Intel Announces Skylake-X: Bringing 18-Core HCC Silicon to Consumers for $1999
by Ian Cutress on May 30, 2017 3:03 AM ESTAnnouncement Three: Skylake-X's New L3 Cache Architecture
(AKA I Like Big Cache and I Cannot Lie)
SKU madness aside, there's more to this launch than just the number of cores at what price. Deviating somewhat from their usual pattern, Intel has made some interesting changes to several elements of Skylake-X that are worth discussing. Next is how Intel is implementing the per-core cache.
In previous generations of HEDT processors (as well as the Xeon processors), Intel implemented an three stage cache before hitting main memory. The L1 and L2 caches were private to each core and inclusive, while the L3 cache was a last-level cache covering all cores and that also being inclusive. This, at a high level, means that any data in L2 is duplicated in L3, such that if a cache line is evicted into L2 it will still be present in the L3 if it is needed, rather than requiring a trip all the way out to DRAM. The sizes of the memory are important as well: with an inclusive L2 to L3 the L3 cache is usually several multiplies of the L2 in order to store all the L2 data plus some more for an L3. Intel typically had 256 kilobytes of L2 cache per core, and anywhere between 1.5MB to 3.75MB of L3 per core, which gave both caches plenty of room and performance. It is worth noting at this point that L2 cache is closer to the logic of the core, and space is at a premium.
With Skylake-X, this cache arrangement changes. When Skylake-S was originally launched, we noted that the L2 cache had a lower associativity as it allowed for more modularity, and this is that principle in action. Skylake-X processors will have their private L2 cache increased from 256 KB to 1 MB, a four-fold increase. This comes at the expense of the L3 cache, which is reduced from ~2.5MB/core to 1.375MB/core.
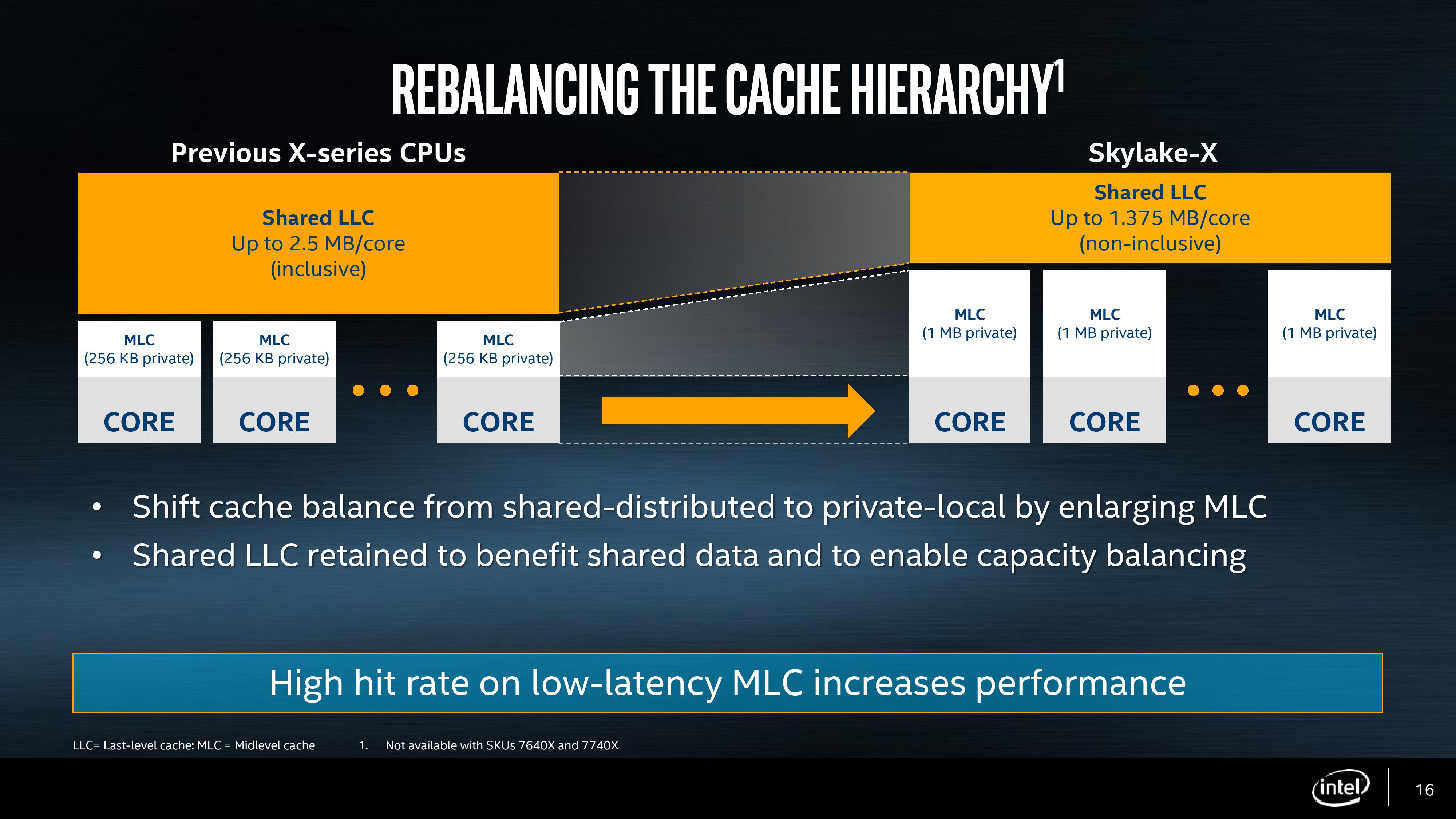
With such a large L2 cache, the L2 to L3 connection is no longer inclusive and now ‘non-inclusive’. Intel is using this terminology rather than ‘exclusive’ or ‘fully-exclusive’, as the L3 will still have some of the L3 features that aren’t present in a victim cache, such as prefetching. What this will mean however is more work for snooping, and keeping track of where cache lines are. Cores will snoop other cores’ L2 to find updated data with the DRAM as a backup (which may be out of date). In previous generations the L3 cache was always a backup, but now this changes.
