The AMD Vega GPU Architecture Teaser: Higher IPC, Tiling, & More, Coming in H1’2017
by Ryan Smith on January 5, 2017 9:00 AM ESTVega’s NCU: Packed Math, Higher IPC, & Higher Clocks
As always, I want to start at the heart of the matter: the shader core. In some respects AMD has not significantly altered their shader core since the launch of the very first GCN parts 5 years ago. Various iterations of GCN have added new instructions and features, but the shader core has remained largely constant, and IPC within the shader core itself hasn’t changed too much. Even Polaris (GCN 4) followed this trend, sharing its whole ISA with GCN 1.2.
With Vega, this is changing. By just how much remains to be seen, but it is clear that even with what we see today, AMD is already undertaking the biggest change to their shader core since the launch of GCN.

Meet the NCU, Vega’s next-generation compute unit. As we already learned from the PlayStation 4 Pro launch and last month’s Radeon Instinct announcement, AMD has been working on adding support for packed math formats for future architectures, and this is coming to fruition in Vega.
With their latest architecture, AMD is now able to handle a pair of FP16 operations inside a single FP32 ALU. This is similar to what NVIDIA has done with their high-end Pascal GP100 GPU (and Tegra X1 SoC), which allows for potentially massive improvements in FP16 throughput. If a pair of instructions are compatible – and by compatible, vendors usually mean instruction-type identical – then those instructions can be packed together on a single FP32 ALU, increasing the number of lower-precision operations that can be performed in a single clock cycle. This is an extension of AMD’s FP16 support in GCN 1.2 & GCN 4, where the company supported FP16 data types for the memory/register space savings, but FP16 operations themselves were processed no faster than FP32 operations.
And while previous announcements may have spoiled that AMD offers support for packed FP16 formats, what we haven’t known for today is that they will also support a high-speed path (analogous to packed FP16) for 8-bit integer operations. INT8 is a data format that has proven especially useful for neural network inference – the actual execution of trained neural networks – and is a major part of what has made NVIDIA’s most recent generation of Pascal GPUs so potent at inferencing. By running dot products and certain other INT8 operations along this path, INT8 performance can be greatly improved.
