The Intel Optane SSD DC P4800X (375GB) Review: Testing 3D XPoint Performance
by Billy Tallis on April 20, 2017 12:00 PM ESTSequential Read
Intel provides no specifications for sequential access performance of the Optane SSD DC P4800X. Buying an Optane SSD for a mostly sequential workload would make very little sense given that sufficiently large flash-based SSDs or RAID arrays can offer plenty of sequential throughput. Nonetheless, it will be interesting to see how much faster the Optane SSD is with sequential transfers instead of random access.
Sequential access is usually tested with 128kB transfers, but this is more of an industry convention and is not based on any workload trend as strong as the tendency for random I/Os to be 4kB. The point of picking a size like 128kB is to have transfers be large enough that they can be striped across multiple controller channels and still involve writing a full page or more to the flash on each channel. Real-world sequential transfer sizes vary widely depending on factors like which application is moving the data or how fragmented the filesystem is.
Even without a large native page size to its 3D XPoint memory, we expect the Optane SSD DC P4800X to exhibit good performance from larger transfers. A large transfer requires the controller to process fewer operations for the same amount of user data, and fewer operations means less protocol overhead on the wire. Based on the random access tests, it appears that the Optane SSD is internally managing the 3D XPoint memory in a way that greatly benefits from transfers being at least 4kB even though the drive emulates a 512B sector size out of the box.
The drives were preconditioned with two full writes using 4kB random writes, so the data on each drive is entirely fragmented. This may limit how much prefetching of user data the drives can perform on the sequential read tests, but they can likely benefit from better locality of access to their internal mapping tables.
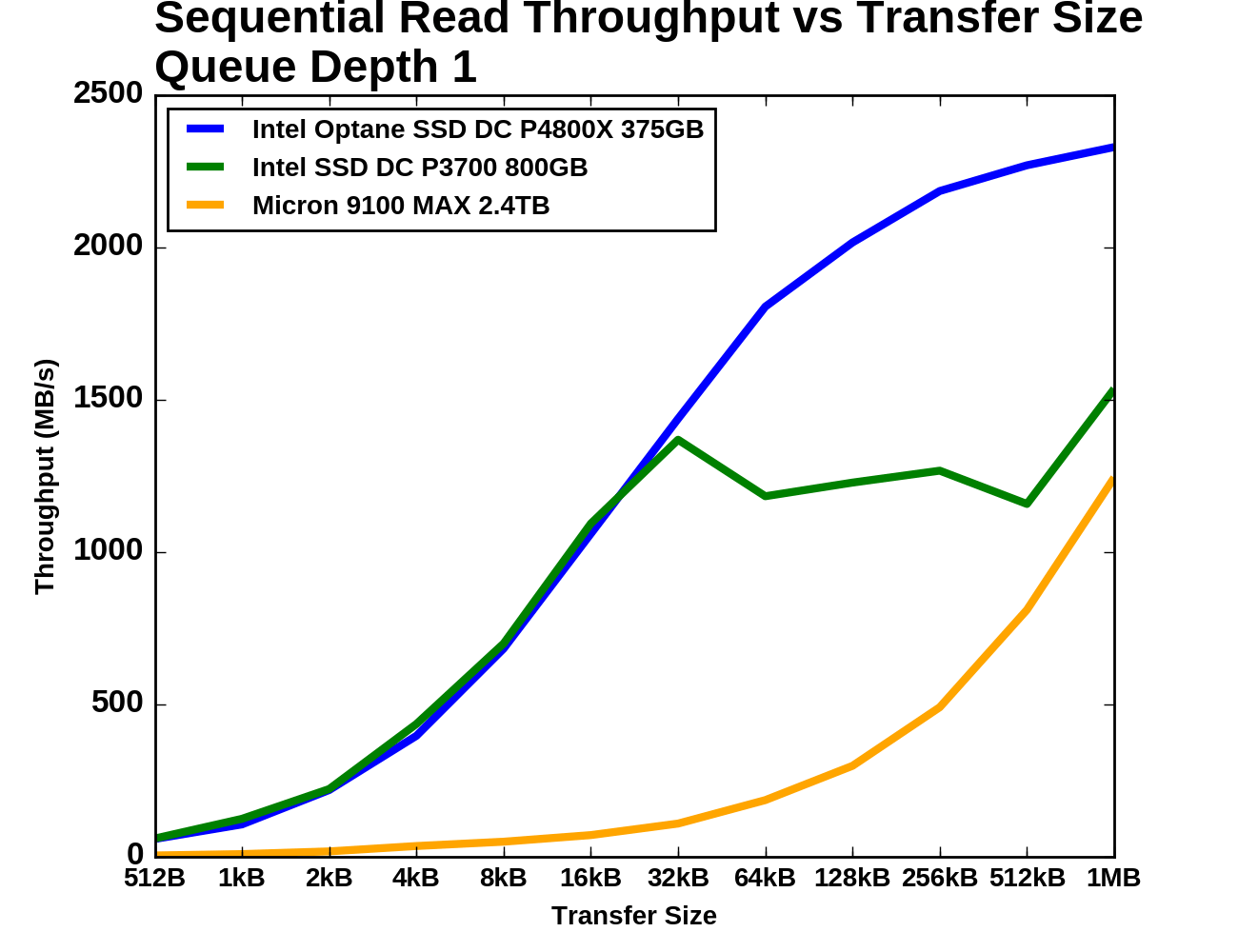
Queue Depth 1
The test of sequential read performance at different transfer sizes was conducted at queue depth 1. Each transfer size was used for four minutes, and the throughput was averaged over the final three minutes of each test segment.
