The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTPower, Performance, and Pre-Fetch: AMD SenseMI
Part of the demos leading up to the launch involved a Handbrake video transcode: a multithreaded test, showing a near-identical completion time between a high-frequency Ryzen without turbo compared to an i7-6900K at similar frequencies. Similarly we saw a Blender test we saw back in August achieving the same feat. AMD at the time also fired up some power meters, showing that Ryzen power consumption in that test was a few watts lower than the Intel part, implying that AMD is meeting its targets for power, performance and as a result, efficiency. The 52% improvement in IPC/efficiency is a result AMD seems confident that this target has been surpassed.

Leading up to the launch, AMD explained during our briefings that during the Zen design stages, up to 300 engineers were working on the core engine with an aggressive mantra of higher IPC for no power gain. This has apparently lead to over two million work hours of time dedicated to Zen. This is not an uncommon strategy for core designs. Part of this time will be spent devoping new power modes, and part of Zen is is that optimization and extension of the power/frequency curve: a key point in AMD’s new 5-stage ‘SenseMI’ technology.
SenseMI Stage 1: Pure Power
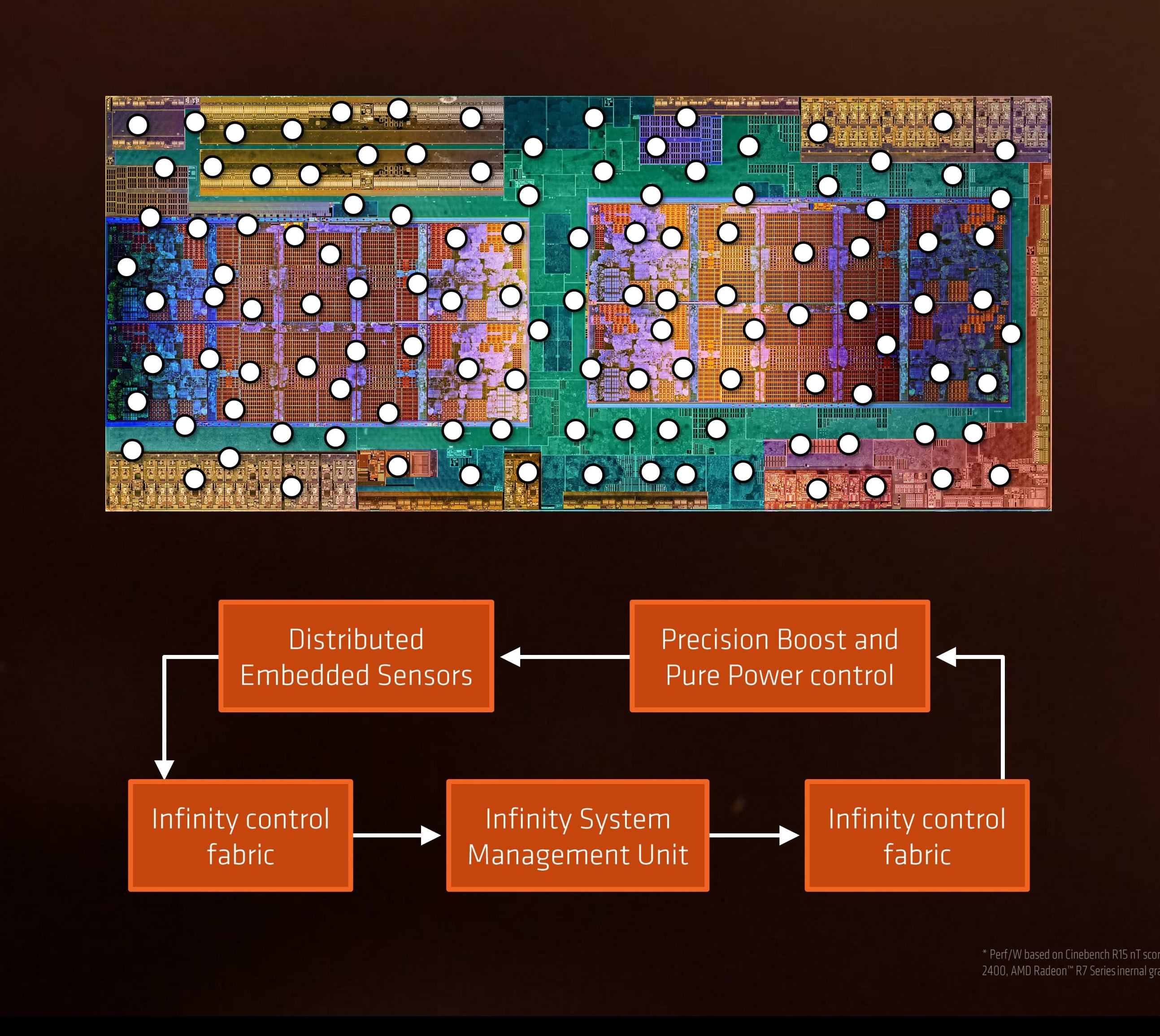
A number of recent microprocessor launches have revolved around silicon-optimized power profiles. We are now removed from the ‘one DVFS curve fits all’ application for high-end silicon, and AMD’s solution in Ryzen will be called Pure Power. The short explanation is that using distributed embedded sensors in the design (first introduced in bulk with Carrizo) that monitor temperature, speed and voltage, and the control center can manage the power consumption in real time. The glue behind this technology comes in form of AMD’s new ‘Infinity Fabric’.
