AMD 7th Gen Bristol Ridge and AM4 Analysis: Up to A12-9800, B350/A320 Chipset, OEMs first, PIBs Later
by Ian Cutress on September 23, 2016 9:00 AM ESTThe Two Main Chipsets: B350 and A320
Despite all the crazy potential that might come from playing with PCIe, if a user wants more than a couple of SATA ports or x1 slots, the chipset is there to provide. For the Bristol Ridge OEM launch, there are two main chipsets with a further three aimed more at embedded platforms. We’ll focus more on the first two.

It’s worth noting that AMD has specifically listed that the B350 chipset is not the premium chipset for AM4. We know that Zen will be a part of the AM4 socket and ecosystem, and it would seem that there is at least one specific chipset for the high-end desktop market set to come later. Feel free to speculate.
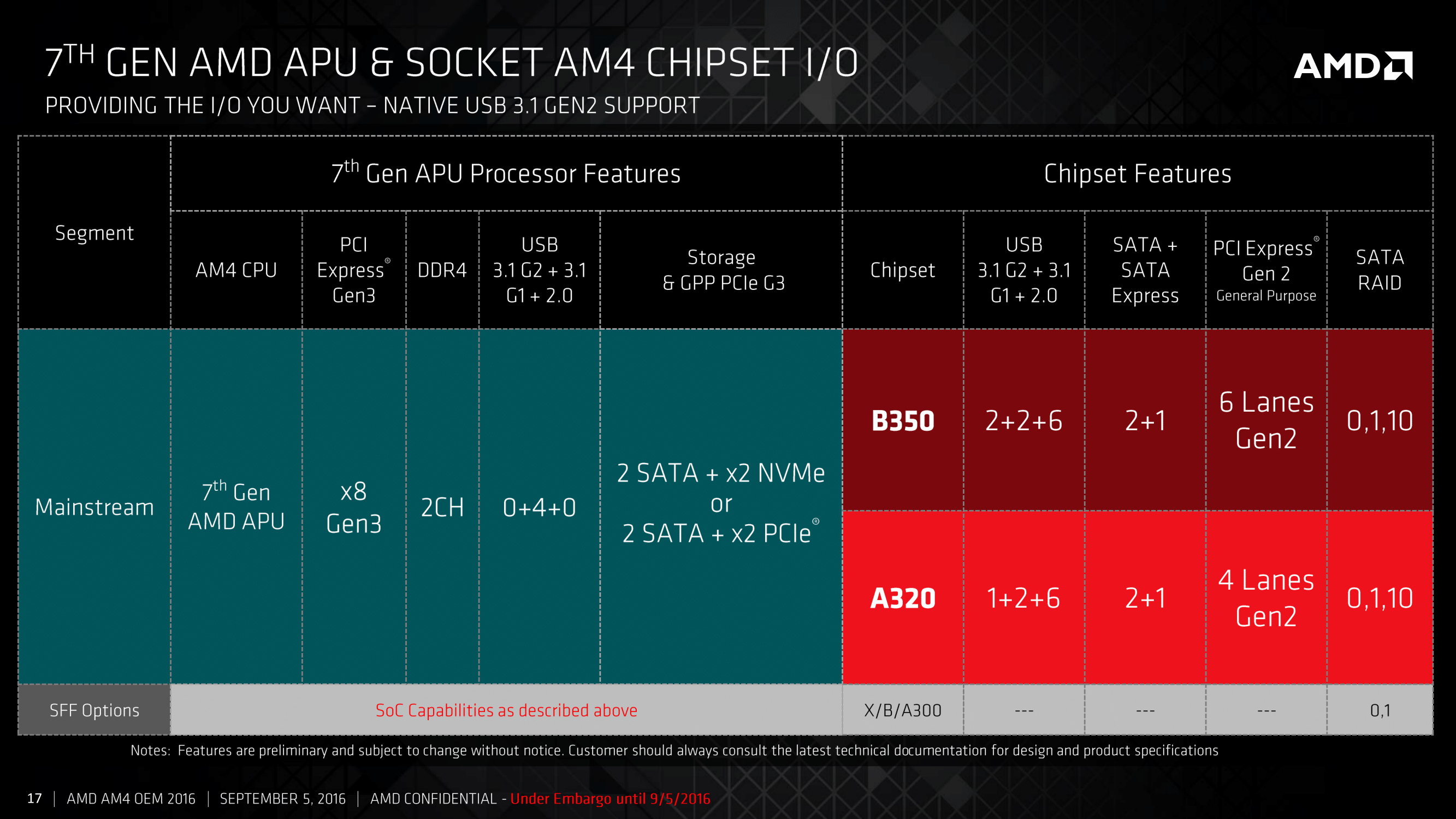
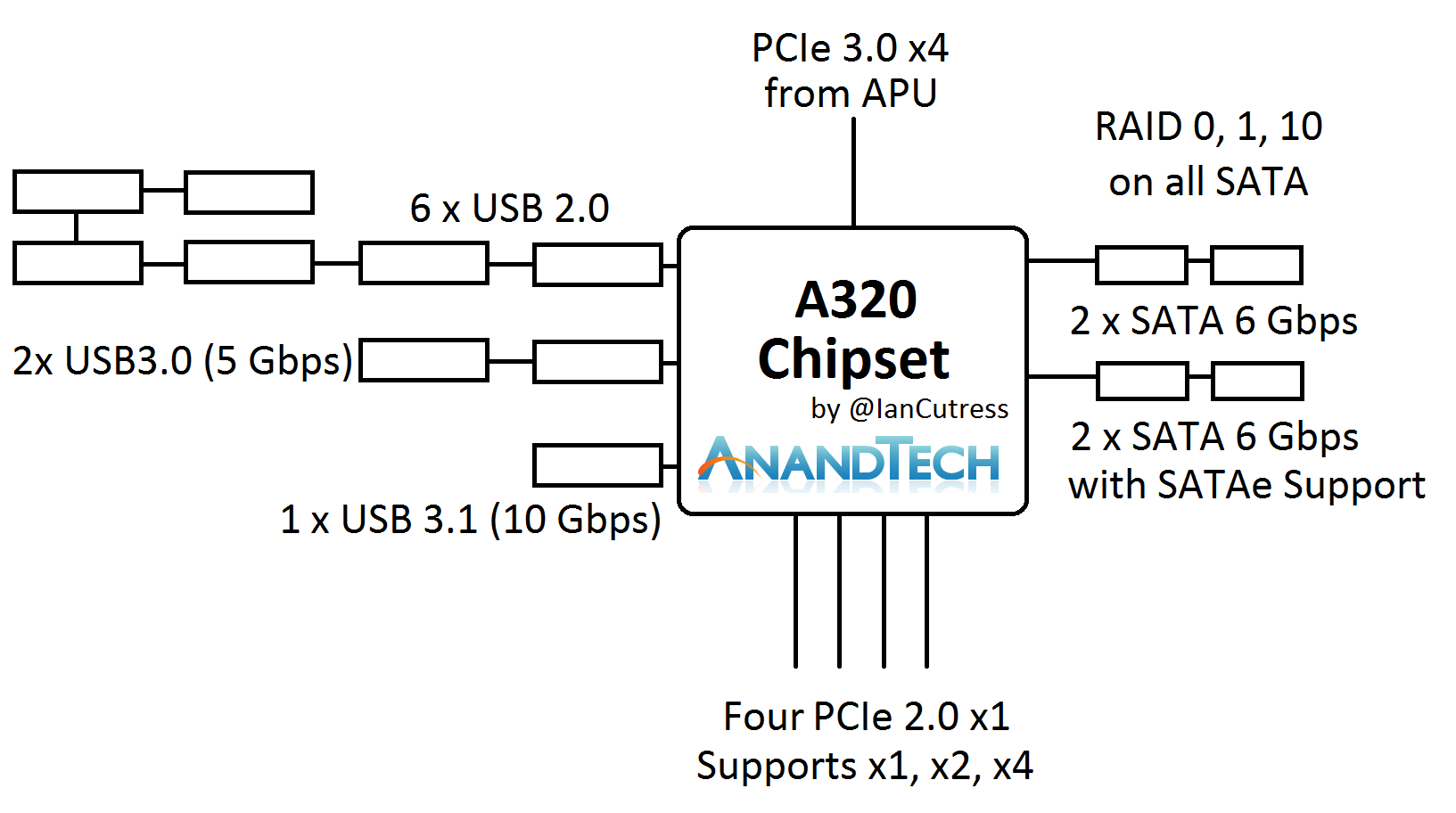
The B350 and A320 chipsets are mostly identical, using the PCIe 3.0 x4 from the CPU and offering a variety of SATA, USB and PCIe 2.0 connectivity. The PCIe 2.0 lanes, six on the B350 chipset and four on the A320 chipset, support x1, x2 and x4 modes for an array of different controllers. Perhaps the interesting thing here is the support of USB 3.1 at 10 Gbps, which is provided as native support from the chipset.
