OpenCAPI Unveiled: AMD, IBM, Google, Xilinx, Micron and Mellanox Join Forces in the Heterogenous Computing Era
by Johan De Gelas on October 14, 2016 8:00 AM EST- Posted in
- CPUs
- Enterprise

Some of you may remember AMD announcing the "Torrenza" technology 10 years ago. The idea was to offer a fast and coherent interface between the CPU and various types of "accelerators" (via Hyper Transport). It was one of the first initiatives to enable "heterogeneous computing".
We now have technology that could be labeled "heterogeneous computing", the most popular form being GPU computing. There have been also encryption, compression and network accelerators, but the advantages of those accelerators were never really clear, as shifting data back and forth to the CPU was in many cases less efficient than letting the CPU process it with optimized instructions. Heterogeneous computing was in the professional world mostly limited to HPC; in the consumer world a "nice to have".
But times are changing. The sensors of the Internet of Things, the semantic web and the good old www are creating a massive and exponentially growing flood of data that can not be stored and analyzed by traditional means. Machine learning offers a way of classifying all that data and finding patterns "automatically". As a result, we witnessed a "machine learning renaissance", with quite a few breakthroughs. Google had to deal with this years ago before most other companies, and released some of those AI breakthroughs of the Google Brain Team in the Open Source world, one example being "TensorFlow". And when Google releases important technology into the Open Source world, we know we got to pay attention. When Google released the Google File System and Big Table back in 2004 for example, a little bit later the big data revolution with Hadoop, HDFS and NoSQL databases erupted.

Big Data thus needs big brains: we need more processing power than ever. As Moore's law is dead (the end of CMOS scaling), we can not expect much from process technology advancements. The processing power has to come from ASICs (see Google's TPU), FPGAs (see Microsoft's project Catapult) and GPUs.
Those accelerators need a new "Torrenza technology", a fast, coherent interconnect to the CPU. NVIDIA was first with NVLink, but an open standard would be even better. IBM on the other hand was willing to share the CAPI interface.
To that end, Google, AMD, Xilinx, Micron and Mellanox have joined forces with IBM to create a "coherent high performance bus interface" based on a new bus standard called "Open Coherent Accelerator Processor Interface" (OpenCAPI). Capable of a 25Gbits per second per lane data rate, OpenCAPI outperforms the current PCIe specification, which offers a maximum data transfer rate of 8Gbits per second for a PCIe 3.0 lane. We assume that the total bandwidth will be a lot higher for quite a few OpenCAPI devices, as OpenCAPI lanes will be bundled together.
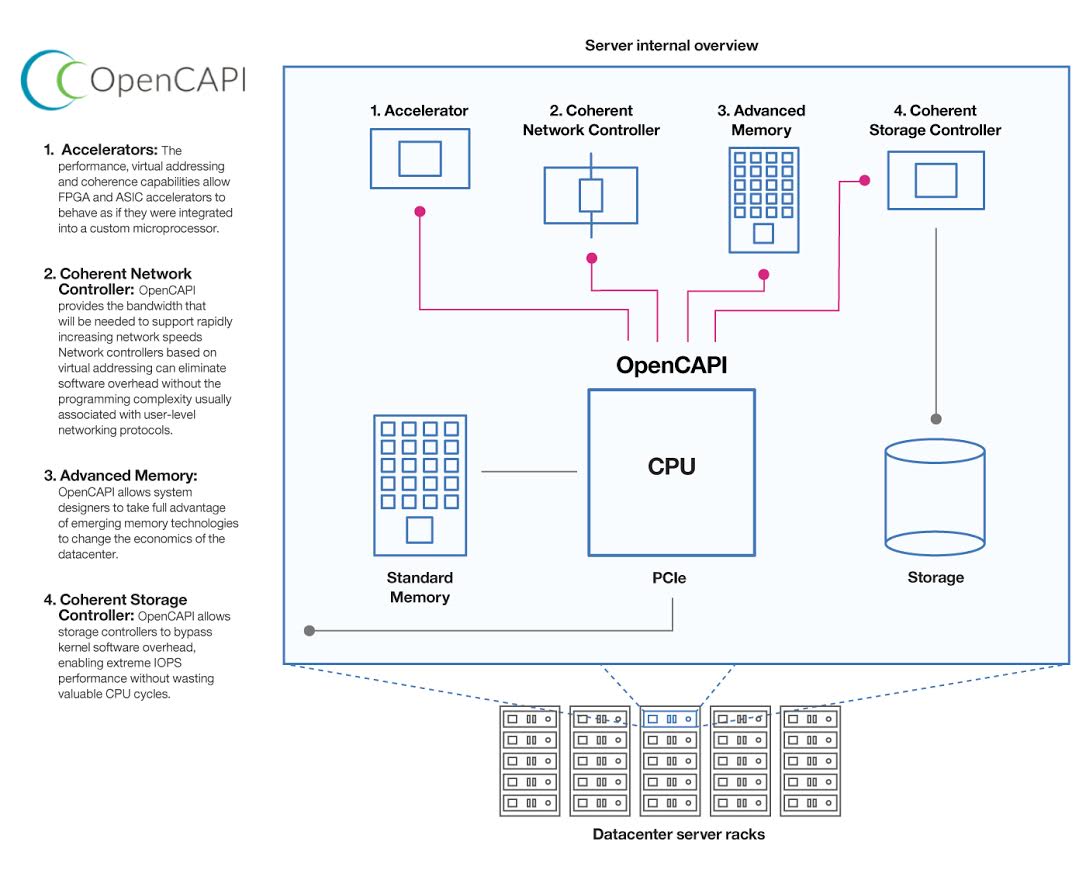
It is a win, win for everybody besides Intel. It is clear now that IBM's OpenPOWER initiative is gaining a lot of traction and that IBM is deadly serious about offering an alternative to the Intel dominated datacenter. IBM will implement the OpenCAPI interface in the POWER9 servers in 2017. Those POWER9s will not only have a very fast interface to NVIDIA GPUs (via NVLink), but also to Google's ASICs and Xilinx FPGAs accelerators.