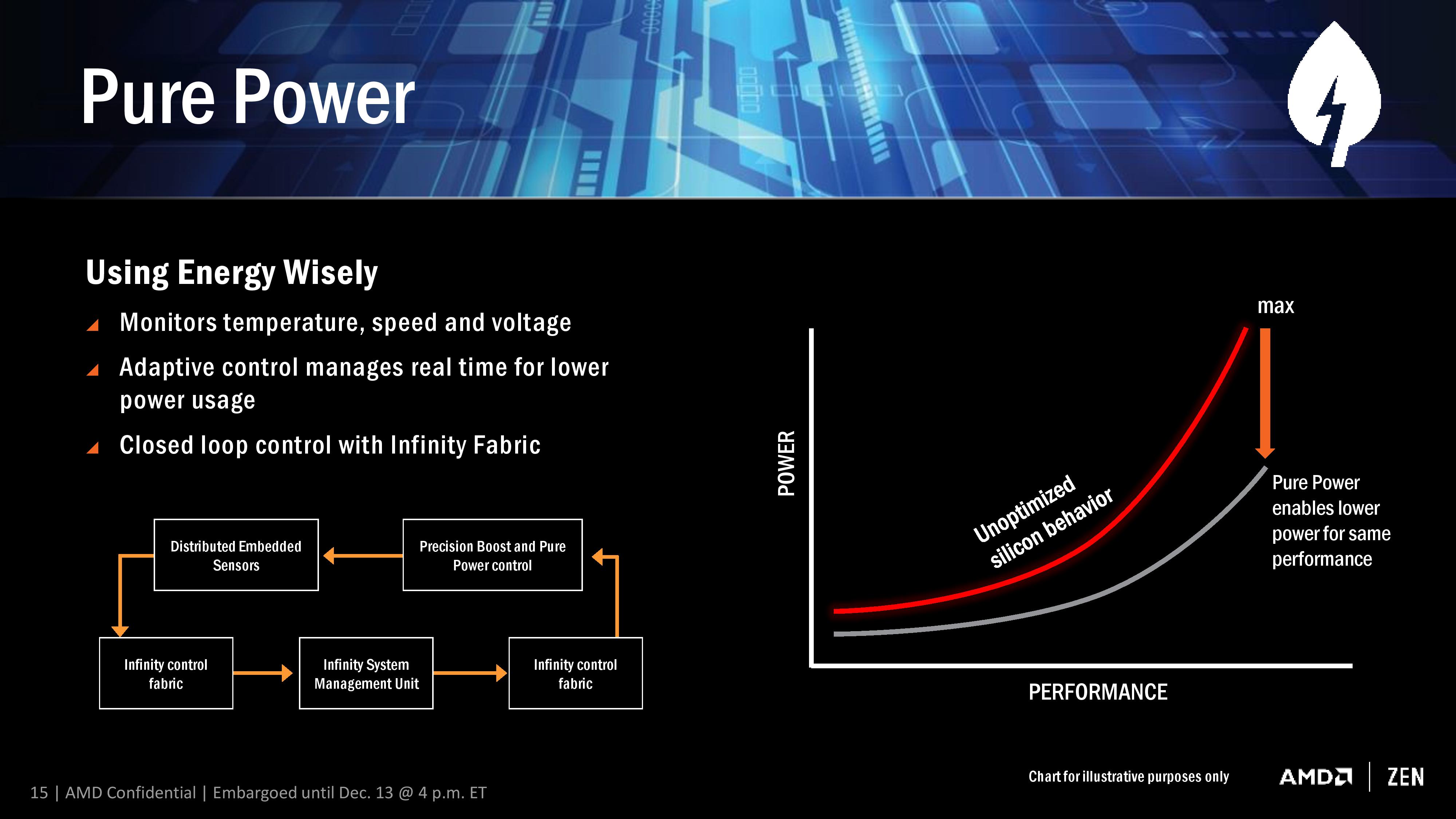
The fact that it’s described as a fabric means that it goes through the entire processor, connecting various parts together as part of that control. This is something wildly different to what we saw in Carrizo, aside from being the next-gen power adjustment and under a new name, and will permiate through Zen, Vega, and future AMD products.
