Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Memory Subsystem: Bandwidth
Measuring the full bandwidth potential with John McCalpin's Stream bandwidth benchmark is getting increasingly difficult on the latest CPUs, as core and memory channel counts have continued to grow. We compiled the stream 5.10 source code with the Intel compiler (icc) for linux version 17, or GCC 5.4, both 64-bit. The following compiler switches were used on icc:
icc -fast -qopenmp -parallel (-AVX) -DSTREAM_ARRAY_SIZE=800000000
Notice that we had to increase the array significantly, to a data size of around 6 GB. We compiled one version with AVX and one without.
The results are expressed in gigabytes per second.
Meanwhile the following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=800000000
Notice that the DDR4 DRAM in the EPYC system ran at 2400 GT/s (8 channels), while the Intel system ran its DRAM at 2666 GT/s (6 channels). So the dual socket AMD system should theoretically get 307 GB per second (2.4 GT/s* 8 bytes per channel x 8 channels x 2 sockets). The Intel system has access to 256 GB per second (2.66 GT/s* 8 bytes per channel x 6 channels x 2 sockets).
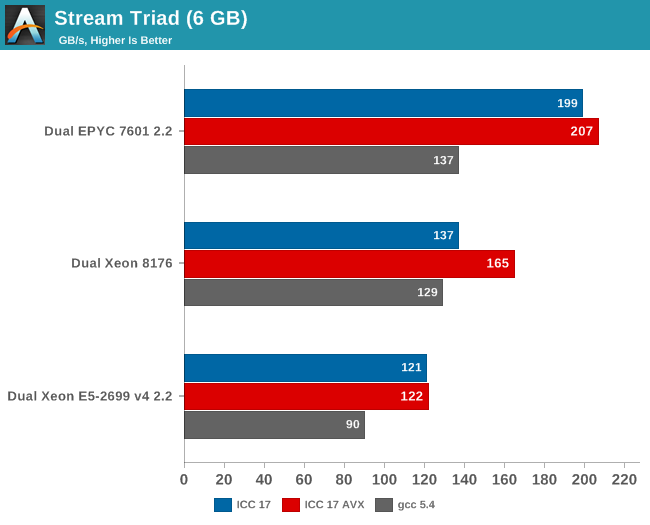
AMD told me they do not fully trust the results from the binaries compiled with ICC (and who can blame them?). Their own fully customized stream binary achieved 250 GB/s. Intel claims 199 GB/s for an AVX-512 optimized binary (Xeon E5-2699 v4: 128 GB/s with DDR-2400). Those kind of bandwidth numbers are only available to specially tuned AVX HPC binaries.
Our numbers are much more realistic, and show that given enough threads, the 8 channels of DDR4 give the AMD EPYC server a 25% to 45% bandwidth advantage. This is less relevant in most server applications, but a nice bonus in many sparse matrix HPC applications.
Maximum bandwidth is one thing, but that bandwidth must be available as soon as possible. To better understand the memory subsystem, we pinned the stream threads to different cores with numactl.
| Pinned Memory Bandwidth (in MB/sec) | |||
| Mem Hierarchy |
AMD "Naples" EPYC 7601 DDR4-2400 |
Intel "Skylake-SP" Xeon 8176 DDR4-2666 |
Intel "Broadwell-EP" Xeon E5-2699v4 DDR4-2400 |
| 1 Thread | 27490 | 12224 | 18555 |
| 2 Threads, same core same socket |
27663 | 14313 | 19043 |
| 2 Threads, different cores same socket |
29836 | 24462 | 37279 |
| 2 Threads, different socket | 54997 | 24387 | 37333 |
| 4 threads on the first 4 cores same socket |
29201 | 47986 | 53983 |
| 8 threads on the first 8 cores same socket |
32703 | 77884 | 61450 |
| 8 threads on different dies (core 0,4,8,12...) same socket |
98747 | 77880 | 61504 |
The new Skylake-SP offers mediocre bandwidth to a single thread: only 12 GB/s is available despite the use of fast DDR-4 2666. The Broadwell-EP delivers 50% more bandwidth with slower DDR4-2400. It is clear that Skylake-SP needs more threads to get the most of its available memory bandwidth.
