Exploring DynamIQ and ARM’s New CPUs: Cortex-A75, Cortex-A55
by Matt Humrick on May 29, 2017 12:00 AM EST- Posted in
- Smartphones
- CPUs
- Arm
- Mobile
- Cortex
- DynamIQ
- Cortex A75
- Cortex A55

ARM moves at an aggressive pace, pushing out new processor IP on a yearly cadence. It needs to move fast partly because it has so many partners across so many industries to keep happy and partly because it needs to keep up with the technology its IP comes into contact with, everything from new process nodes to higher quality displays to artificial intelligence. To keep pace, ARM keeps multiple design teams in several different locations all working in parallel.
At its annual TechDay event last year, held at one such facility in Austin, Texas, ARM introduced the Mali-G71 GPU—the first to use its new Bifrost GPU architecture—and the Cortex-A73 CPU—a new big core to replace the A72 in mobile. Notably absent, however, was a new little core.
Another year, another TechDay, and another ARM facility (this time in Cambridge, UK)—can only mean new ARM IP. Over the span of several days, we got an in-depth look at its latest technologies, including DynamIQ, the Mali-G72 GPU, the Cortex-A75, and (yes, finally) the successor to the A53: Cortex-A55.
The A53 was announced alongside the A57 and has been in use for several years, both on its own or as the little core in a big.LITTLE configuration. It’s been hugely successful, with more than 40 licensees and 1.7 billion units shipped in just 3 years. But during this time ARM introduced new big cores on a yearly cadence, moving from A57 to A72 to A73. The A53 remained unchanged, however, even as the performance gap between the big and little cores continued to grow.
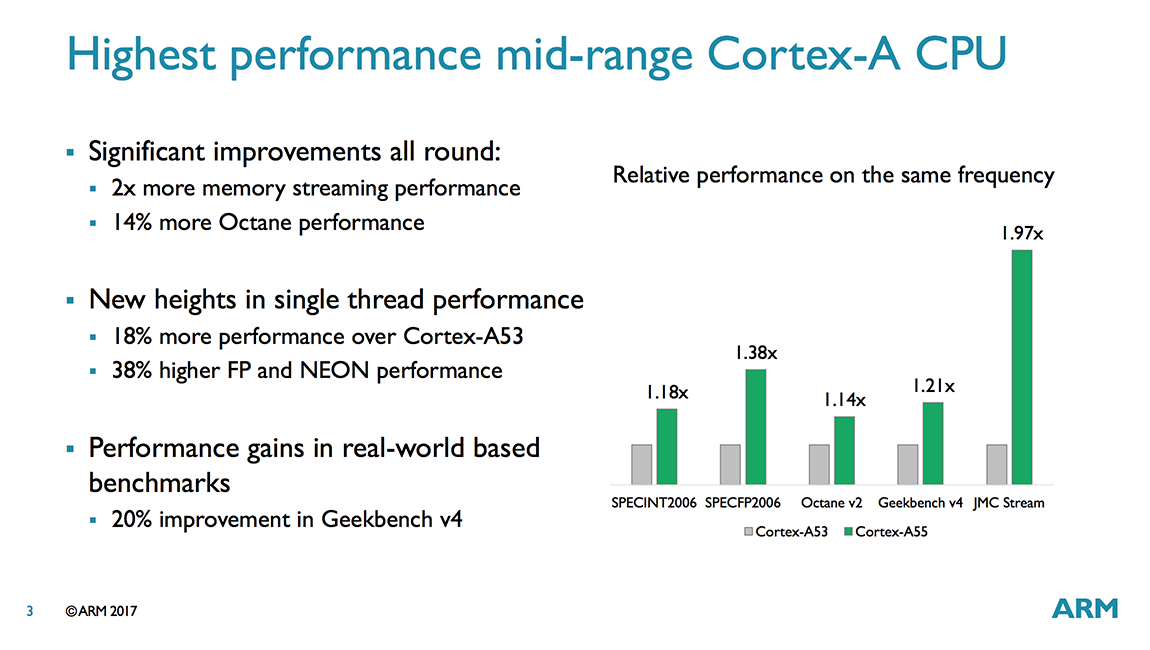
Predictably then, the focus for A55 was on improving performance. The A53’s dual-issue, in-order core, which serves as the starting point for A55, already delivers good throughput, so ARM focused on improving the memory system. A new data prefetcher, an integrated L2 cache that reduces latency by 50%, and an extra level of L3 cache (among other changes) give the A55 significantly better memory performance—quantified by a nearly 2x improvement in the LMBench memory copy test. The numbers provided by ARM also show an 18% performance gain in SPECint 2006 and an even bigger 38% gain in SPECfp 2006 relative to the A53. These numbers, as well as the others shown in the chart, comparing the A55 and A53 are at the same frequency, same L1/L2 cache sizes, same compiler, etc. and are meant to be a fair comparison. The actual gains should actually be a little higher, because partner SoCs will benefit from adding the L3 cache, which these numbers do not include.