The upshot of Pure Power is that the DVFS curve is lower and more optimized for a given piece of silicon than a generic DVFS curve, which results in giving lower power at various/all levels of performance. This in turn benefits the next part of SenseMI, Precision Boost.
SenseMi Stage 2: Precision Boost
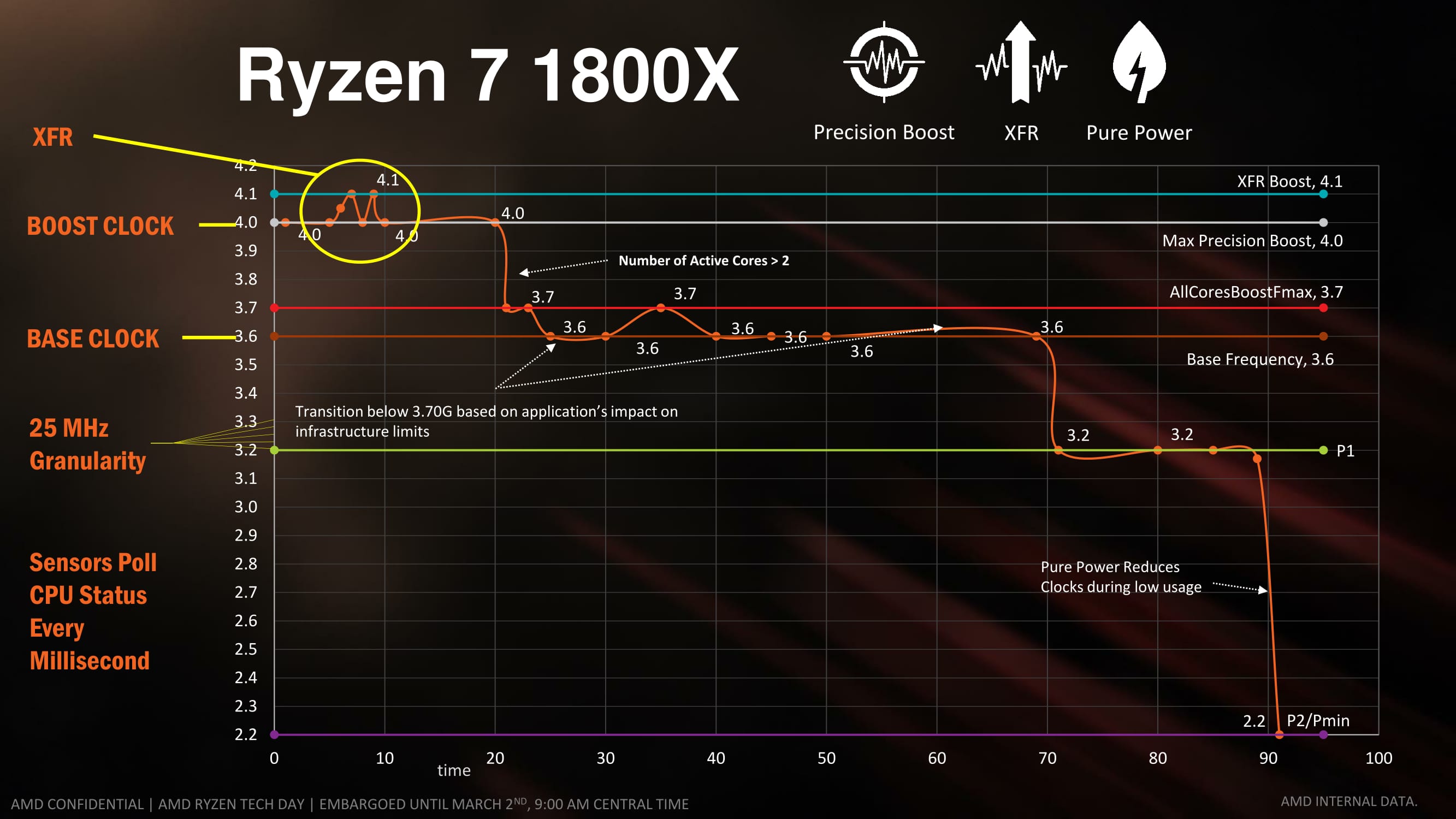
For almost a decade now, most commercial PC processors have invoked some form of boost technology to enable processors to use less power when idle and fully take advantage of the power budget when only a few elements of the core design is needed. We see processors that sit at 2.2 GHz that boost to 2.7 GHz when only one thread is needed, for example, because the whole chip still remains under the power limit. AMD is implementing Precision Boost for Ryzen, increasing the DVFS curve to better performance due to Pure Power, but also offering frequency jumps in 25 MHz steps which is new.