 |
|||||||||
| Vertical Axis scale: | Linear | Logarithmic | |||||||
For transfer sizes up to 32kB, both Intel drives deliver similar sequential read speeds. Beyond 32kB the P3700 appears to be saturated but also highly inconsistent. The Micron 9100 is plodding along with very low but steadily growing speeds, and by the end of the test it has almost caught up with the Intel P3700. It was at least ten times slower than the Optane SSD until the transfer size reached 64kB. The Optane SSD passes 2GB/s with 128kB transfers and finishes the test at 2.3GB/s.
Queue Depth > 1
For testing sequential read speeds at different queue depths, we use the same overall test structure as for random reads: total queue depths of up to 64 are tested using a maximum of four threads. Each thread is reading sequentially but from a different region of the drive, so the read commands the drive receives are not entirely sorted by logical block address.
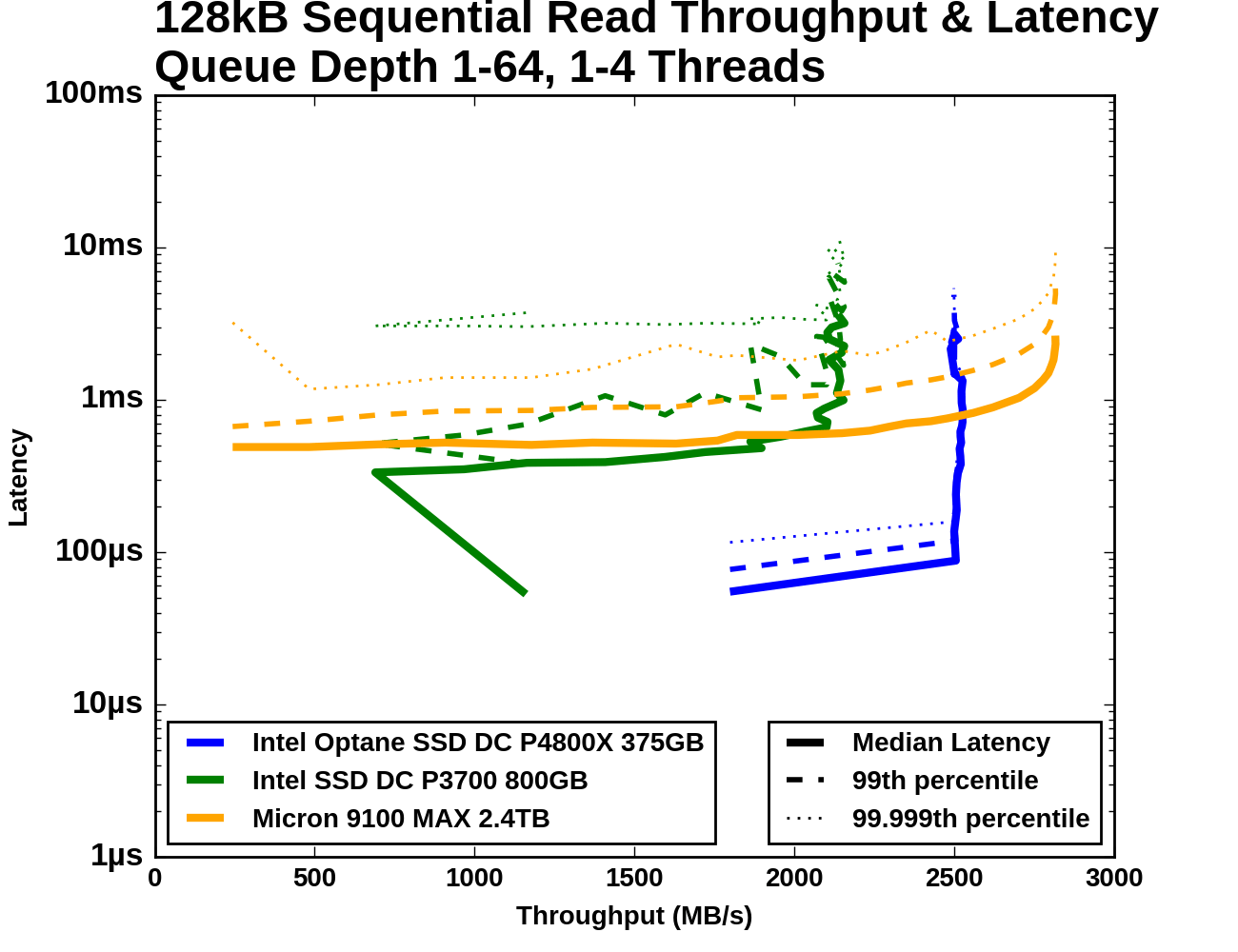
The Optane SSD DC P4800X starts out with a far higher QD1 sequential read speed than either flash SSD can deliver. The Optane SSD's median latency at QD1 is not significantly better than what the Intel P3700 delivers, but the P3700's 99th and 99.999th percentile latencies are at least an order of magnitude worse. Beyond QD1, the Optane SSD saturates while the Intel P3700 takes a temporary hit to throughput and a permanent hit to latency. The Micron 9100 starts out with low throughput and fairly high latency, but with increasing queue depth it manages to eventually surpass the Optane SSD's maximum throughput, albeit with ten times the latency.