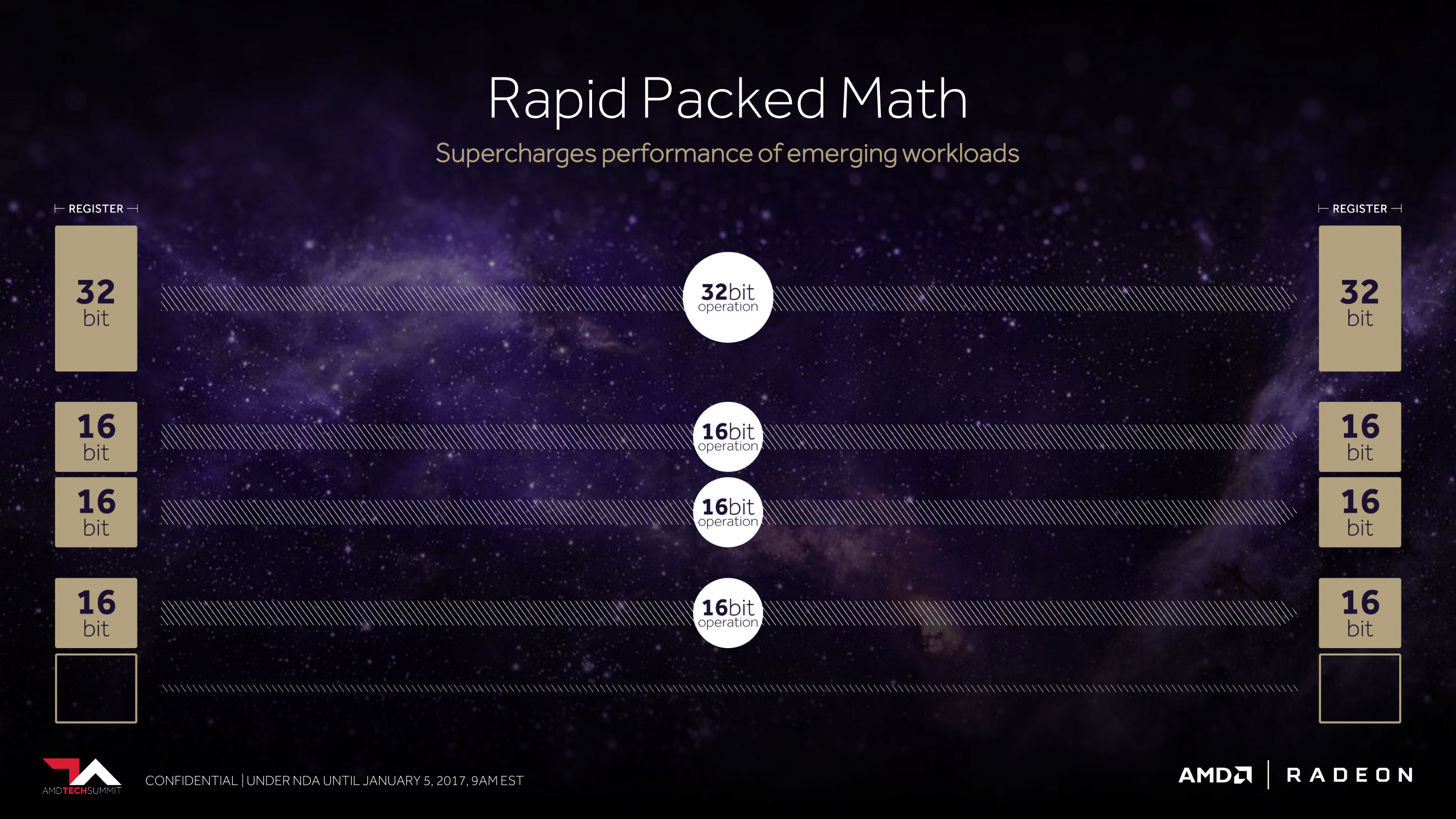
Though before we get too far – and this is a longer discussion to have closer to Vega’s launch – it’s always important to note when and where these faster operations can be used in consumer workloads, as the odds are most of you reading this are thinking gaming. While FP16 operations can be used for games (and in fact are in the mobile space), in the PC space they are virtually never used. When PC GPUs made the jump to unified shaders in 2006/2007, the decision was made to do everything at FP32 since that’s what vertex shaders typically required to begin with, and it’s only recently that anyone has bothered to look back. So while there is some long-term potential here for Vega’s fast FP16 math to become relevant for gaming, at the moment it wouldn’t do anything. Vega will almost certainly live and die in the gaming space based on its FP32 performance.
Moving on, the second thing we can infer from AMD’s slide is that a CU on Vega is still composed of 64 ALUs, as 128 FP32 ops/clock is the same rate as a classic GCN CU. Nothing here is said about how the Vega NCU is organized – if it’s still four 16-wide vector SIMDs – but we can at least reason out that the total size hasn’t changed.

Finally, along with outlining their new packed math formats, AMD is also confirming, at a high level, that the Vega NCU is optimized for both higher clockspeeds and a higher IPC. It goes without saying that both of these are very important to overall GPU performance, and it’s an area where, very broadly speaking, AMD hasn’t compared to NVIDIA too favorably. The devil is in the details, of course, but a higher clockspeed alone would go a long way towards improving AMD’s performance. And as AMD’s IPC has been relatively stagnant for some time here, improving it would help AMD put their relatively sizable lead in total ALUs to good use. AMD has always had a good deal more ALUs than a comparable NVIDIA chip, but getting those ALUs to all do useful work outside of corner cases has always been difficult.
That said, I do think it’s important not to read too much into this on the last point, especially as AMD has drawn this slide. It’s fairly muddled whether “higher IPC” means a general increase in IPC, or if AMD is counting their packed math formats as the aforementioned IPC gain.