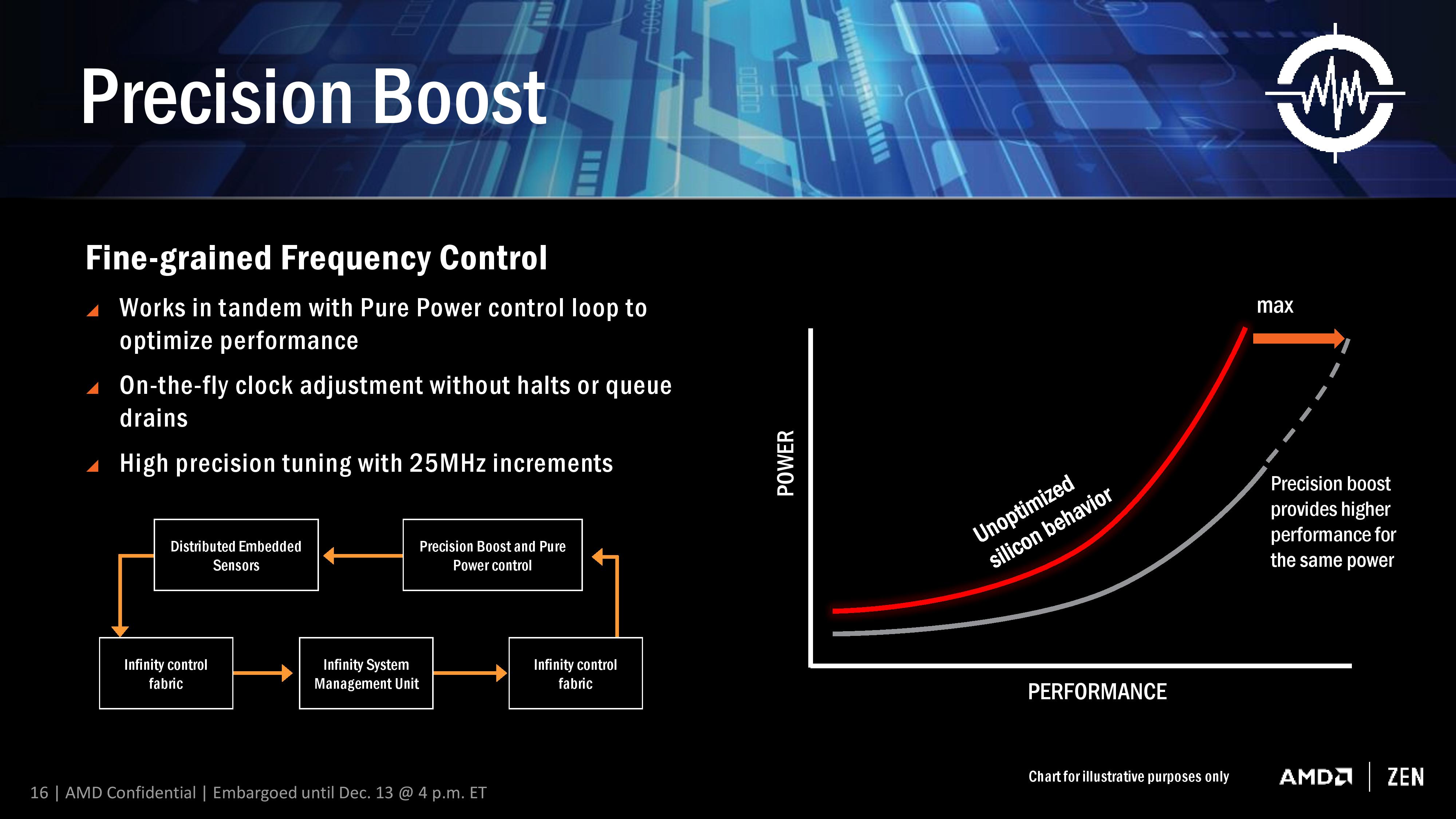
Precision Boost relies on the same Infinity Control Fabric that Pure Power does, but allows for adjustments of core frequency based on performance requirements and suitability/power given the rest of the core. The fact that it offers 25 MHz steps is surprising, however.
Current turbo control systems, on both AMD and Intel, are invoked by adjusting the CPU frequency multiplier. With the 100 MHz base clock on all modern CPUs, one step in frequency multiplier gives 100 MHz jump for the turbo modes, and any multiple of the multiplier can be used on the basis of whole numbers only.