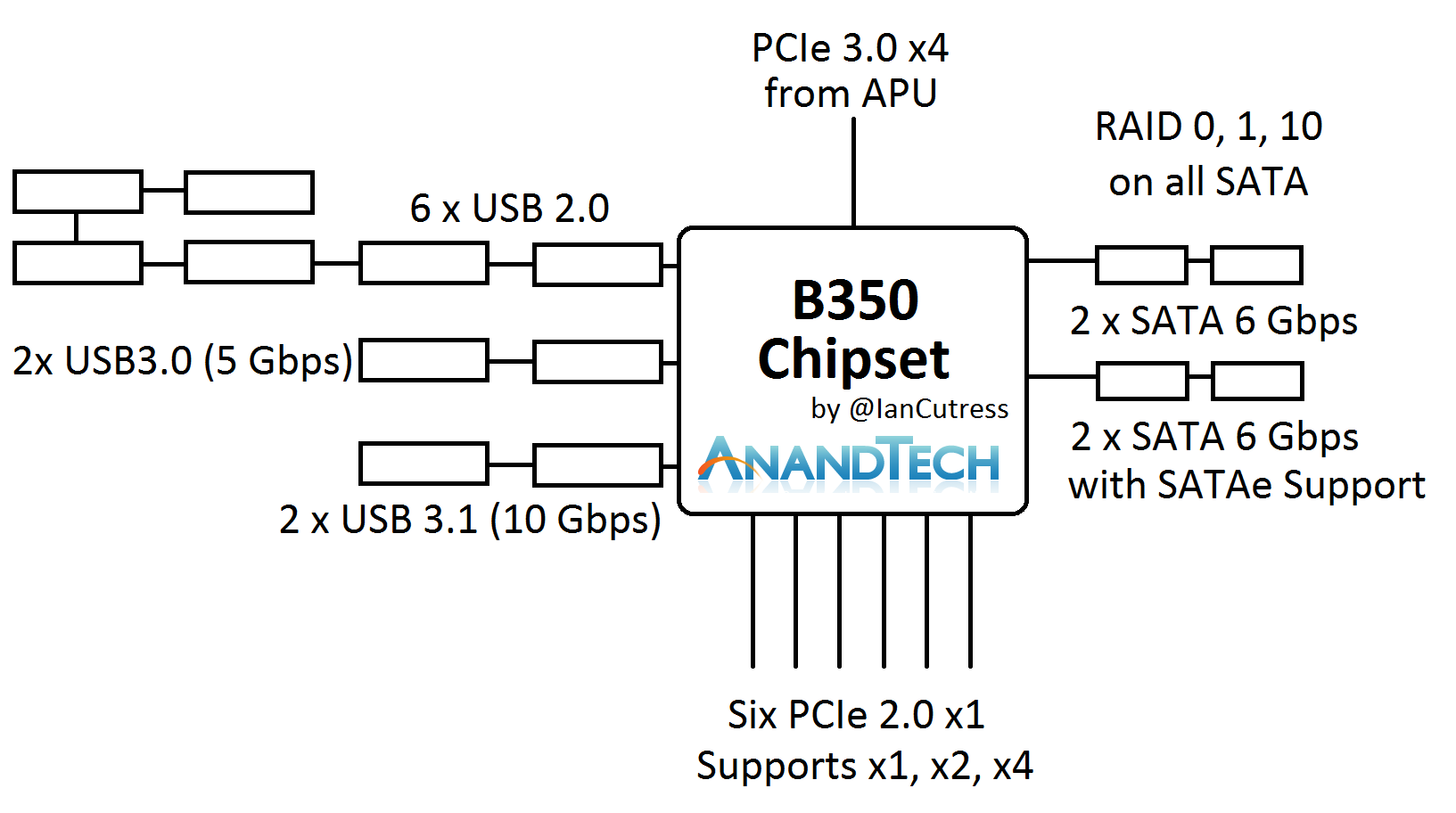
The main provider of USB 3.1 controllers in the market currently, ASMedia, has been floated around as a partner with AMD in designing these chipsets. We asked AMD if ASMedia was involved, and to what extent, in the development or IP of the hardware. We were told that while the IP is with AMD, ASMedia were bought on as a partner in some fashion (most likely as a design firm or a consultant) to help produce the hardware. We were informed that the chipsets are manufactured at TSMC using a 55nm process, which is a much cheaper process than 28nm or 16nm.
An additional aside, the chipset USB 3.1 ports do not support reversible Type-C natively. We have been informed that a re-driver chip is required to support the revisable connectivity, which is a minor additional IC required by the OEMs.