Geometry & Load Balancing: Faster Performance, Better Options
As some of our more astute readers may recall, when AMD launched the GCN 1.1 they mentioned that at the time, GCN could only scale out to 4 of what AMD called their Shader Engines; the logical workflow partitions within the GPU that bundled together a geometry engine, a rasterizer, CUs, and a set of ROPs. And when the GCN 1.2 Fiji GPU was launched, while AMD didn’t bring up this point again, they still held to a 4 shader engine design, presumably due to the fact that GCN 1.2 did not remove this limitation.
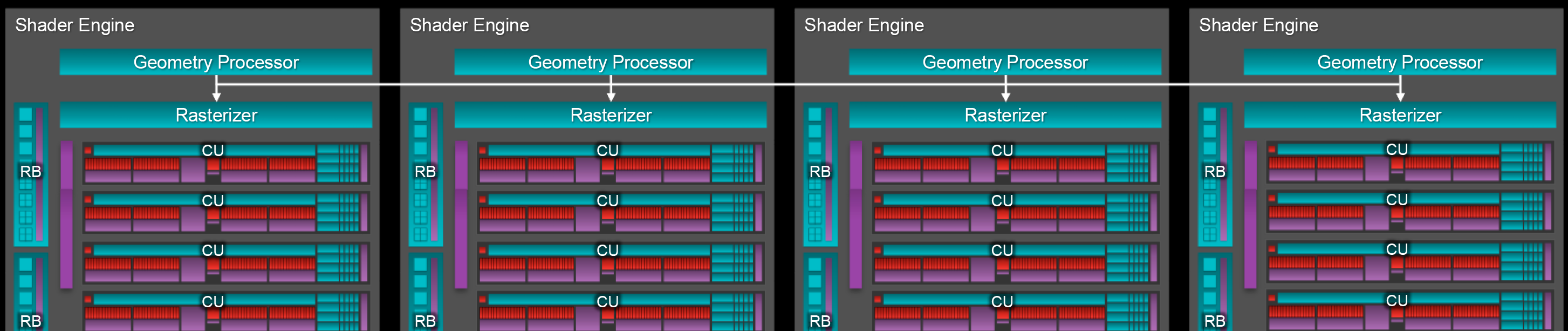
Fiji 4x Shader Engine Layout
But with Vega however, it looks like that limitation has finally gone away. AMD is teasing that Vega offers an improved load balancing mechanism, which pretty much directly hints that AMD can now efficiently distribute work over more than 4 engines. If so, this would represent a significant change in how the GCN architecture works under the hood, as work distribution is very much all about the “plumbing” of a GPU. Of the few details we do have here, AMD has told us that they are now capable of looking across draw calls and instances, to better split up work between the engines.