With AMD moving to 25 MHz jumps in their turbo, this means either AMD can implement 0.25x fractional multipliers, similar to how processors in the early 2000s were able to negotiate 0.5x multiplier jumps. What this means in reality is that the processor has over 100 different frequencies it can potentially operate at, although control of the fractional multipliers below P0 is left to XFR (below).
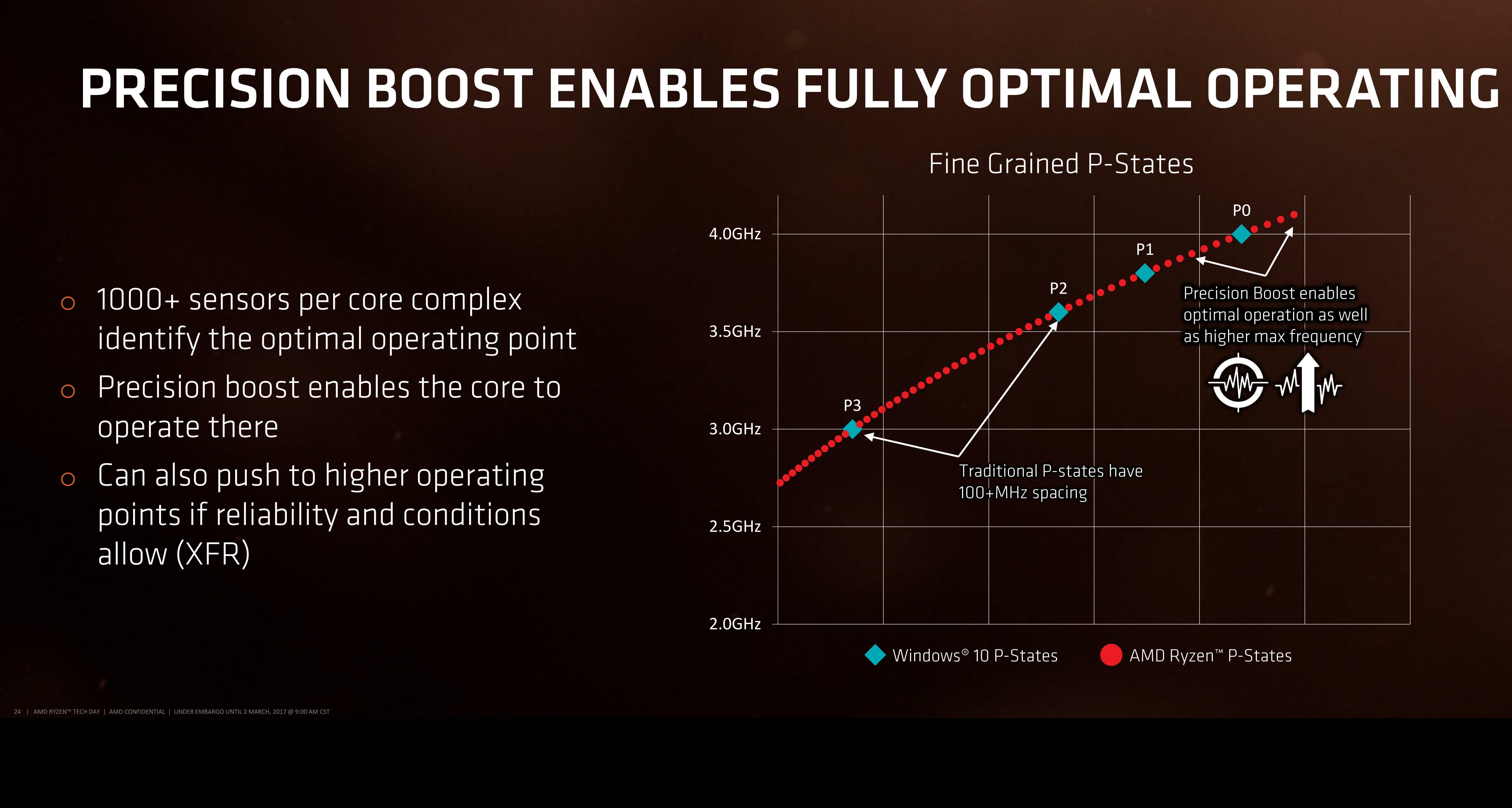
Part of this comes down to the extensive sensor technology, originally debuted for AMD in Carrizo at scale, but now offering almost 1000 sensors per chip to analyze at what frequency the core can run at. AMD controls all frequency of each core independently, which suggests that users might be able to find the highest performing core and lock important software on it.