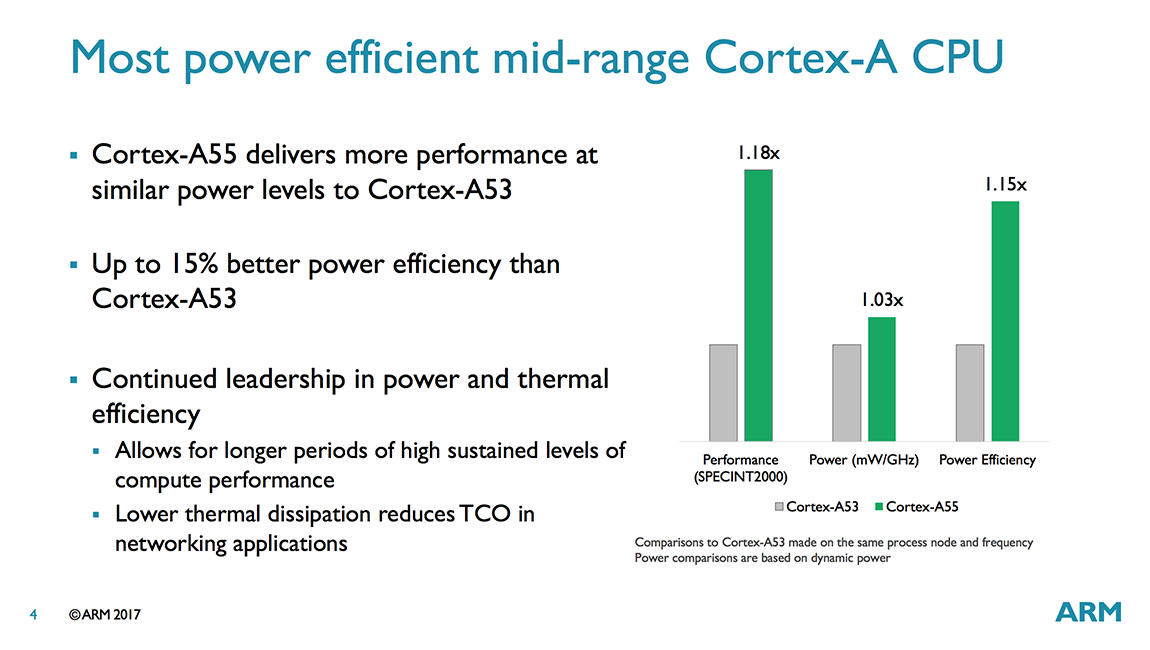
The additional performance does not come for free, however. Power consumption is up 3% relative to the A53 (iso-process, iso-frequency), but power efficiency still improves by 15% when running SPECint 2000 because of its higher performance.
The A55 includes several new features too that will help it expand into new markets. Virtual Host Extensions (VHE) are very important for the automotive market and the advanced safety and reliability features, including architectural RAS support and ECC/parity for all levels of cache are critical for many applications, including automotive and industrial. There’s new features for infrastructure applications too, including a new Int8 dot product instruction (useful for accelerating neural networks). Because A55 is compatible with DynamIQ, it also gets cache stashing and access to a 256-bit AMBA 5 CHI port.