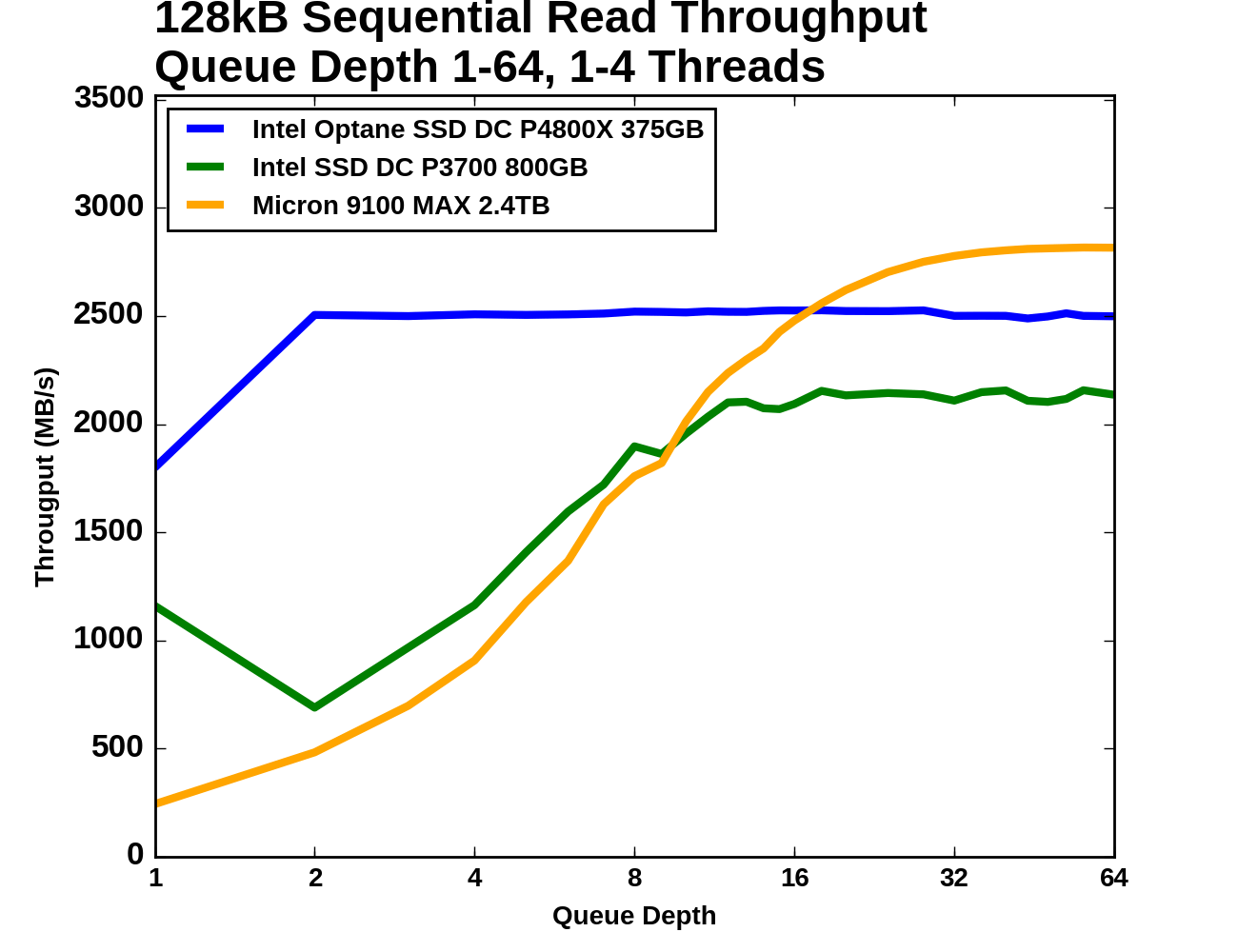 |
|||||||||
| Vertical Axis units: | IOPS | MB/s | |||||||
The Intel Optane SSD DC P4800X starts this test at 1.8GB/s for QD1, and delivers 2.5GB/s at all higher queue depths. The Intel P3700 performs significantly worse when a second QD1 thread is introduced, but by the time there are four threads reading from the drive the total throughput has recovered. The Intel P3700 saturates a little past QD8, which is where the Micron 9100 passes it. The Micron 9100 then goes on to surpass the Optane SSD's throughput above QD16, but it too has saturated by QD64.