If we consider that Zen’s original chief designer was Jim Keller (and his team), known for a number of older generation of AMD processors, a similar fractional multiplier technology might be in play here. If/when we get more information on it, we will let you know.
SenseMi Stage 3: Extended Frequency Range (XFR)
The main marketing points of on-the-fly frequency adjustment are typically down to low idle power and higher performance when needed. The current processors on the market have rated speeds on the box which are fixed frequency settings that can be chosen by the processor/OS depending on what level of performance is possible/required. AMD’s new XFR mode seems to do away with this, offering what sounds like an unlimited bound on performance.
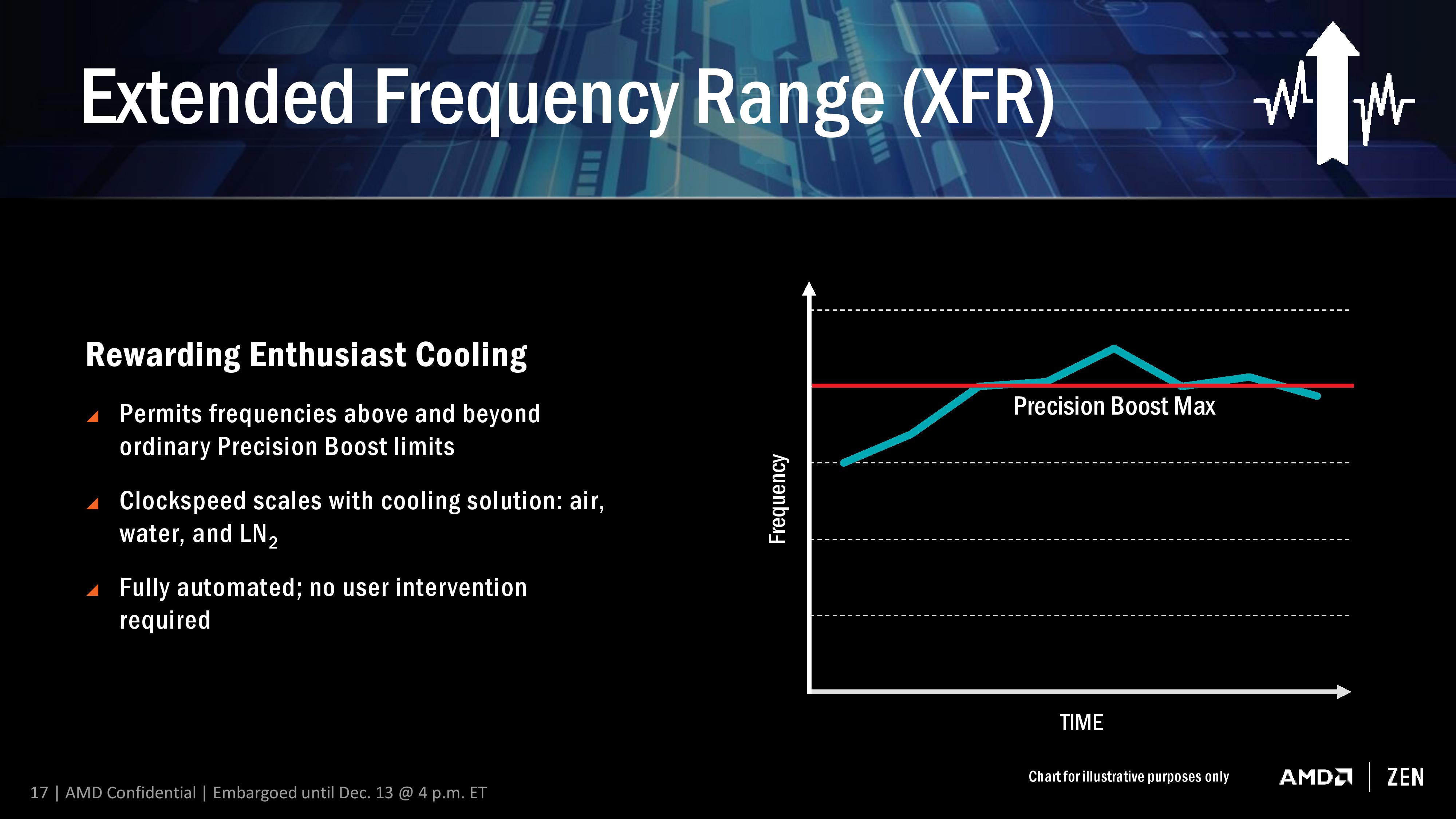
The concept here is that, beyond the rated turbo mode, if there is sufficient cooling then the CPU will continue to increase the clock speed and voltage until a cooling limit is reached. This is somewhat murky territory, though AMD claims that a multitude of different environments can be catered for the feature. AMD was not clear if this limit is determined by power consumption, temperature, or if they can protect from issues such as a bad frequency/voltage setting.