The good element of this design is that a larger L2 will increase the hit-rate and decrease the miss-rate. Depending on the level of associativity (which has not been disclosed yet, at least not in the basic slide decks), a general rule I have heard is that a double of cache size decreases the miss rate by the sqrt(2), and is liable for a 3-5% IPC uplift in a regular workflow. Thus here’s a conundrum for you: if the L2 has a factor 2 better hit rate, leading to an 8-13% IPC increase, it’s not the same performance as Skylake-S. It may be the same microarchitecture outside the caches, but we get a situation where performance will differ.
Fundamental Realisation: Skylake-S IPC and Skylake-X IPC will be different.
This is something that fundamentally requires in-depth testing. Combine this with the change in the L3 cache, and it is hard to predict the outcome without being a silicon design expert. I am not one of those, but it's something I want to look into as we approach the actual Skylake-X launch.
More things to note on the cache structure. There are many ‘ways’ to do it, one of which I imagined initially is a partitioned cache strategy. The cache layout could be the same as previous generations, but partitions of the L3 were designated L2. This makes life difficult, because then you have a partition of the L2 at the same latency of the L3, and that brings a lot of headaches if the L2 latency has a wide variation. This method would be easy for silicon layout, but hard to implement. Looking at the HCC silicon representation in our slide-deck, it’s clear that there is no fundamental L3 covering all the cores – each core has its partition. That being the case, we now have an L2 at approximately the same size as the L3, at least per core. Given these two points, I fully suspect that Intel is running a physical L2 at 1MB, which will give the design the high hit-rate and consistent low-latency it needs. This will be one feather in the cap for Intel.








203 Comments
View All Comments
ddriver - Tuesday, May 30, 2017 - link
You fail miserably at making a point. I am comparing the latest and greatest both companies had on the market at the time. Now back under the bridge with you!Ranger1065 - Wednesday, May 31, 2017 - link
ddriver, I always respect your perspective at Anandtech particularly when it differs from general opinion as, thankfully, it often does. I also admire the tenacity with which you stick to your guns. The comments section would certainly be an infinitely more boring and narrow minded place without you. Keep up your excellent posts.fanofanand - Wednesday, May 31, 2017 - link
+1He is the most entertaining person here, I love reading his take on things.