When ARM announced the A73 last year, it talked a lot about improving sustained performance and working within a tight thermal envelope. In other words, the A73 was all about improving power efficiency. The A75 goes in a different direction: Taking advantage of the A73’s thermal headroom, ARM focused on improving performance while maintaining the same efficiency as the A73.
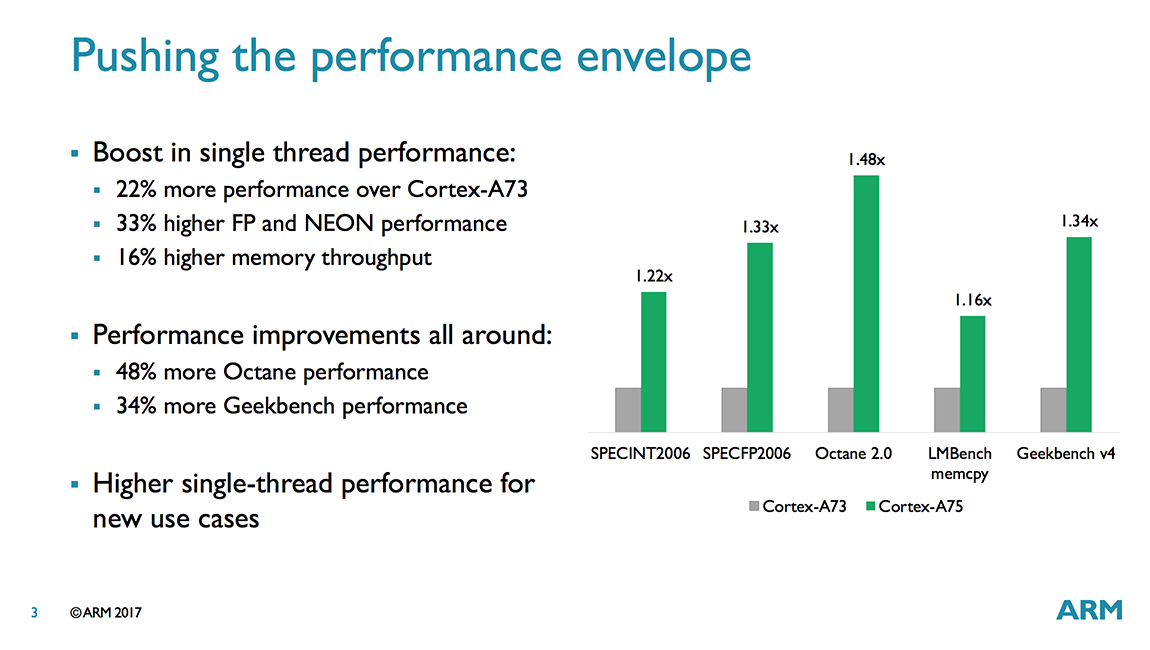
Our previous performance testing revealed mixed results when comparing the A73 to the A72—not too surprising given the significant differences in microarchitecture—with the A73 generally outpacing the A72 by a small margin for integer tasks but falling behind the older CPU in floating point workloads. Things look better for the A75, at least based on ARM’s numbers, which show noticeable gains over the A73 in both integer and floating-point workloads as well as memory streaming.