This is a dynamic adjustment rather than just another embedded look-up table such as P-states. AMD states that XFR is a fully automated system with no user intervention, although I suspect in time we might see an on/off switch in the BIOS. It also somewhat negates overclocking if your cooling can support it, which then brings up the issue for overclocking in general: casual users may not ever need to step into the overclocking world if the CPU does it all automatically.
I imagine that a manual overclock will still be king, especially for extreme overclockers competing with liquid nitrogen, as being able to personally fine tune a system might be better than letting the system do it itself. It can especially be true in those circumstances, as sensors on hardware can fail, report the wrong temperature, or may only be calibrated within a certain range.

XFR will be on every consumer CPU (as the Zen microarchitecture is destined for server and mobile as well, XFR might have different connotations for both of those markets), and typically will allow for +100 MHz. CPUs that have the extra 'X' should allow for up to +200 MHz through XFR. This level of XFR is not set in stone, and may change in future CPUs.
SenseMi Stage 4+5: Neural Net Prediction and Smart Prefetch
Every generation of CPUs from the big companies come with promises of better prediction and better pre-fetch models. These are both important to hide latency within a core which might be created by instruction decode, queuing, or more usually, moving data between caches and main memory to be ready for the instructions. With Ryzen, AMD is introducing its new Neural Net Prediction hardware model along with Smart Pre-Fetch.
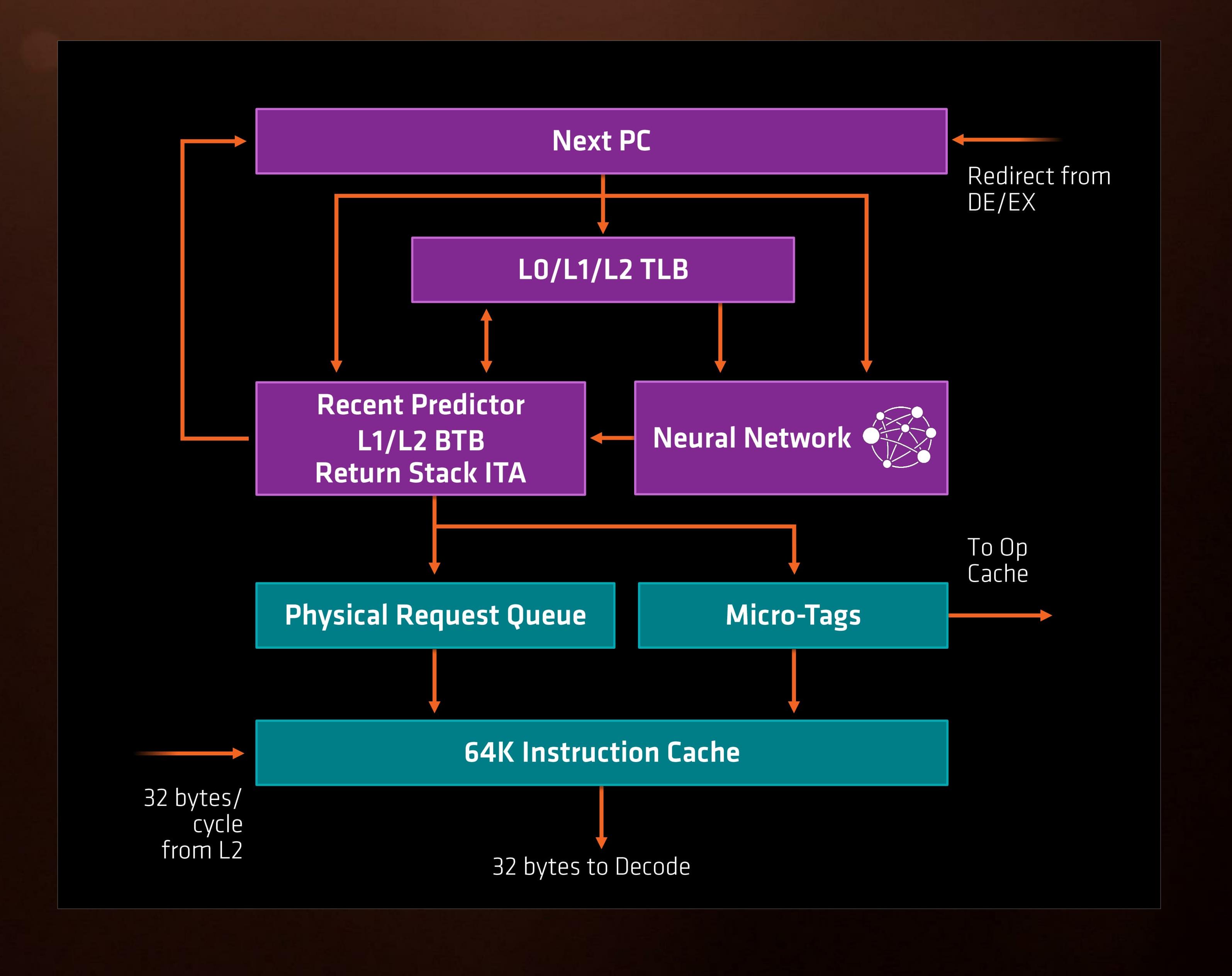
AMD is announcing this as a ‘true artificial network inside every Zen processor that builds a model of decisions based on software execution’. This can mean one of several things, ranging from actual physical modelling of instruction workflow to identify critical paths to be accelerated (unlikely) or statistical analysis of what is coming through the engine and attempting to work during downtime that might accelerate future instructions (such as inserting an instruction to decode into an idle decoder in preparation for when it actually comes through, therefore ends up using the micro-op cache and making it quicker).