Ro_Ja - Thursday, June 1, 2017 - link
Your comment is the reason why I scroll down this section.Hxx - Tuesday, May 30, 2017 - link
I dont think you understand the meaning of the word desperate at least in this context. Maybe intel redesigned their release schedule in response to ryzen who the f knows except their upper mngmt and thats irrelevant, in the end what matters is what the consumer gets and for what PRICE. If intel was truly desperate that we would have at least seen a price cut in their current cpu lineup and Im not seein that. These CPUs are also targeted at the enthusiast crowd and nowhere near Ryzen's price point so wheres the desperation again?rarson - Wednesday, May 31, 2017 - link
The marketing alone, never mind the fact that Intel's cannibalizing their own sales selling HCC chips to consumers, reeks of desperation.DC Architect - Tuesday, May 30, 2017 - link
If you think CIO's give a damn about "brand loyalty" over profit margins then you are high. Also... 99.8% of the people using computers couldn't tell you what a motherboard IS or what components are in their "hard drive box" let alone have any loyalty to those brands. The guys making the call on these kinds of decisions could give a rats ass what the guy on the floor wants when he can increase the margins by 100% and only lose 1% in IPC.We're not talking about server CPU's here that are parsing huge databases 24/7. That 1-5% IPC loss for your Joe Shmoe user matters a lot less when you can tell the CEO that you only need half your normal operating budget this year for workstations.
Icehawk - Tuesday, May 30, 2017 - link
Brand loyalty is HUGE in the corporate/server marketplace, it's foolish to think otherwise. Most large companies lock in with one or two vendors and buy whatever they offer that closest fits their needs or are able to get custom orders if the volume is enough. Never in my 19 years in IT have I seen or used a single AMD server, and only in a very few (crappy) laptops. Even back in the Athlon days we would stick with Intel as they are a known quantity and well supported.Hell where I work now they buy i7s for their grunts when an i3 would be fine - but it is easier on accounting to just deal with one SKU and easier for IT as well to only deal with a single configuration. The hardware cost differential can be offset by factors such as these.
On non server side, I am really happy to see AMD doing better - I probably will go with the 7820 though as I do value single threaded a lot (gaming) and also do a ton of reencoding to x265 where more cores would really help.
theuglyman0war - Thursday, June 8, 2017 - link
to be fair... I assume all those TBD's certainly do represent an "upcoming" response to ryzen that we would not had seen to whatever degree the final form takes. And that is awesome.The healthy competitive market is officially TBD! :)
Anyone with any reason is waiting for the dust to settle and the market to correct itself with a consumer response the way healthy markets should function.
alpha754293 - Friday, June 2, 2017 - link
It's "funny" reading your comment only because so much of it is so wrong/unfounded on so many levels.I used to be a strictly AMD-only shop because they offered a much better economic efficiency (FLOP/$).
Now, pretty much all of my new systems are all Intel because Intel is now better in terms of FLOP/$. (And also in just pure, brute-force performance).
AMD really screwed the pooch when they went with the shared FPU between two ALU design in their MCMs rather than having a dedicated FPU PER ALU (something which the UltraSPARC Niagara T1 originally did, and then revised it with T2).
It was choking/strangling itself. WHYYY Derrick Meyer (being a former EE himself) would allow that is beyond me.
I pick it pretty much solely based on FLOP/$ (as long as the $ piece of it isn't SO high that I can't afford to pay for it/buy it).
There ARE some times when you might want or even NEED a super high powered, many, many many core count system because if you can do a lot of development work deskside, you refine your model piece by piece without having to spend a great deal of time re-running the whole thing always, everytime; and once your model is set up, THEN you ship it/send it off to the cluster and let the cluster go at it.
If you are doing your debugging work on the cluster, you're just taking valuable time from the cluster away. (Like when I am doing some of my simulation stuff, the volume of data that gets generated is in the TBs now, so having to send the data back and forth when you have "bad" data (say from a run that errored out) - you're literally just shovelling crap around, which takes time and doesn't do anything useful or productive.
re: your 70 active systems
On the assumption that they're ALL 3770K chips, that's about 280 cores. You can probably get yourself a bunch of these:
http://www.ebay.com/itm/2U-Supermicro-6027TR-HTRF-...
to replace your compute farm.
I would be willing to bet that between 2-4 of those can replace your entire farm and still give you better FLOP/$.