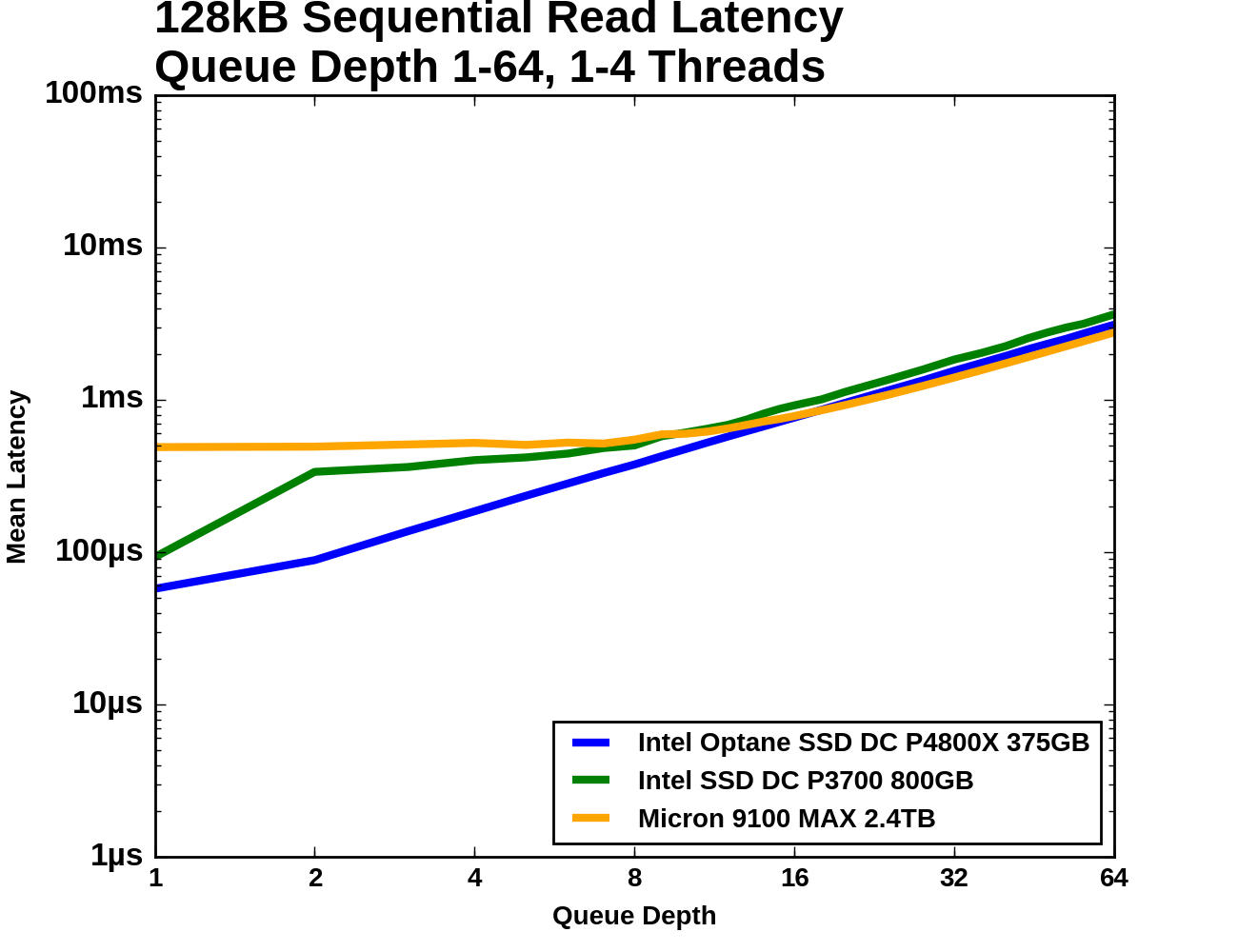 |
|||||||||
| Mean | Median | 99th Percentile | 99.999th Percentile | ||||||
The Optane SSD's latency increases modestly from QD1 to QD2, and then unavoidably increases linearly with queue depth due to the drive being saturated and unable to offer any better throughput. The Micron 9100 starts out with almost ten times the average latency, but is able to hold that mostly constant as it picks up most of its throughput. Once the 9100 passes the Optane SSD in throughput it is delivering slightly better average latency, but substantially higher 99th and 99.999th percentile latencies. The Intel P3700's 99.999th percentile latency is the worst of the three across almost all queue depths, and its 99th percentile latency is only better than the Micron 9100's during the early portions of the test.
Sequential Write
The sequential write tests are structured identically to the sequential read tests save for the direction the data is flowing. The sequential write performance of different transfer sizes is conducted with a single thread operating at queue depth 1. For testing a range of queue depths, a 128kB transfer size is used and up to four worker threads are used, each writing sequentially but to different portions of the drive. Each sub-test (transfer size or queue depth) is run for four minutes and the performance statistics ignore the first minute.
