sizes have increased steadily over the years. The Xeon E5 v1 had up to 20 MB, v3 came with 45 MB, and v4 "Broadwell EP" further increased this to 55 MB. But the fatter the cache, the higher the latency became. L3 latency doubled from Sandy Bridge-EP to Broadwell-EP. So it is no wonder that Skylake went for a larger L2-cache and a smaller but faster L3. The L2-cache offers 4 times lower latency at 512 KB.
AMD's unloaded latency is very competitive under 8 MB, and is a vast improvement over previous AMD server CPUs. Unfortunately, accessing more 8 MB incurs worse latency than a Broadwell core accessing DRAM. Due to the slow L3-cache access, AMD's DRAM access is also the slowest. The importance of unloaded DRAM latency should of course not be exaggerated: in most applications most of the loads are done in the caches. Still, it is bad news for applications with pointer chasing or other latency-sensitive operations.








219 Comments
View All Comments
tmbm50 - Wednesday, July 12, 2017 - link
Windows licensing is irrespective of virtualization.If you run a vm with a single vCPU on a server with 32 cores, you must license all 32 cores. KVM, ESXi...doesnt matter.
I'm sure most folks ignore that point in the license but if your an enterprise and get audited it's enforced.
nils_ - Wednesday, July 19, 2017 - link
Oracle does the same, and if your environment supports migration to other hosts you'd have to license those too (just in case). It's sort of criminal really.pepoluan - Friday, July 28, 2017 - link
I wonder, though, how does AWS managed to offer per-instance Windows licensing for EC2?Because, by that logic, EVERY Windows instance needs to be licensed against ALL cores in an Availability Zone...
Rοb - Sunday, July 23, 2017 - link
From very brief research it looks like for you're in for $6K per 16 Cores for the Datacenter Edition, trying to run the Software on a 4S 32 Core would cost 64x as much (excluding any Bulk Buy pricing you might be able to request).If you bought SM Fat Twins everything would be separated with less loss of density; for the money saved on Licensing would it pay off.
You want to conduct your business lawfully and can charge the customer what it costs plus profit - that's what it costs, want something different the price will probably be different.
Most Software that has per Core Licenses costs a fair bit and has thought it out so someone can't (lawfully) buy a single License and then run the Software on a much more powerful machine.
Take a deep breath and consider that if you ran it on a Phi x200 in x86 Mode that it would run slowly and you'd be charged for 256 Cores per CPU - so don't do that.
I don't want to sound unsympathetic but if the Vendor didn't make money then they wouldn't have incentive to write the Software.
Convince your customers to switch to free Software or for those prices write your own.
What is the complaint exactly, have a Rack Unit Fee, an Electricity Fee, a CPU Fee, a Software Fee, etc., and tell the customer that XYZ costs that much but if they get WYZ it will only cost so much instead.
Assuming everyone obeys the Law and pays the same for Electricity, Cooling, Electronics, Software and Labor then it's only the percentage of Profit where the difference in price lies - or in other words someone will always charge less (and not be 'audited' / as honest / as intelligent and hard working as your Team).
Let the people who you buy your Software from know your complaint and options, we can't be of much more help to you other than the years of service some of us devote to free and pay Software.
rocky12345 - Wednesday, July 12, 2017 - link
Great article as always I found it very well written and there was a lot of information to take in. It was good to see AMD chips doing this good. Bang for the buck seems to be in AMD's court in both the server market and consumer markets now.To those saying oh in the real world big companies would not be upgrading there software to the latest because of money that may be lost. You guys have a solid point there. BUT these tests are not being done in a real world company that depends on their servers to be up 100% of the time. These are just in house tests done to benchmark the new CPU's so yes the latest and greatest versions of the software can be & should be used. This shows exactly what the new CPU's can do when the software is updated to support the latest and greatest hardware. DO you actually think a huge company when buying new server clusters asks for software that is 5 -10 years olds I am fairly sure they do not. They want the most update to date software that is optimized for the new hardware they are spending big bucks on. They want it to be 100% stable and they also want the latest and greatest because of the fact that they probably will never update the software again or at least not for 5-7 years or more. So testing with old builds of software is very unrealistic and does not show the hardware at it's best and also not what a company is looking fro when buying new hardware.
With that said this is still a great write up and deserves a lot of praise.
rahvin - Wednesday, July 12, 2017 - link
I think it's a great comparison article too, you know it's pretty unbiased when both the Intel and AMD fanboi's are out in force criticizing the article for bias.My main comment is that Intel is crazy with those prices on the platinum chips. Those prices are easily two times the previous generation. This is the result of AMD being absent from the server market, that is Intel running processor prices up to the prices that Sun, IBM and HP used to charge in the worst of the enterprise server days. $13k for a Xeon, you've got to be shitting me.
Here's to hoping AMD mops the floor with them and causes prices to crater just like the last time Opteron was competitive. I remember the days when the highest end Xeon was less than $1000. These days the bottom end Xeons are pricing at $1000 and the high ends are 13X that much. Again, I pray AMD can get 25% market share and knock these prices back into reasonable territory. I also hope AMD makes a ton of money and can keep it up with competitive designs (even if it is doubtful because their management is garbage).
Rοb - Sunday, July 23, 2017 - link
Rahvin writes: "$13K for a Xeon ...".There's more to it than that, read the Fine Print; Intel has all kinds of expensive/inexpensive (depending upon your point of view).
See this Comparison: https://ark.intel.com/compare/120498,120499 .
Which is "less expensive":
Intel® Xeon® Platinum 8180M Processor (28 Cores) for $13,011.00
or
Intel® Xeon® Platinum 8156 Processor (4 Cores) for $7,007.00
So which is less 13 or 7 vs. 28 or 4?
You can't just look at one number.
There are other Technical Points, AMD doesn't have: AVX-512, OmniPath 400Gbps, 8-way Motherboards, etc.
If you MUST have what Intel offers then there's only one choice, if you can work around those things and get along with AMD then you're saving money.
If you wanted bleading edge performance then you'd be looking at Spark or Power; some complain that would deny the ability to play Crysis (and that due to their importance people stay up worrying about their issues).
Which is "best" is often easy to say given a narrow definition, which is best in every possible circumstance can be more of a challenge.
Disclaimer: I don't work at either place and intend to buy Epyc 7nm.
hahmed330 - Wednesday, July 12, 2017 - link
Jolly Good! AMD just smoked Intel's bacon!Impressive showing! Outstanding just outstanding!
Shankar1962 - Wednesday, July 12, 2017 - link
Yeah thats why AMD is still in losses and Intel is making net profits of ~$11billion plus each yearThey are gaining share by trying to sell their so called top products for cheap prices
Wondering who is getting smoked
PixyMisa - Thursday, July 13, 2017 - link
Epyc has been out for three weeks.