Aside from the native USB 3.1 output, AMD’s chipset offerings are far behind Intel’s current implementation, affording up to 20 PCIe 3.0 lanes from their chipset despite the same uplink equivalent. This is partly because Intel’s chipset has steadily grown and looks more like a PCIe switch itself. AMD is claiming that the external B350 chipset, compared to the older AM3 platforms, comes down from 19.6W TDP to 5.8W TDP.









122 Comments
View All Comments
Alexvrb - Sunday, September 25, 2016 - link
Geekbench is trash at comparing across different architectures. It makes steaming piles look good. Only using SSE (first gen, ancient) on x86 processors would certainly be a part of the puzzle regarding Geekbench results. Thanks, Patrick.Not to take anything away from Apple's cores. I wouldn't be surprised that they have better performance per WATT than Skylake. Perf/watt is kind of a big deal for mobile, and Apple (though I don't care for them as a company) builds very efficient processor cores. With A10 using a big.LITTLE implementation of some variety, they stand to gain even more efficiency. But in terms of raw performance? Never rely on Geekbench unless maybe you're comparing an A9 Apple chip to an A10 or something. MAYBE.
ddriver - Monday, September 26, 2016 - link
Hey, it is not me who uses crap like geekbench and sunspider to measure performnace, it is sites like AT ;)BurntMyBacon - Monday, September 26, 2016 - link
@ddriver: "Hey, it is not me who uses crap like geekbench and sunspider to measure performnace, it is sites like AT ;)"LOL. My gut reaction was to call you out on blame shifting until I realized ... You are correct. There hasn't exactly been a lot of benchmark comparison between ARM and x86. Of course, there isn't much out there with which to compare either so ...
patrickjp93 - Monday, September 26, 2016 - link
Linpack and SAP. Both are massive benchmark suites that will give you the honest to God truth, and the truth is ARM is still 10 years behind.patrickjp93 - Monday, September 26, 2016 - link
They use it in context and admit the benchmarks are not equally optimized across architectures.patrickjp93 - Monday, September 26, 2016 - link
It doesn't even use SSE. It uses x86_64 and x87 scalar float instructions. It doesn't even give you MMX or SSE. That's how biased it is.patrickjp93 - Monday, September 26, 2016 - link
Just because you write code simply enough using good modern form and properly align your data and make functions and loops small enough to be easily optimized does not mean GCC doesn't choke. Mike Acton gave a great lecture at CPPCon 2014 showing various examples where GCC, Clang, and MVCC choke.Define very good.
Define detailed analysis. Under what workloads? Is it more efficient for throughput or latency (because I guarantee it can't be both)?
Yes, Geekbench uses purely scalar code on x86 platforms. It's ludicrously pathetic.
It's 8x over scalar, and that's where it matters, and it can even be better than that because of loop Muop decreases which allow the loops to fit into the detector buffers which can erase the prefetch and WB stages until the end of the loop.
No, they're not more powerful. A Pentium IV is still more powerful than the Helio X35 or Exynos 8890.
No, those are select benchmarks that are more network bound than CPU bound and are meaningless for the claims people are trying to make based on them.
BurntMyBacon - Monday, September 26, 2016 - link
@ddriver: "I've been using GCC mostly, and in most of the cases after doing explicit vectorization I found no perf benefits, analyzing assembly afterwards revealed that the compiled has done a very good job at vectorizing wherever possible."It's not just about vectorizing. I haven't taken a look at Geekbench code, but it is pretty easy to under-utilize processor resources. Designing workloads to fit within a processors cache for repetitive operations is a common way to optimize. It does, however, leave a processor with a larger cache underutilized for the purposes of the workload. Similar examples can be found for wide vs narrow architectures and memory architectures feeding the processor. Even practical workloads can be done various ways that are much more or less suitable to a given platform. Compression / Encoding methods are some examples here.
BurntMyBacon - Monday, September 26, 2016 - link
@patrickjp93: "Yes you can get 5x the performance by optimizing. Geekbench only handles 1 datem at a time on Intel hardware vs. the 8 you can do with AVX and AVX2. Assuming you don't choke on bandwidth, you can get an 8x speedup."If you have processor with a large enough cache to keep a workload almost entirely in cache and another with far less cache that has to access main memory repetitively to do the job, the difference can be an order of magnitude or more. Admittedly, the type of workload that is small enough to fit in any processor cache isn't common, but I've seen cases of it in benchmarks and (less commonly in) scientific applications.
patrickjp93 - Tuesday, September 27, 2016 - link
Heh, they're usually based on Monte Carlo simulations if they can.