AMD Zen Microarchiture Part 2: Extracting Instruction-Level Parallelism
by Ian Cutress on August 23, 2016 8:45 PM EST- Posted in
- CPUs
- AMD
- x86
- Zen
- Microarchitecture
Fetch
For Zen, AMD has implemented a decoupled branch predictor. This allows support to speculate on incoming instruction pointers to fill a queue, as well as look for direct and indirect targets. The branch target buffer (BTB) for Zen is described as ‘large’ but with no numbers as of yet, however there is an L1/L2 hierarchical arrangement for the BTB. For comparison, Bulldozer afforded a 512-entry, 4-way L1 BTB with a single cycle latency, and a 5120 entry, 5-way L2 BTB with additional latency; AMD doesn’t state that Zen is larger, just that it is large and supports dual branches. The 32 entry return stack for indirect targets is also devoid of entry numbers at this point as well.
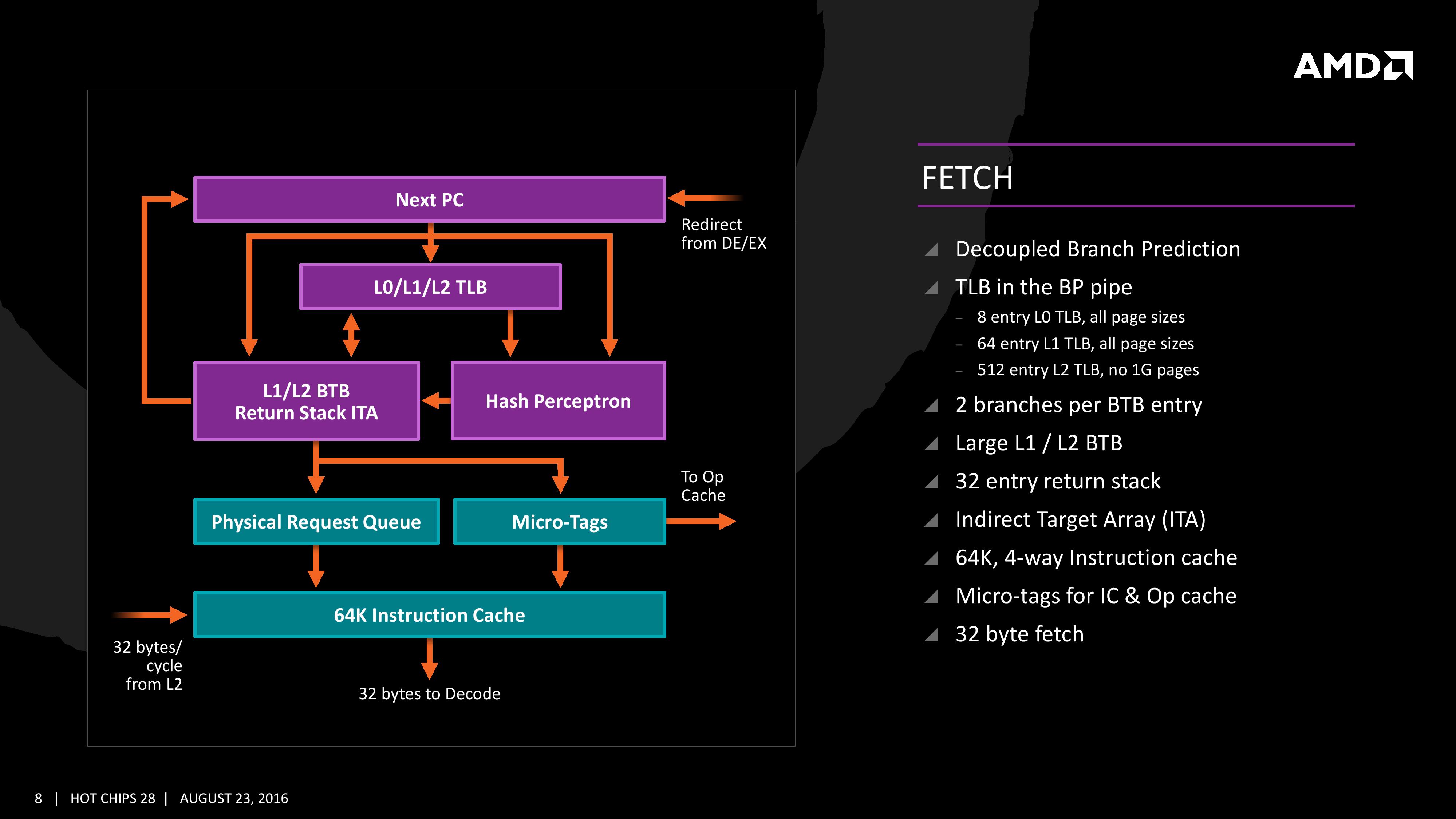
The decoupled branch predictor also allows it to run ahead of instruction fetches and fill the queues based on the internal algorithms. Going too far into a specific branch that fails will obviously incur a power penalty, but successes will help with latency and memory parallelism.