This in turn is a piece of the bigger picture when looking at the next improvement in Vega, which is AMD’s geometry pipeline. Overall AMD is promising a better than 2x improvement in peak geometry throughput per clock. Broadly speaking, AMD’s geometry performance in recent generations hasn’t been poor (it’s one of the areas where Polaris even further improved), but it has also hurt them at times. So this is potentially important for removing a bottleneck to squeezing more out of GCN.
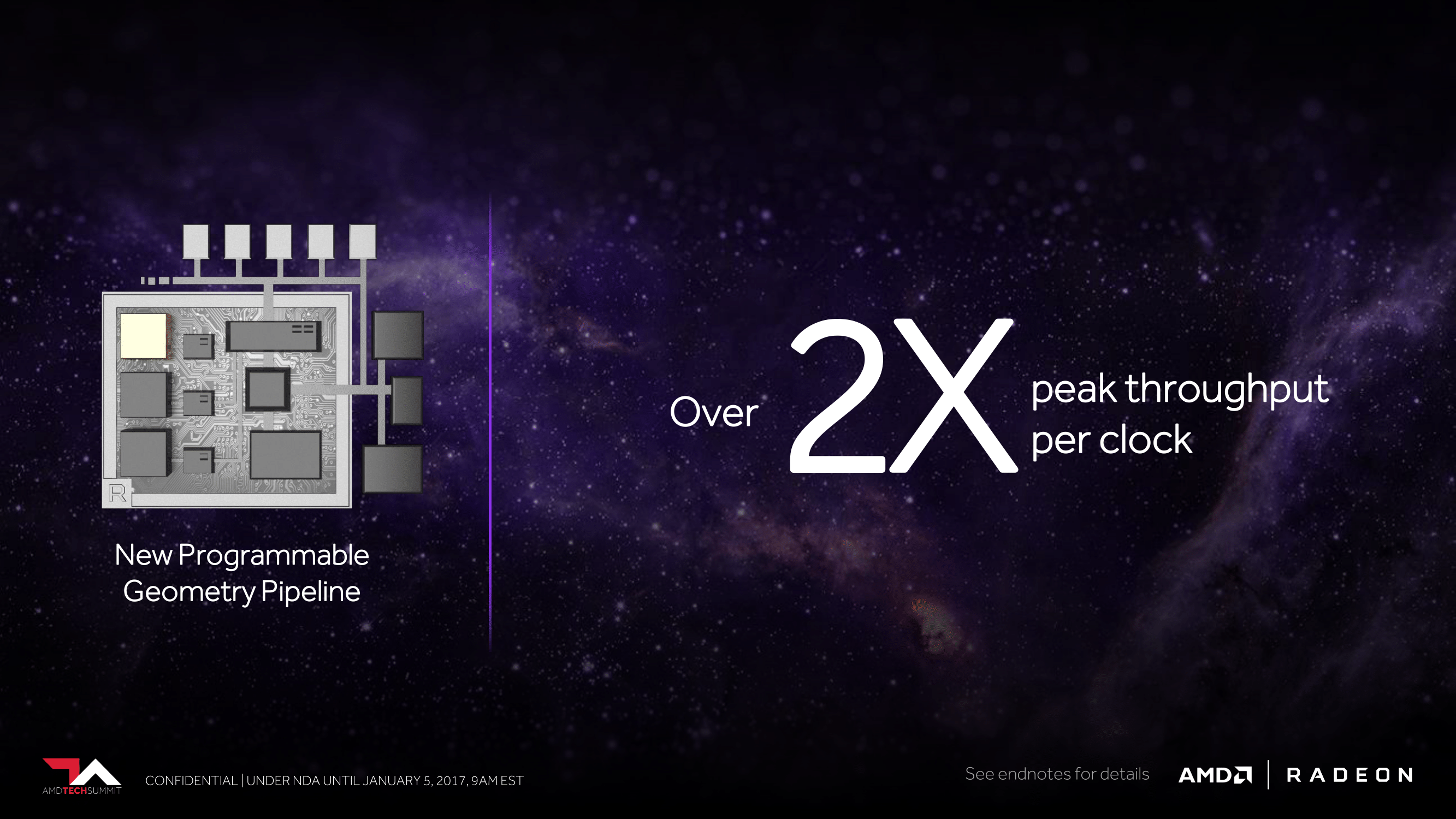
And while AMD's presentation and comments itself don't go into detail on how they achieved this increase in throughput, buried in the footnote for AMD's slide deck is this nugget: "Vega is designed to handle up to 11 polygons per clock with 4 geometry engines." So this clearly reinforces the idea that the overall geometry performance improvement in Vega comes from improving the throughput of the individual geometry engines, as opposed to simply adding more as the scalability improvements presumably allow. This is one area where Vega’s teaser paints a tantalizing view of future performance, but in the process raises further questions on just how AMD is doing it.