For Zen this means two branches can be predicted per cycle (so, one per thread per cycle), and a multi-level TLB to assist recently required instructions again. With these caches and buffers, typically doubling in size gets a hit rate of sqrt(2), or +41%, for double the die area, and it becomes a balance of how good you want it to be compared with how much floor plan area can be dedicated to it.

Modern processors already do decent jobs when repetitive work is being used, such as identifying when every 4th element in a memory array is being accessed, and can pull that data in earlier to be ready in case it is used. The danger of smart predictors however is being overly aggressive – pulling in too much data that old data might be ditched because it’s never used (over prediction), pulling in too much data such that it’s already evicted by the time the data is needed (aggressive prediction), or simply wasting excess power with bad predictions (stupid prediction…).
AMD is stating that Zen implements algorithm learning models for both instruction prediction and prefetch, which will no doubt be interesting to see if they have found the right balance of prefetch aggression and extra work in prediction.
It is worth noting here that AMD will likely draw upon the increased L3 bandwidth in the new core as a key element to assisting the prefetch, especially as the shared L3 cache is an exclusive victim cache and designed to contain data already used/evicted to be used again at a later date.








574 Comments
View All Comments
ABR - Sunday, March 5, 2017 - link
Are there any examples of games at 1080p where this actually matters? (I.e., not a drop from 132 to 108 fps, but from 65 to 53 or 42 to 34?)ABR - Monday, March 6, 2017 - link
I mean at 1080p. (Edit, edit...)0ldman79 - Monday, March 6, 2017 - link
That's my thought as well.Seriously, it isn't like we're talking unplayable, it is still ridiculous gaming levels. It is almost guaranteed to be a scheduler problem in Windows judging by the performance deficit compared to other applications. If it isn't, it is still running very, very well.
Hell, I can play practically anything I can think of on my FX 6300, I don't really *need* a better CPU right now, I'm just really, really tempted and looking for excuses (I can't encode at the same speed in software as my Nvidia encoder, damn, I need to upgrade...)
Outlander_04 - Monday, March 6, 2017 - link
Do you think anyone building a computer with a $500 US chip is going to just be spending $120 on a 1080p monitor?More likely they will be building it for higher resolutions
Notmyusualid - Tuesday, March 7, 2017 - link
I've seen it happen...mdriftmeyer - Tuesday, March 7, 2017 - link
Who gives a crap if you've seen it happen. Your experience is an anomaly relative to the totality of statistical data.Notmyusualid - Wednesday, March 8, 2017 - link
Or somebody was just happy with their existing screen?I can actually point to two friends with 1080 screens, both lovely water cooled rigs, one is determined to keep his high-freq 1080 screen, and the other one just doesn't care. So facts is facts son.
I guess it is YOU that gives that crap afterall.
Zaggulor - Thursday, March 9, 2017 - link
Statistical data suggests that people don't actually often get a new display when they change a GPU and quite often that same display will be moved to a new rig too.Average upgrade times for components are:
CPU: ~4.5 years
GPU: ~2.5 years
Display: ~7 years
These days you can also use any unused GPU resources for downsampling even if your CPU can't push any more frames. Both GPU vendors have build in support for it (VSR/DSR).
hyno111 - Wednesday, March 8, 2017 - link
Or a $200 1080p/144Hz/Freesync monitor.Marburg U - Sunday, March 5, 2017 - link
I guess it's time to retire my Core 2 Quad.