The Translation Lookaside Buffer (TLB) in the branch prediction looks for recent virtual memory translations of physical addresses to reduce load latency, and operates in three levels: L0 with 8 entries of any page size, L1 with 64 entries of any page size, and L2 with 512 entries and support for 4K and 256K pages only. The L2 won’t support 1G pages as the L1 can already support 64 of them, and implementing 1G support at the L2 level is a more complex addition (there may also be power/die area benefits).
When the instruction comes through as a recently used one, it acquires a micro-tag and is set via the op-cache, otherwise it is placed into the instruction cache for decode. The L1-Instruction Cache can also accept 32 Bytes/cycle from the L2 cache as other instructions are placed through the load/store unit for another cycle around for execution.
Decode
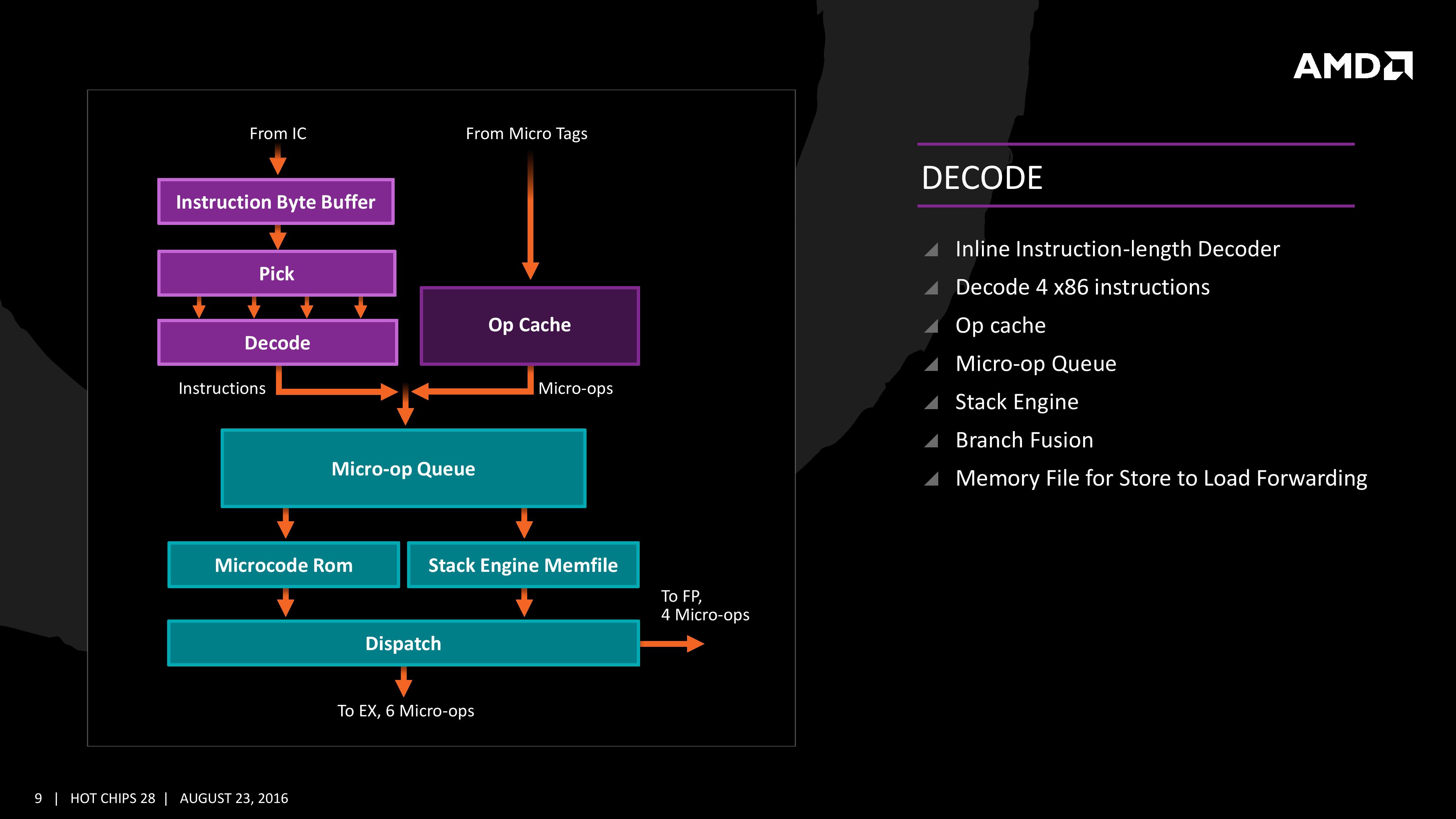
The instruction cache will then send the data through the decoder, which can decode four instructions per cycle. As mentioned previously, the decoder can fuse operations together in a fast-path, such that a single micro-op will go through to the micro-op queue but still represent two instructions, but these will be split when hitting the schedulers. The purpose of this allows the system to fit more into the micro-op queue and afford a higher throughput when possible.
The new Stack Engine comes into play between the queue and the dispatch, allowing for a low-power address generation when it is already known from previous cycles. This allows the system to save power from going through the AGU and cycling back around to the caches.
Finally, the dispatch can apply six instructions per cycle, at a maximum rate of 6/cycle to the INT scheduler or 4/cycle to the FP scheduler. We confirmed with AMD that the dispatch unit can simultaneously dispatch to both INT and FP inside the same cycle, which can maximize throughput (the alternative would be to alternate each cycle, which reduces efficiency). We are told that the operations used in Zen for the uOp cache are ‘pretty dense’, and equivalent to x86 operations in most cases.








106 Comments
View All Comments