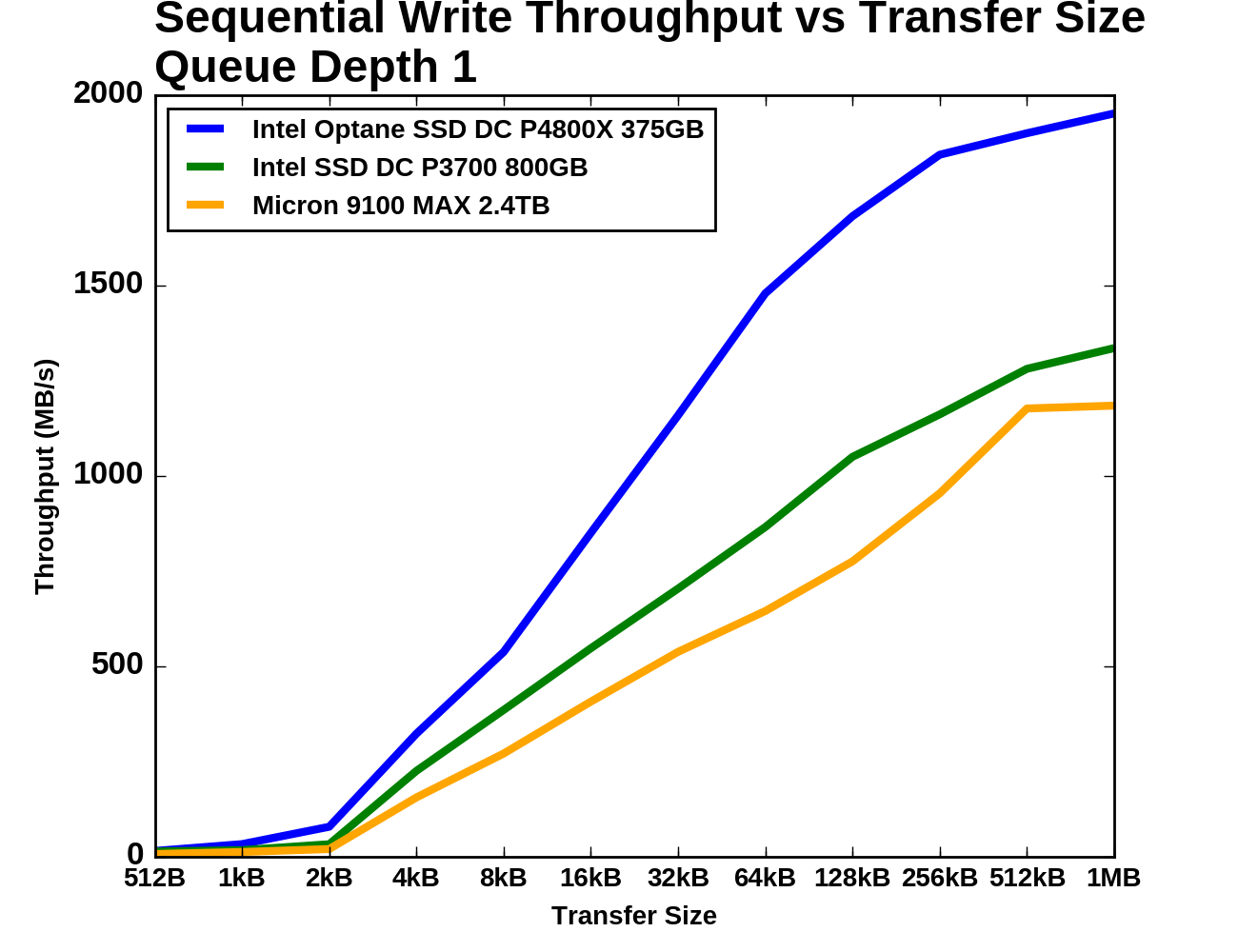 |
|||||||||
| Vertical Axis scale: | Linear | Logarithmic | |||||||
As with random writes, sequential write performance doesn't begin to take off until transfer sizes reach 4kB. Below that size, all three SSDs offer dramatically lower throughput, with the Optane SSD narrowly ahead of the Intel P3700. The Optane SSD shows the steepest growth as transfer size increases, but it and the Intel P3700 begin to show diminishing returns beyond 64kB. The Optane SSD almost reaches 2GB/s by the end of the test while the Intel P3700 and the Micron 9100 reach around 1.2-1.3GB/s.
Queue Depth > 1
When testing sequential writes at varying queue depths, the Intel SSD DC P3700's performance was highly erratic. We did not have sufficient time to determine what was going wrong, so its results have been excluded from the graphs and analysis below.