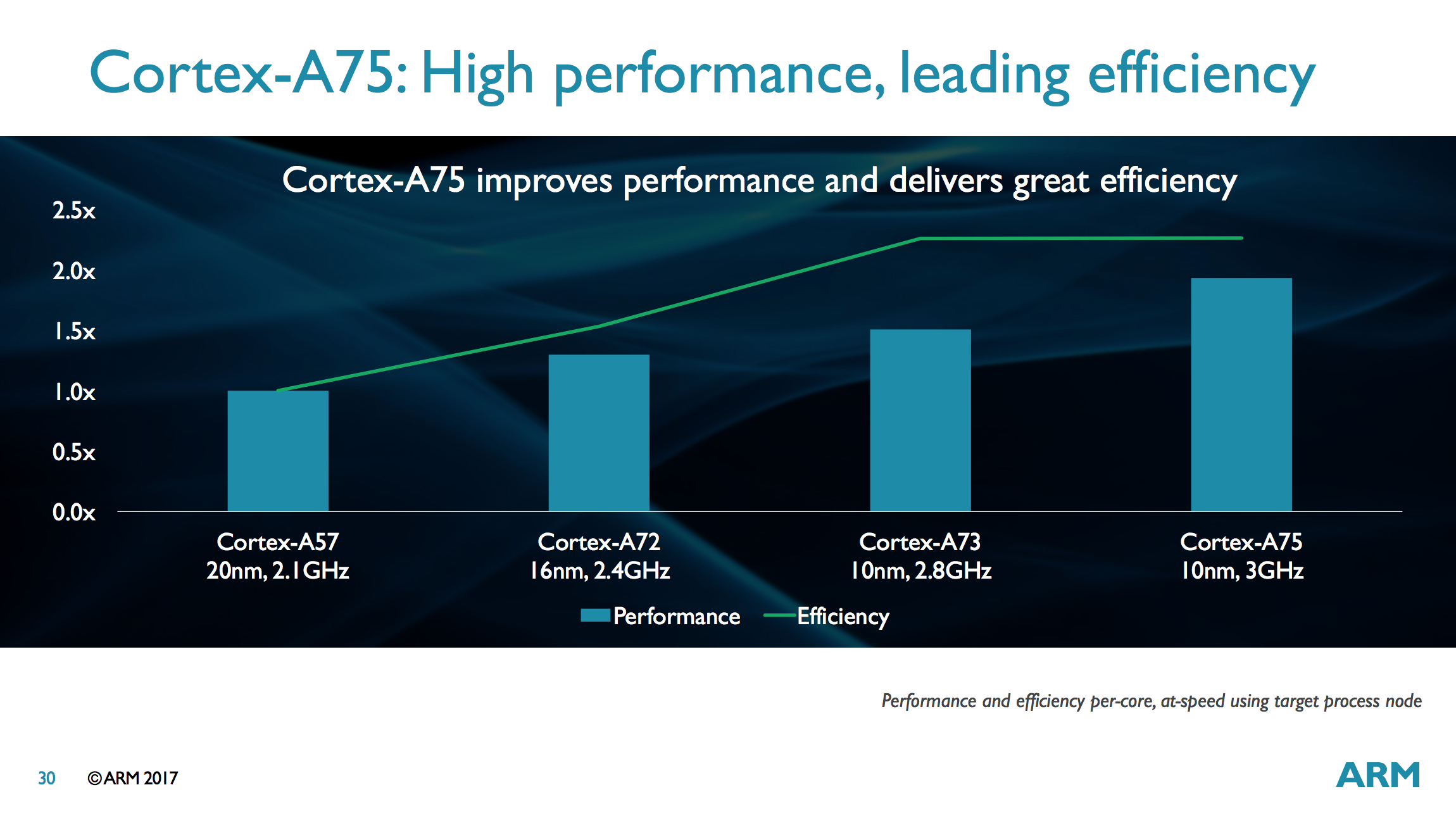
The graph above shows that the A75 operating at 3GHz on a 10nm node achieves better performance and the same efficiency as an A73 operating at 2.8GHz on a 10nm node, which means the A75 consumes more power. How much more is difficult to tell based on this one simple graph. We know that the A73 is thermally limited when using 4 cores (albeit less so than the A72), so the A75 definitely will be as well. This is not a common scenario, however. Most mobile workloads only fire up 1-2 cores at a time and usually only in short bursts. ARM obviously felt comfortable enough using the A73’s extra thermal headroom to boost performance without negatively impacting sustained performance.