Meanwhile a single thread on a Naples core can get 27,5 GB/s if necessary. This is very promissing, as this means that a single-threaded phase in an HPC application will get abundant bandwidth and run as fast as possible. But the total bandwidth that one whole quad core CCX can command is only 30 GB/s.
Overall, memory bandwidth on Intel's Skylake-SP Xeon behaves more linearly than on AMD's EPYC. All off the Xeon's cores have access to all the memory channels, so bandwidth more directly increases with the number of threads.








219 Comments
View All Comments
PixyMisa - Tuesday, July 11, 2017 - link
No, the pricing is correct. The 1P CPUs really are half the price of a single 2P CPU.msroadkill612 - Wednesday, July 12, 2017 - link
Seems to me, the simplest explanation of something complex, is to list what it will not do, which they will not do :(.Can i run a 1p Epyc in a 2p mobo e.g., please?
PixyMisa - Thursday, July 13, 2017 - link
Short answer is no. It might boot, but only half the slots, memory, SATA and so on will be available. Two 1P CPUs won't talk to each other.A 2P Epyc will work in a 1P board though.
cekim - Tuesday, July 11, 2017 - link
One glaring bug/feature of AMD's segmentation relative to Intel's is the utter and obvious crippling of clock speeds for all but the absolute top SKUs. Fewer cores should be able to make use of higher clocks within the same TDP envelope. As a result Intel is objectively offering more and better fits up and down the sweep of cores vs clocks vs price spectrum.So, the bottom line is AMD is saying that you will have to buy the top-end, 4S SKU to get the top GHz for those applications in your mix that won't benefit from 16,18,32,128 cores.
I say all of this as someone who desperately wants EPYC to shake things up and force Intel to remove the sand-bags. I know I'm in a small, but non-zero market of users who can make use of dozens of cores, but still need 8 or fewer cores to perform on par with desktop parts for that purpose.
KAlmquist - Wednesday, July 12, 2017 - link
One possibility is that they have only a small percentage of the chips currently being produced bin well enough to be used in the highest clocking SKU's, so they are saving those chips for the most expensive offerings. Admittedly, that depends on what they are seeing coming off the production line. If they have a fair number of chips where with two very good cores, and two not so good, then it would make sense to offer a high clocking 16 core EPYC using chips with two cores disabled. But if clock speed on most chips is limited due to minor registration errors (which would affect the entire chip), then a chip with only two really good cores would require two localized defects in two separate cores, in addition to very good registration to get the two good cores. The combination might be too rare to justify a separate SKU.I would expect Global Foundries to continue to tweak its process to get better yields. In that case, more processors would end up in the highest bin, and AMD might decide to launch a higher clock speed 16 and 8 core EPYC processors, mostly using chips which bin well enough that they could have been used for the 32 core EPYC 7601.
alpha754293 - Tuesday, July 11, 2017 - link
Why does the Intel Xeon 6142 cost LESS than the 6142M? (e.g. per the table above, 6142 is shown with a price of $5946 while the 6142M costs $2949)ca197 - Tuesday, July 11, 2017 - link
I assume that is the wrong way round on the list. I have seen it reported the other way round on other sites.Ian Cutress - Tuesday, July 11, 2017 - link
You're correct. I've updated the piece, was a misread error from Intel's tables.coder543 - Tuesday, July 11, 2017 - link
On page 6, it says that Epyc only has 64 PCIe lanes (available), but that's not correct. There are 128 PCIe lanes per chip. In a 1P configuration, that's 128 PCIe lanes available. On a 2P configuration, 64 PCIe lanes from each chip are used to connect to the other chip, leaving 64 + 64 = 128 PCIe lanes still available.This is a significant advantage.
Ian Cutress - Tuesday, July 11, 2017 - link
You misread that table. It's quoting per-CPU when in a 2P configuration.