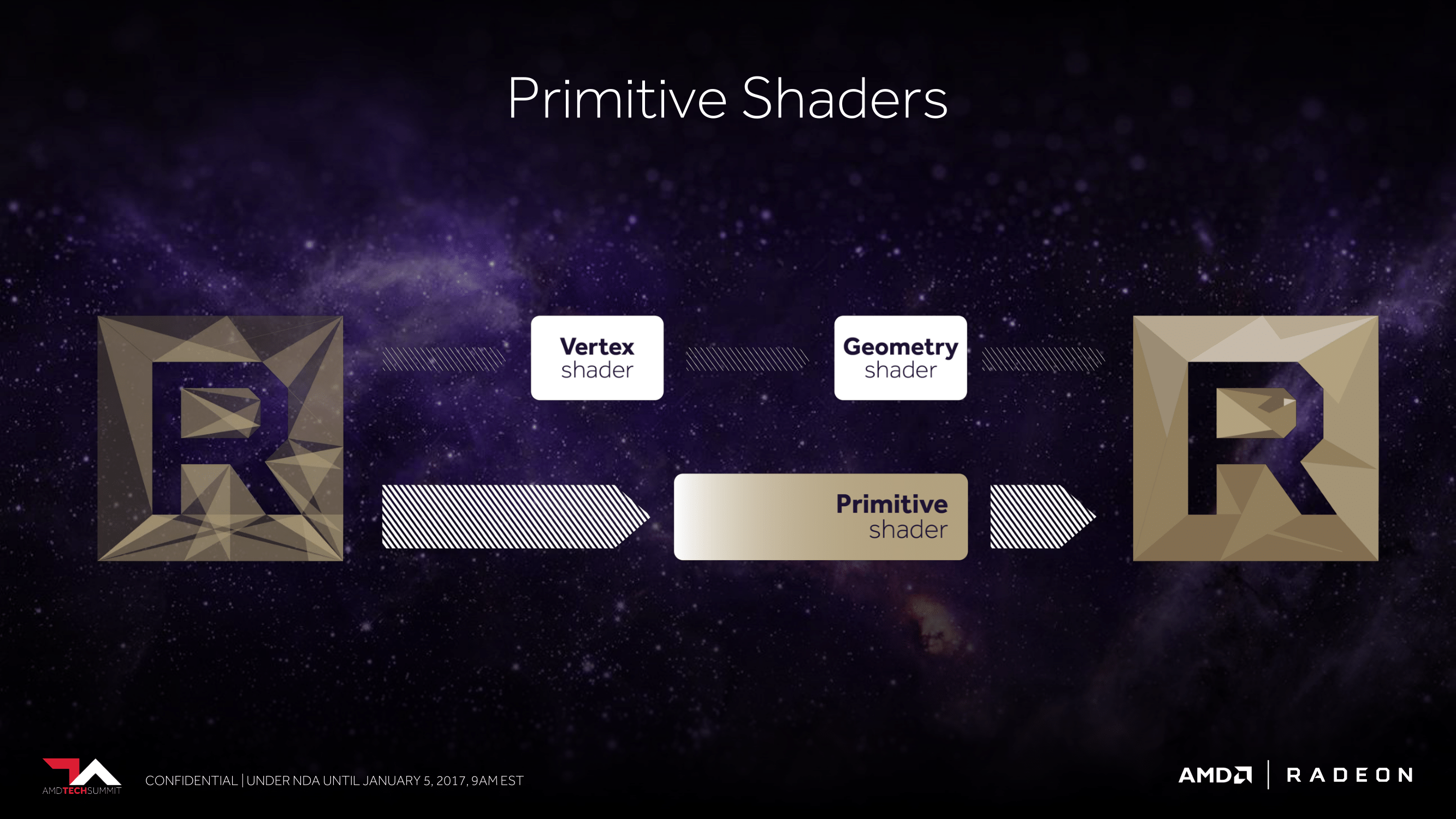
In any case, however AMD is doing it, the updated geometry engines will also feature one more advancement, which AMD is calling the primitive shader. A new shader stage that runs in place of the usual vertex and geometry shader path, the primitive shader allows for the high speed discarding of hidden/unnecessary primitives. Along with improving the total primitive rate, discarding primitives is the next best way to improve overall geometry performance, especially as game geometry gets increasingly fine, and very small, overdrawn triangles risk choking the GPU.
AMD isn’t offering any real detail here in how the primitive shader operates, and as a result I’m curious here whether this is something that AMD’s shader compiler can automatically add, or if it requires developers to specifically call it (like they would vertex and geometry shaders).








155 Comments
View All Comments
jjj - Thursday, January 5, 2017 - link
599$ for Titan X Pascal (or better) perf?nathanddrews - Thursday, January 5, 2017 - link
If they have TitanXP performance, it's going to be more expensive than the 1080. You know NVIDIA is just waiting for a chance to release a $699 or $799 1080Ti, so whatever AMD brings out, you can bet there's gonna be a clash of titans. Er, titans and stars, that is.jjj - Thursday, January 5, 2017 - link
599$ might be too aggressive but depends on where the die size lands and what Nvidia does.Vega has almost 15% more FLOPS than Titan XP so remains to be seen how well they utilize that computing power and how much silicon it takes.