Meanwhile this benefits AMD as they get access to an NVLink alternative to link up the Radeon GPU power to the upcoming Zen based server processors. Micron can link faster (and more profitable than DRAM) memory to the CPU. Mellanox can do the same for networking. OpenCAPI is even more important for the Xilinx FPGAs as a coherent interface can make FPGAs attractive for a much wider range of applications than today.
And guess what, Dell/EMC has joined this new alliance just a few days ago. Intel has to come up with an answer...
Update: courtesy of commenter Yojimbo: "NVIDIA is a member of the OpenCAPI consortium, at the "contributor level", which is the same level Xilinx has. The same is true for HPE (HP Enterprise)".
This is even bigger than we thought. Probably the biggest announcement in the server market this year.






Source: OpenCAPI








49 Comments
View All Comments
emn13 - Friday, October 14, 2016 - link
They might benefit from lower latency, however, to be able to shuffle even smaller tasks to the gpu (or conversely, to let traditionally gpu-only tasks benefit from short bursts of branchy logic on the cpu).Multi GPU might also be easier.
alvaroafernandez@yahoo.com - Friday, October 14, 2016 - link
I don't see why not? It would certainly be used by AMD consumer hardware. That includes laptops, desktops, and gaming consoles.fallaha56 - Sunday, October 16, 2016 - link
er no seems highly relevant for games with advanced AI, physics and async compute models for games now incoming -plus multicore finally being a realityyou just made a Bill Gates '640kb should be enough for anybody' comment
JohanAnandtech - Friday, October 14, 2016 - link
I would appreciate it that you ask your questions a bit more civil. You call it "bullshit" while big data and machine learning are one of the most important battlegrounds that will decide who will get marketshare in the server market.lefty2 - Friday, October 14, 2016 - link
I appologise.The article indicates that it's a faster replacement to PCIe and NVlink, but now I read comments from SarahKerrigan that does not seem to be true.
Michael Bay - Saturday, October 15, 2016 - link
>muh big data>muh machine learning
Ah, the newfangled ways for IT managers to justify ridiculous spending for no useful outcome.
Nobody other than already present will "get marketshare in the server market" anyway, which is to say intel will keep dominating it. Notice their abscence from the list.
JohanAnandtech - Saturday, October 15, 2016 - link
Your comment sounds a lot like the one I heard from older ITers back in the mid nineties. Who needs Internet, we got very solid high end machines and internal networks here that take care of our IT. Every decent bank is already using big data technology & machine learning to know the customer they have in front of them.Michael Bay - Saturday, October 15, 2016 - link
...and here`s the typical IT manager nonanswer.Thank you!
fallaha56 - Sunday, October 16, 2016 - link
@johan absolutely ;)'640k should be enough for anybody'
Kevin G - Friday, October 14, 2016 - link
It isn't about just bandwidth but coherency and latency. That is what can enable seamless heterogeneous compute. OpenCAPI provides both.