Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Memory Subsystem: Latency
The performance of modern CPUs depends heavily on the cache subsystem. And some applications depend heavily on the DRAM subsystem too. We used LMBench in an effort to try to measure cache and memory latency. The numbers we looked at were "Random load latency stride=16 Bytes".
| Mem Hierarchy |
AMD EPYC 7601 DDR4-2400 |
Intel Skylake-SP DDR4-2666 |
Intel Broadwell Xeon E5-2699v4 DDR4-2400 |
| L1 Cache cycles | 4 | 4 | 4 |
| L2 Cache cycles | 12 | 14-22 | 12-15 |
| L3 Cache 4-8 MB - cycles | 34-47 | 54-56 | 38-51 |
| 16-32 MB - ns | 89-95 ns | 25-27 ns (+/- 55 cycles?) |
27-42 ns (+/- 47 cycles) |
| Memory 384-512 MB - ns | 96-98 ns | 89-91 ns | 95 ns |
Previously, Ian has described the AMD Infinity Fabric that stitches the two CCXes together in one die and interconnects the 4 different "Zeppelin" dies in one MCM. The choice of using two CCXes in a single die is certainly not optimal for Naples. The local "inside the CCX" 8 MB L3-cache is accessed with very little latency. But once the core needs to access another L3-cache chunk – even on the same die – unloaded latency is pretty bad: it's only slightly better than the DRAM access latency. Accessing DRAM is on all modern CPUs a naturally high latency operation: signals have to travel from the memory controller over the memory bus, and the internal memory matrix of DDR4-2666 DRAM is only running at 333 MHz (hence the very high CAS latencies of DDR4). So it is surprising that accessing SRAM over an on-chip fabric requires so many cycles.
What does this mean to the end user? The 64 MB L3 on the spec sheet does not really exist. In fact even the 16 MB L3 on a single Zeppelin die consists of two 8 MB L3-caches. There is no cache that truly functions as single, unified L3-cache on the MCM; instead there are eight separate 8 MB L3-caches.
That will work out fine for applications that have a footprint that fits within a single 8 MB L3 slice, like virtual machines (JVM, Hypervisors based ones) and HPC/Big Data applications that work on separate chunks of data in parallel (for example, the "map" phase of "map/reduce"). However this kind of setup will definitely hurt the performance of applications that need "central" access to one big data pool, such as database applications and big data applications in the "Shuffle phase".
Memory Subsystem: TinyMemBench
To double check our latency measurements and get a deeper understanding of the respective architectures, we also use the open source TinyMemBench benchmark. The source was compiled for x86 with GCC 5.4 and the optimization level was set to "-O3". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests.
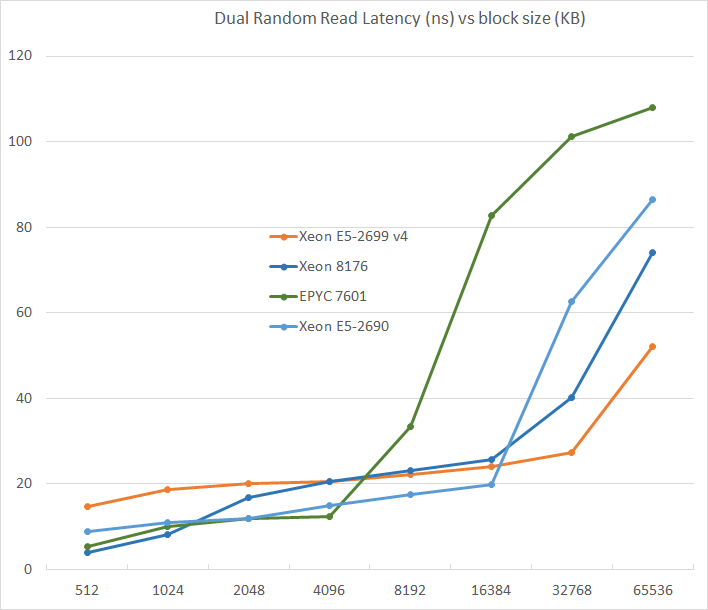
L3-cache sizes have increased steadily over the years. The Xeon E5 v1 had up to 20 MB, v3 came with 45 MB, and v4 "Broadwell EP" further increased this to 55 MB. But the fatter the cache, the higher the latency became. L3 latency doubled from Sandy Bridge-EP to Broadwell-EP. So it is no wonder that Skylake went for a larger L2-cache and a smaller but faster L3. The L2-cache offers 4 times lower latency at 512 KB.
AMD's unloaded latency is very competitive under 8 MB, and is a vast improvement over previous AMD server CPUs. Unfortunately, accessing more 8 MB incurs worse latency than a Broadwell core accessing DRAM. Due to the slow L3-cache access, AMD's DRAM access is also the slowest. The importance of unloaded DRAM latency should of course not be exaggerated: in most applications most of the loads are done in the caches. Still, it is bad news for applications with pointer chasing or other latency-sensitive operations.








219 Comments
View All Comments
msroadkill612 - Wednesday, July 12, 2017 - link
It looks interesting. Do u have a point?Are you saying they have a place in this epyc debate? using cheaper ddr3 ram on epyc?
yuhong - Friday, July 14, 2017 - link
"We were told from Intel that ‘only 0.5% of the market actually uses those quad ranked and LR DRAMs’, "intelemployee2012 - Wednesday, July 12, 2017 - link
what kind of a forum and website is this? we can't delete the account, cannot edit a comment for fixing typos, cannot edit username, cannot contact an admin if we need to report something. Will never use these websites from now on.Ryan Smith - Wednesday, July 12, 2017 - link
"what kind of a forum and website is this?"The basic kind. It's not meant to be a replacement for forums, but rather a way to comment on the article. Deleting/editing comments is specifically not supported to prevent people from pulling Reddit-style shenanigans. The idea is that you post once, and you post something meaningful.
As for any other issues you may have, you are welcome to contact me directly.
Ranger1065 - Thursday, July 13, 2017 - link
That's a relief :)iwod - Wednesday, July 12, 2017 - link
I cant believe what i just read. While I knew Zen was good for Desktop, i expected the battle to be in Intel's flavour on the Server since Intel has years to tune and work on those workload. But instead, we have a much CHEAPER AMD CPU that perform Better / Same or Slightly worst in several cases, using much LOWER Energy during workload, while using a not as advance 14nm node compared to Intel!And NO words on stability problems from running these test on AMD. This is like Athlon 64 all over again!
pSupaNova - Wednesday, July 12, 2017 - link
Yes it is.But this time much worse for Intel with their manufacturing lead shrinking along with their workforce.
Shankar1962 - Wednesday, July 12, 2017 - link
Competition has spoiled the naming convention Intels 14 === competetions 7 or 10Intel publicly challenged everyone to revisit the metrics and no one responded
Can we discuss the yield density and scaling metrics? Intel used to maintain 2year lead now grew that to 3-4year lead
Because its vertically integrated company it looks like Intel vs rest of the world and yet their revenue profits grow year over year
iwod - Thursday, July 13, 2017 - link
Grew to 3 - 4 years? Intel is shipping 10nm early next year in some laptop segment, TSMC is shipping 7nm Apple SoC in 200M yearly unit quantity starting next September.If anything the gap from 2 - 3 years is now shrink to 1 to 1.5 year.
Shankar1962 - Thursday, July 13, 2017 - link
Yeah 1-1.5 years if we cheat the metrics when comparison2-3years if we look at metrics accurately
A process node shrink is compared by metrics like yield cost scaling density etc
7nm 10nm etc is just a name