The likely 8GB of HMB does help on the cost side.
It also depends on what other SKUs they got and when. A high price limits volumes but if they also have lesser SKUs at launch, they can afford to price the best SKU higher.
haukionkannel - Thursday, January 5, 2017 - link
True! Nvidia has guaranteed that fastest Vegas can be sold over 1000$...Lets hope that cheaper option are near 500-600$.
The interesting part is when AMD will use these next generation GPU units in their mid and low range products. Maybe the next summer or next autumn? Then we will get interesting devices to 150-350$ slots! Most propably with gdd5 in the low end and maybe gddr5+ in the high mid range GPUs,
jjj - Thursday, January 5, 2017 - link
Why not get a 350$ card at launch. They have nothing above Polaris 10 and the 350 price band is important.eachus - Saturday, January 14, 2017 - link
There is a new Polaris chip (Polaris 12) in the works. It may be intended only for APUs where it would be mounted on an interposer with a Ryzen chip. It is not clear what AMD is going to do in the gap between RX 480 and Vega 10. Vega 11 is expected to replace the RX 480** Understand what replace means here. It doesn't mean that AMD will stop selling Polaris GPUs. It means that AMD expects Vega 11 to have a better price/performance than RX 480, and that the performance gap between and that the price range where RX 480 currently sells will be starved of oxygen. I do expect a dual Polaris 10 card to ship, and there is also an RX 490 design floating around. (It may be a Polaris 10 chip with a higher clock speed, more power of course, and 8 Gig of GDDR5x memory.)
Always remember that marketing gets the last say, not engineering. So only one or none of these products may show up. It is also not clear when Vega 11 will arrive. If it is late in this year, or early in next year, there will be enough time to market the additional Polaris parts.
Jad77 - Thursday, January 5, 2017 - link
So, by the time this hits the streets, Nvidia will already have another hardware iteration out? It's likely too late, but if you still holding on, sell your AMD stock.Darkknight512 - Thursday, January 5, 2017 - link
Likely Nvidia will have an answer, that has always been the case and is barely even worth mentioning anymore, at least until AMD gets the upper hand one of these days. They did it to Intel during the Athlon days. It is very much possible, they have smart engineers, they just don't have enough of them but that often does not matter if they can work more efficiently. They have one thing going for them and that is a larger team by 2x often results in <2x the work done.One of my former bosses while I worked in the silicon industry said "AMD has good technology, they just have terrible luck being the underdog in both industries they compete in at the same time.". I wholely agree, with some luck they actually can come out on top, Nvidia is spending a lot of money diversifying.
MLSCrow - Thursday, January 5, 2017 - link
Honestly, I for once, don't think nVidia will have an answer. I feel that their expectations of what AMD could do were so incredibly low, that they felt GP100 and all of its derivatives would be enough to lay the smack down on AMD for good. Even with Volta, which seems like it's going to be a slight tweak to Pascal, it seems that Vega might just come out on top, which would make more sense out of AMD's slide of "Poor Volta", which would be a rather idiotic move unless AMD truly had something to be that cocky about.Yojimbo - Thursday, January 5, 2017 - link
NVIDIA isn't trying to lay the smackdown on AMD for good. NVIDIA has been evolving in a different direction from AMD. AMD, probably because they have been cash-strapped, has not been able to invest the money necessary to become a platform-based company the way NVIDIA has.Also, Volta will not be a small tweak to Pascal. Pascal was a die shrink and small tweak to Maxwell (from the point of view of the underlying architecture, not the features that it enables). Volta is supposed to have ~1.7 times the performance and efficiency of Pascal on the same process technology. It won't be out until 6 to 9 months after Vega, however. But I'm very leery about taking AMD's promises at face value. Even if Vega is as high performance and efficient as AMD claims, it still uses HBM2 which adds significant cost to the manufacture of the chip. That means they will only be able to put a limited amount of pricing pressure on NVIDIA.