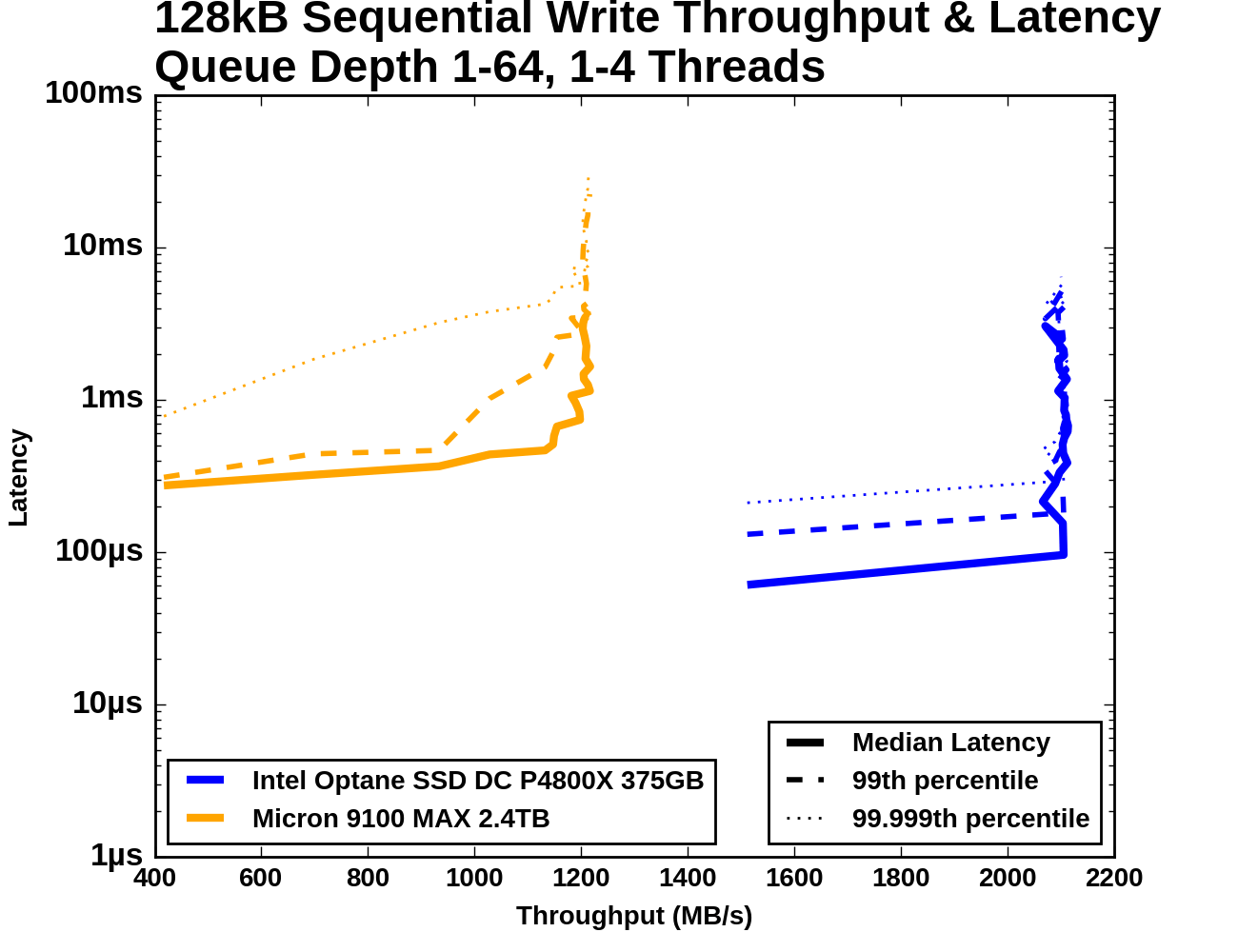
The Optane SSD DC P4800X delivers better sequential write throughput at every queue depth than the Micron 9100 can deliver at any queue depth. The Optane SSD's latency increases only slightly as it reaches saturation while the Micron 9100's 99th percentile latency begins to climb steeply well before that drive reaches its maximum throughput. The Micron 9100's 99.999th percentile latency also grows substantially as throughput increases, but its growth is more evenly spread across the range of queue depths.
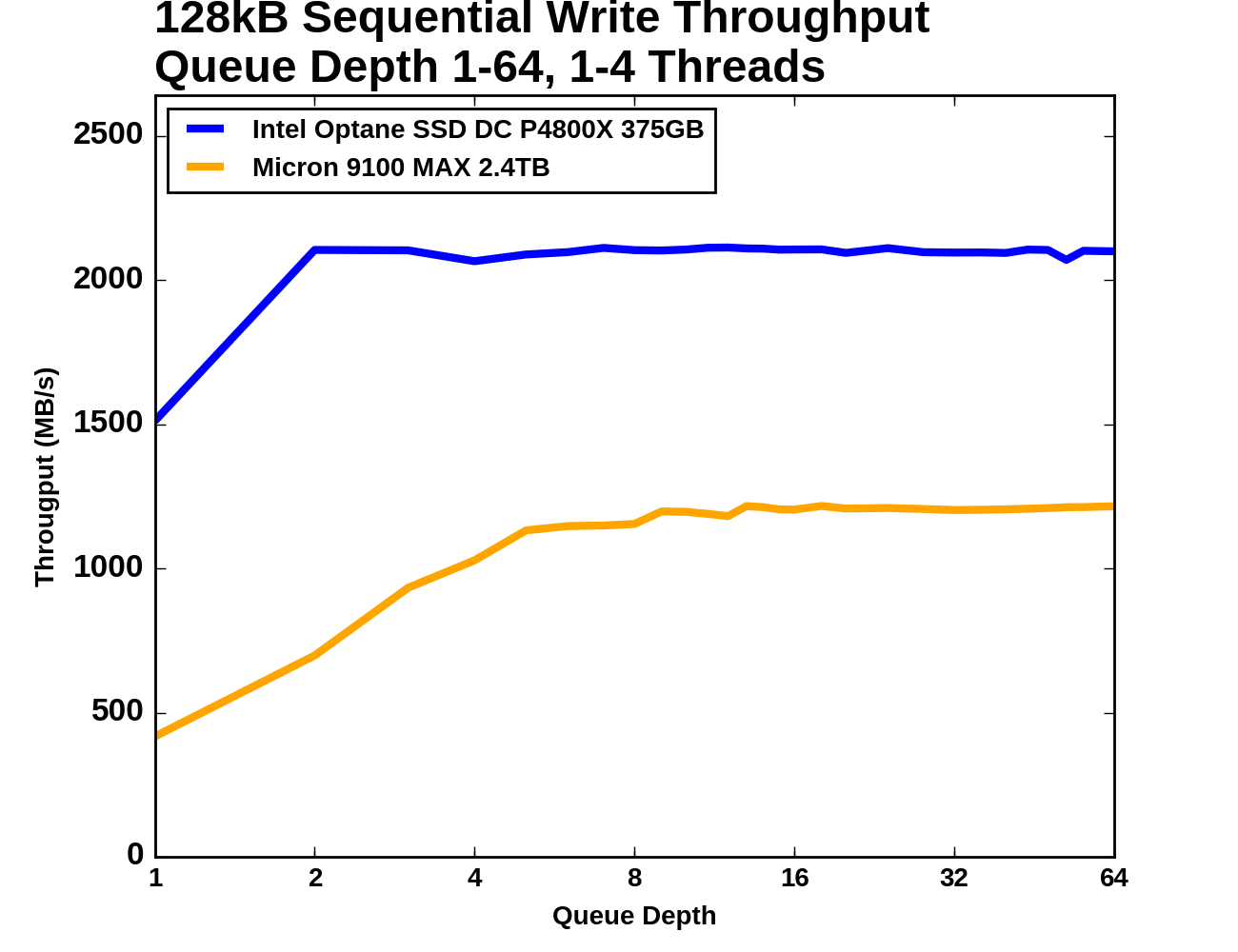 |
|||||||||
| Vertical Axis units: | IOPS | MB/s | |||||||