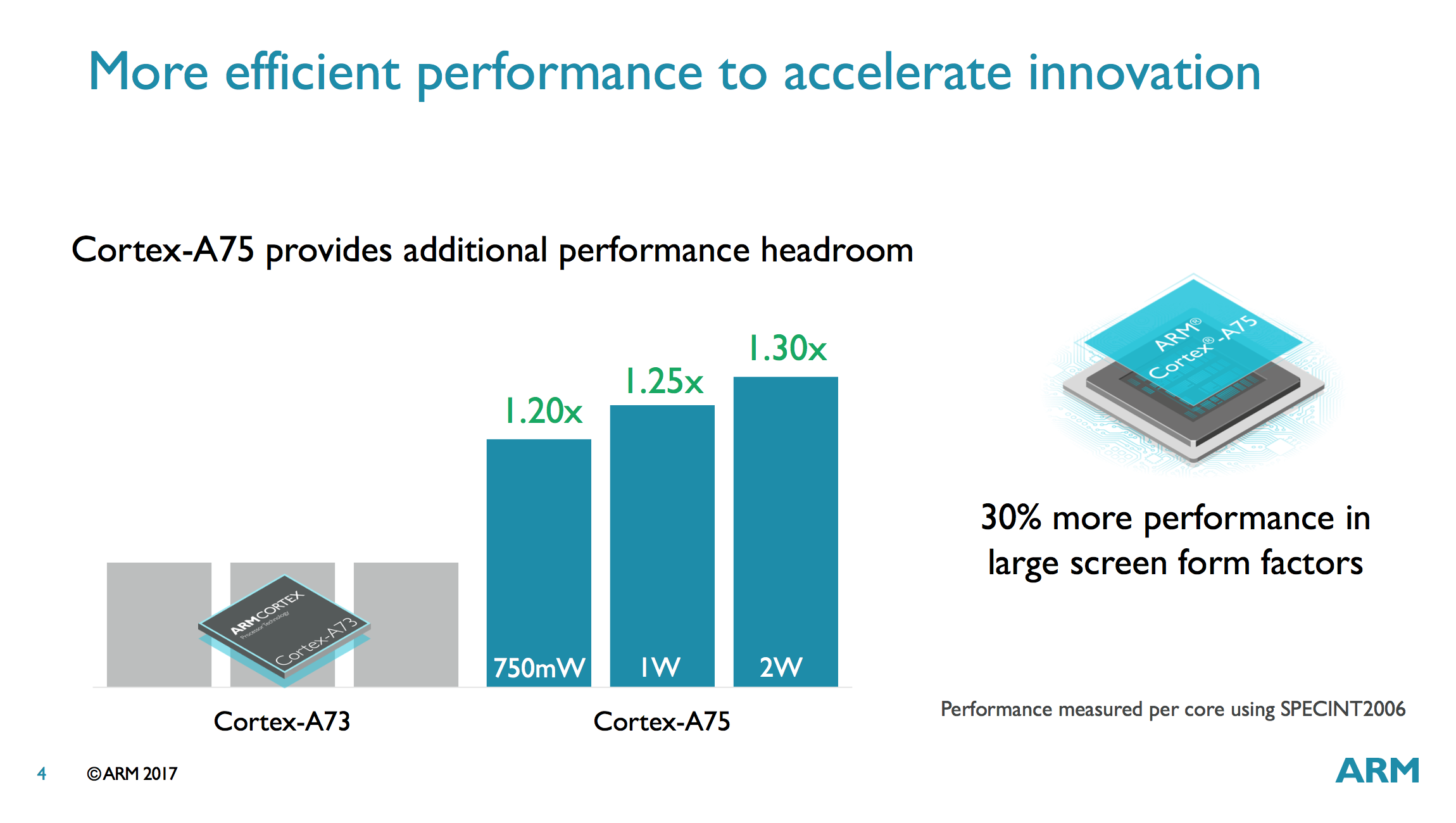
ARM wants to push the A75 into larger form-factor devices with power budgets beyond mobile’s 750mW/core too by pushing frequency higher. Something like a Chromebook or a 2-in-1 ultraportable come to mind. At 1W/core the A75 delivers 25% higher performance than the A73 and at 2W/core the A75’s advantage bumps up to 30% when running SPECint 2006. If anything, these numbers highlight why it’s not a good idea to push performance with frequency alone, as dynamic power scales exponentially.