bcronce - Tuesday, August 23, 2016 - link
Exclusive L3 cache makes better use of space, but requires snooping other core's L2 caches for data. If the L3 cache has all of the data all of the L2 cache has, then you only need to check one place.This is important when you're trying to synchronize threads since locks are shared memory locations that each core is attempting to read and update. Common types of thread safe data-structures can take some pretty big performance scaling hits. Of course you can work around this in your data-structure.
One research paper that I read showed exclusive caches having twice the latency of inclusive when snooping was required. If your data-structure has a scaling that works well up to 16 cores on Intel's inclusive cache, it may cap out around 8 cores on AMD's exclusive, thanks to Amdahl's law.
Cache snooping gets slower as more cores are added. Gotta check them all.
deltaFx2 - Tuesday, August 23, 2016 - link
@bconce: Except that Intel doesn't do strictly inclusive caches either. Intel's caches are neither-inclusive-nor-exclusive (afaik), in which data is inserted into both L2 and L3, but evicted independently. So you have to check L2 and L3 independently, same as the exclusive cache. Strictly-inclusive caches have many bad properties, a few that come to mind immediately (1) False evictions of lines: If a block constantly hits in L2, the LRU in L3 is not updated. If the block then becomes the oldest in L3 and is evicted, it must be evicted in L2 as well, resulting in a miss all the way to memory (2) Associativity of the L3 cache must be at least the sum of the associativity of the L2 caches hanging off it, otherwise it will constrain the associativity of the L2 caches. Hence neither-inclusive-nor-exclusive, or strictly exclusive.Exclusive caches are harder to build, true, because you have to manage exclusivity. That doesn't explain Ian's comment about them being less efficient.
68k - Wednesday, August 24, 2016 - link
The Intel manual state that"The shared L3 cache is writeback and inclusive, such that a cache line that exists in either L1 data cache, L1 instruction cache, unified L2 cache also exists in L3."