The Optane SSD reaches its maximum throughput at QD2 and maintains it as more threads and higher queue depths are introduced. The Micron 9100 only provides a little over half of the throughput and requires a queue depth of around 6-8 to reach that performance.
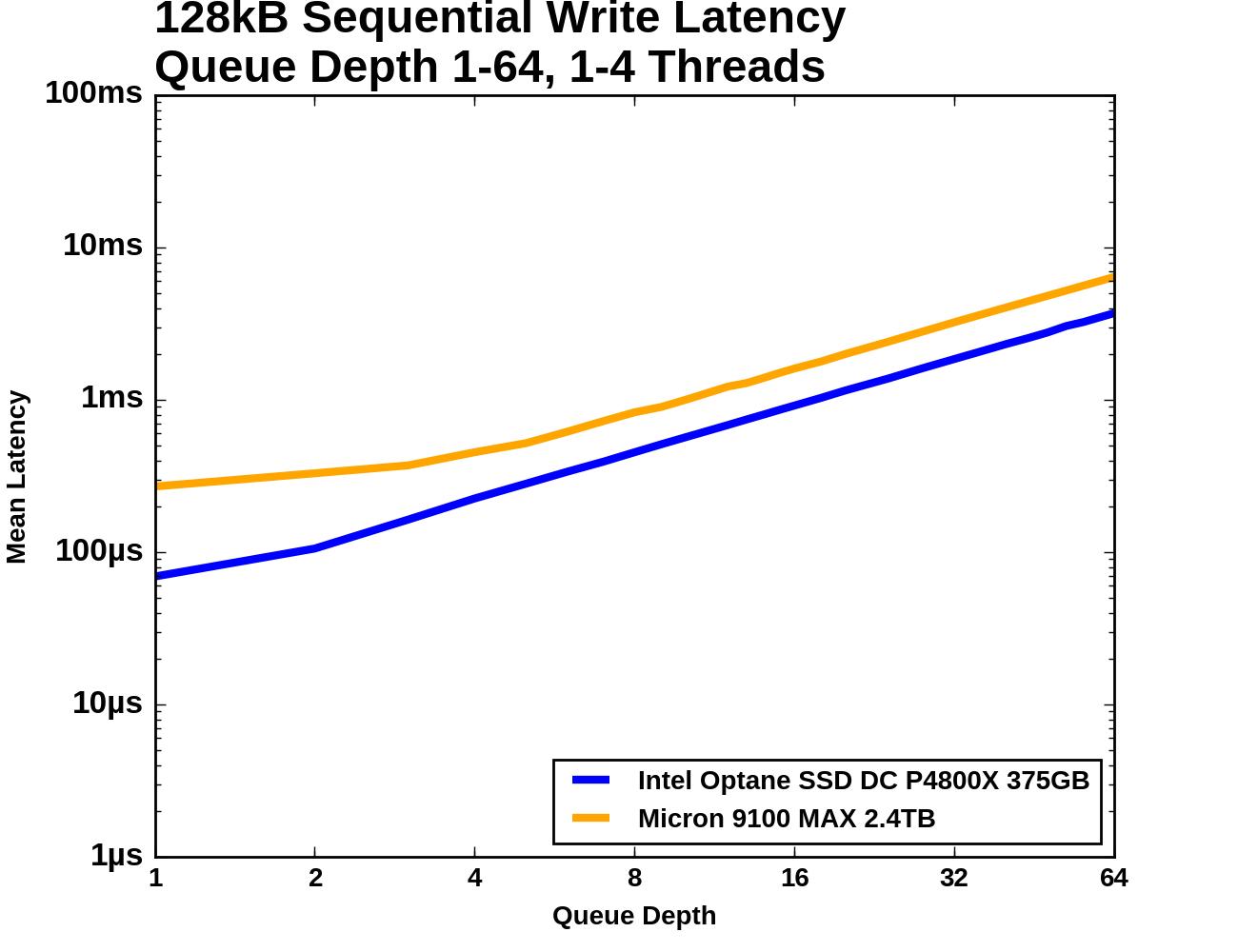 |
|||||||||
| Mean | Median | 99th Percentile | 99.999th Percentile | ||||||
The Micron 9100's 99th percentile latency starts out around twice that of the Optane SSD, but at QD3 it increases sharply as the drive approaches its maximum throughput until it is an order of magnitude higher than the Optane SSD. The 99.999th percentile latencies of the two drives are separated by a wide margin throughout the test.