ARM targeted the A73 specifically at mobile by focusing on power efficiency and removing some features useful for other applications to simplify the design, including no ECC on the L1 cache and no option for a 256-bit AMBA 5 CHI port. With A75, there’s now a clear upgrade path from A72. For the server and infrastructure markets, A75 supports ECC/parity for all levels of cache and AMBA 5 CHI for connecting to larger CCI, CCN, or CMN fabrics, and for automotive and other safety critical applications there’s architectural RAS support, protection against data poisoning, and improved error management.
On the next few pages, we’ll dive deeper into the technical details and features of ARM’s new IP, including DynamIQ (the next iteration of big.LITTLE), Cortex-A75, and Cortex-A55.








104 Comments
View All Comments
Samus - Monday, May 29, 2017 - link
Ok, point taken, 4 year gap. Even more unacceptable. But you continue to imply the architecture hitting a wall because of the inherently in order nature of RISC so I ask you, why have Samsung and Apple continued to have great success deviating from ARM's reference designs, while Qualcomm has been married to them and paying the performance price (specifically looking at you, 808)Death666Angel - Monday, May 29, 2017 - link
"die-constrained design" He gave the answer right there, at least as far as Apple is concerned. ARM is imposing a certain, small, die size for the A53/55 cores, that limits their potential performance a lot. Apple doesn't care about die size since their margins are high enough. The Apple A5X was as large as the Intel Ivy Bridge 4C die. Both were around in 2012, though Intel had the process node advantage. Still insane numbers. And Samsung is also very vertically integrated, they don't have to worry as much about die size as Qualcomm since they own the manufacturing as well. And QC doesn't have to play the performance game, since their choke hold on the modem technology allows them to still have plenty of design wins for the moment.Wilco1 - Monday, May 29, 2017 - link
It's a 3 year gap. And Samsung still uses Cortex-A53 alongside Mongoose.tipoo - Monday, May 29, 2017 - link
Not RISC constrained to in-order, nothing to do with RISC, rather that in-order is a design choice for this particular model for power and die size.A75, Hurricane, etc are of course massively out of order ARM/RISC designs.
name99 - Wednesday, May 31, 2017 - link
Zephyr is NOT a massive OoO design. Probably 2-wide in order. We don't know its performance, but it certainly saves power (compared toA9) while not seeming to slow down the phone.ARM seems to hurt itself by an insistence on these TINY designs. (Just like Intel on the other side hurts itself by an insistence on designs that are first server targeted). Apple wins partially by not trying to be everything to everyone...
helvete - Wednesday, August 30, 2017 - link
Ending up being nothing for nobody? /saryonoco - Monday, May 29, 2017 - link
There is nothing inherently in-order about RISC. Various ARM designs such as Cortex A57, A72, A73 and A75 are out of order.Samsung has not really deviated from ARM's reference design by much, they still use the Cortex A53 in various SoCs including their latest and greatest Exynos 8895. And that 8895 is also falling behind Snapdragon 835, which is a standard A73 implementation for all intents and purposes (Qualcomm's marketing notwithstanding).
Apple, well, they can afford to dedicate the die area to a big core. No one else can.
ZeDestructor - Tuesday, May 30, 2017 - link
Everyone can go for the giant-die approach, but thanks to how marketing works, people will buy 8 A53s well before they even consider 4 A53 + 1 Cyclone-sized core.name99 - Wednesday, May 31, 2017 - link
Ding ding ding. We have a winnerWilco1 - Monday, May 29, 2017 - link
It was late 2014, and the first designs should appear late this year (just like Cortex-A73 was announced last year and appeared the same year). That is a 3 year gap, not 4 years.Note Cortex-A53 scaled quite well, from 1.3GHz in Exynos 5433 to 1.8GHz in Kirin (and goes up to 2.5GHz in Helio P25). The big cores scaled via yearly new micro-architectures, so the big/little performance ratio has remained similar.
> Fact is, there is only so much you can do with an in-order die-constrained design.
And more importantly not only keeping but actually improving power efficiency. It could go much faster if it were allowed a similar power budget as the big cores.