That is, the L3-cache is strictly inclusive with anything stored in the core local L2/L1-caches. So it is enough to check L3 to see whether the cache-line is in use by any other core sharing the L3.
bcronce - Wednesday, August 24, 2016 - link
@68kThanks for looking it up. I only remembered Intel talking talking about this years ago when they made the design decision in order to minimize latency. Certain operations are extremely latency sensitive, like thread synchronizations.
The strange thing is AMD is pushing for so many cores, but then chooses a cache design that makes sharing data more expensive. What they did gain is exclusive caches tend to have more bandwidth and are great for independent threads with little sharing. It's a trade off. Nothing is free, pros and cons everywhere.
deltaFx2 - Wednesday, August 24, 2016 - link
@68k,@bcronce: I guess I haven't looked up Intel's latest and greatest cache organization :) I do recall though that Neither-incl-nor-exclusive was their scheme for quite a while, probably until Sandy Bridge. Perhaps that explains why their L2 cache went from 8-way to 4-way in SkyLake; the extra associativity cannot be effectively utilized with strict inclusion as you keep adding more cores (a single set in L3 maps to a unique set in L2. If you have 16 way L3, only 16 lines that map to that set in L3 can reside in the L2s. Obviously, multiple L3 sets map to the same L2 set, so this is somewhat mitigated, but it is a glass-jaw).The nice thing about Intel's organization is that it's a monolithic L3 with variable latency to slices, as opposed to AMD's distributed L3. That probably is what adds the latency (if it does) on cache-to-cache transfers, not the inclusive-vs-exclusive, or the inclusive cache acting as a probe filter. You could just as easily add a separate probe filter to avoid unnecessary coherence lookups. Would you point me to that paper you quoted earlier? I have a hard time believing that the problem is the exclusive cache itself, and not the organization of the cache. Anyway, I don't know enough about AMD's design to comment, so I'll leave it at that. Thanks!
intangir - Wednesday, August 24, 2016 - link
As far as I know, since Nehalem Intel's L3 caches have been fully inclusive of L1+L2, but the L1 and L2 caches are neither inclusive nor exclusive with respect to each other.Ryan Smith - Tuesday, August 23, 2016 - link
Right you are. That's a typo on our end, and in the deep dive section on cache you can see why it's exclusive. As for the first page, I've corrected the typo.looncraz - Wednesday, August 24, 2016 - link
Zen's L3 is "mostly exclusive." This changes things up a bit - it isn't a pure victim cache and will probably contain data used between multiple cores. The first access will be slower as the data is snooped from another core's L2, but then that data will be mirrored in the L3. The coherent data fabric which links multiple core complexes adds a whole new level of complexity for sharing data between cores, but I suspect a mechanism exists to synchronize global data between the L3 caches, so global data will have a copy in each L3 and actions on global data will incur a latency penalty, but nothing compared to snooping L2s across multiple core complexes.NikosD - Wednesday, August 24, 2016 - link
It seems that AMD did its job right this time.Most of the CPU features are in between Broadwell and Skylake architectures and this is extremely important and fast, with the exception of AVX/AVX2 instructions that are executed in 128bit chunks instead of 256bit.
Of course we have to wait and see latencies and throughput of the rest of arithmetic instructions, but all these are just details.
I think with Zen we will all owe a lot to AMD like the older days of 64bit CPUs and OS.
This time the revolution will be the affordable true 8 core/ 16 thread CPU with no GPU inside for the first time in desktop.
The key point here is price, in order to be affordable. Not like High-End Desktop systems of Intel.
That move will force Intel to accept the fact that we, as customers, want 8 cores in our CPUs like 64bit CPUs and OS back in the past that Intel offered only with Itanium.
All in all, AMD could possibly hold in its hands a true winner, from laptops to servers that brings us memories of AMD Athlon and Opteron CPUs.
Well done AMD!
Michael Bay - Wednesday, August 24, 2016 - link
Do we, though? General purpose software like word processors and such is literally indistinguishable on 2 and 4 cores, and a lot of things on content creation side are already accelerated by GPU.There are games of course, but CPU stopped being a bottleneck there long time ago.