117 Comments
View All Comments
ddriver - Friday, April 21, 2017 - link
*450 ns, by which I mean lower by 450 ns. And the current xpoint controller is nowhere near hitting the bottleneck of PCIE. It would take a controller that is at least 20 times faster than the current one to even get to the point where PCIE is a bottleneck. And even faster to see any tangible benefit from connecting xpoint directly to the memory controller.I'd rather have some nice 3D SLC (better than xpoint in literally every aspect) on PCIE for persistent storage RAM in the dimm slots. Hyped as superior, xpoint is actually nothing but a big compromise. Peak bandwidth is too low even compared to NVME NAND, latency is way too high and endurance is way too low for working memory. Low queue depths performance is good, but credit there goes to the controller, such a controller will hit even better performance with SLC nand. Smarter block management could also double the endurance advantage SLC already has over xpoint.
mdriftmeyer - Saturday, April 22, 2017 - link
ddriver is spot on. just to clarify an early comment. He's correct and the IntelUser2000 is out of his league.mdriftmeyer - Saturday, April 22, 2017 - link
Spot on.tuxRoller - Friday, April 21, 2017 - link
We don't know how much slower the media is than dram right now.We know than using dram over nvme has similar (though much better worst case) perf to this.
See my other post regarding polling and latency.
bcronce - Saturday, April 22, 2017 - link
Re-reading, I see it says "typical" latency is under 10us, placing it in spitting distance of DDR3/4. It's the 99.9999th percentile that is 60us for Q1. At Q16, 99.999th percentile is 140us. That means it takes only 140us to service 16 requests. That's pretty much the same as 10us.Read Q1 4KiB bandwidth is only about 500MiB/s, but at Q8, it's about 2GiB which puts it on par with DDR4-2400.
ddriver - Saturday, April 22, 2017 - link
"placing it in spitting distance of DDR3/4"I hope you do realize that dram latency is like 50 NANOseconds, and 1 MICROsecond is 1000 NANOseconds.
So 10 us is actually 200 times as much as 50 ns. Thus making hypetane about 200 times slower in access latency. Not 200%, 200X.
tuxRoller - Saturday, April 22, 2017 - link
Yes, the dram media is that fast but when it's exposed through nvme it has the latency characteristics that bcronce described.wumpus - Sunday, April 23, 2017 - link
That's only on a page hit. For the type of operations that 3dxpoint is looking at (4k or so) you won't find it on an open page and thus take 2-3 times as long till it is ready.That still leaves you with ~100x latency. And we are still wondering if losing the PCIe controller will make any significant difference to this number (one problem is that if Intel/Micron magically fixed this, the endurance is only slightly better than SLC and would quickly die if used as main memory).
ddriver - Sunday, April 23, 2017 - link
Endurance for the initial batch postulated from intel's warranty would be around 30k PE cycles, and 50k for the upcoming generation. That's not "only slightly better than SLC" as SCL has 100k PE cycles endurance. But the 100k figure is somewhat old, and endurance goes down with process node. So at a comparable process, SLC might be going down, approaching 50k.It remains to be seen, the lousy industry is penny pinching and producing artificial NAND shortages to milk people as much as possible, and pretty much all the wafers are going into TLC, some MLC and why oh why, QLC trash.
I guess they are saving the best for last. 3D SLC will address the lower density, samsung currently has 2 TB MLC M2, so 1 TB is perfectly doable via 3D SLC. I am guessing samsung's z-nand will be exactly that - SLC making a long overdue comeback.
tuxRoller - Sunday, April 23, 2017 - link
The endurance issue is, imho, the biggest concern right now.