AMD Zen Microarchiture Part 2: Extracting Instruction-Level Parallelism
by Ian Cutress on August 23, 2016 8:45 PM EST- Posted in
- CPUs
- AMD
- x86
- Zen
- Microarchitecture
Simultaneous MultiThreading (SMT)
Zen will be AMD’s first foray into a true simultaneous multithreading structure, and certain parts of the core will act differently depending on their implementation. There are many ways to manage threads, particularly to avoid stalls where one thread is blocking another that ends in the system hanging or crashing. The drivers that communicate with the OS also have to make sure they can distinguish between threads running on new cores or when a core is already occupied – to achieve maximum throughput then four threads should be across two cores, but for efficiency where speed isn’t a factor, perhaps power gating/clock gating half the cores in a CCX is a good idea.
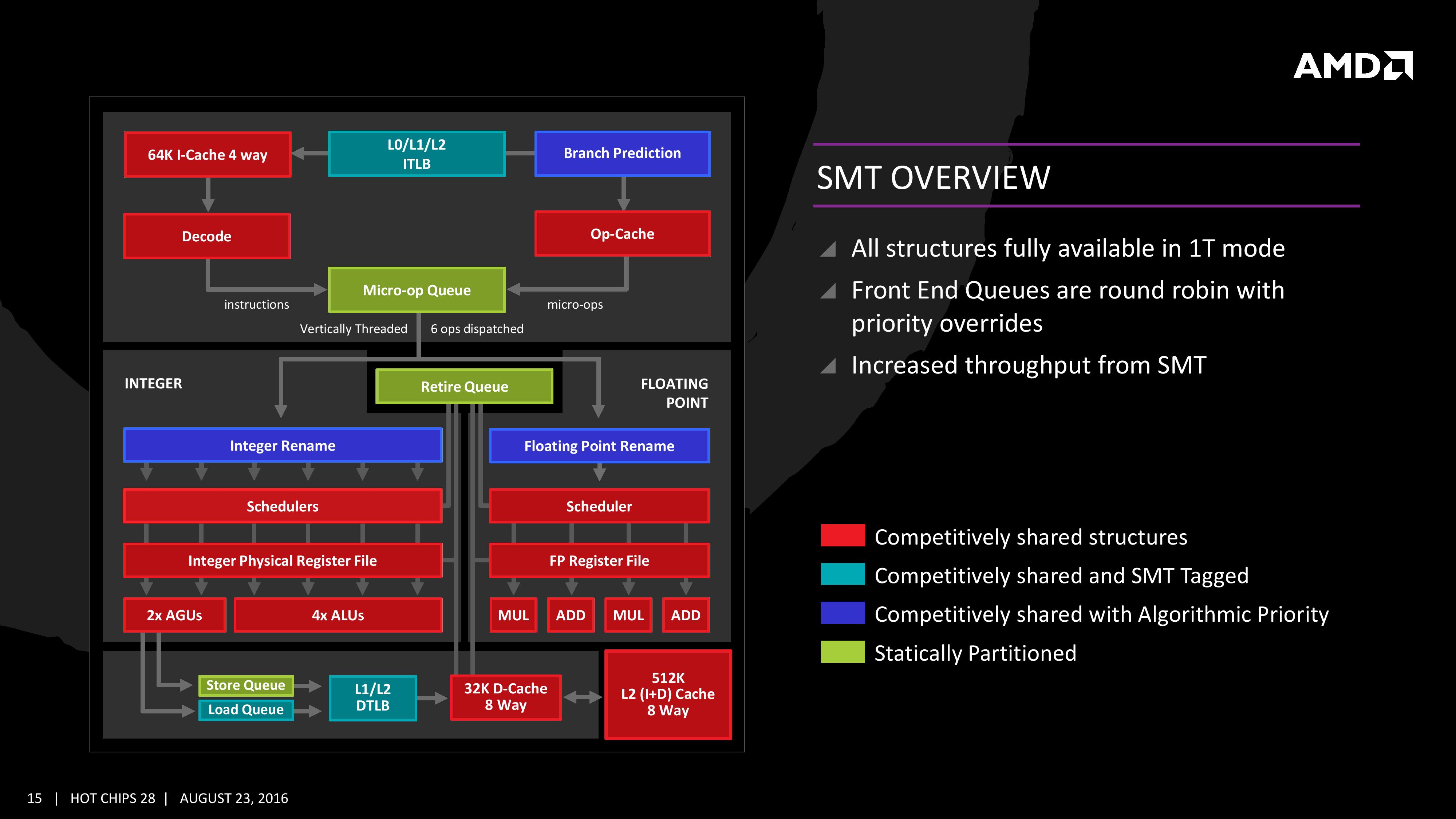
There are a number of ways that AMD will deal with thread management. The basic way is time slicing, and giving each thread an equal share of the pie. This is not always the best policy, especially when you have one performance dominant thread, or one thread that creates a lot of stalls, or a thread where latency is vital. In some methodologies the importance of a thread can be tagged or determined, and this is what we get here, though for some of the structures in the core it has to revert to a basic model.
With each thread, AMD performs internal analysis on the data stream for each to see which thread has algorithmic priority. This means that certain threads will require more resources, or that a branch miss needs to be prioritized to avoid long stall delays. The elements in blue (Branch Prediction, INT/FP Rename) operate on this methodology.
A thread can also be tagged with higher priority. This is important for latency sensitive operations, such as a touch-screen input or immediate user input elements required. The Translation Lookaside Buffers work in this way, to prioritize looking for recent virtual memory address translations. The Load Queue is similarly enabled this way, as typically low latency workloads require data as soon as possible, so the load queue is perfect for this.
Certain parts of the core are statically partitioned, giving each thread an equal timing. This is implemented mostly for anything that is typically processed in-order, such as anything coming out of the micro-op queue, the retire queue and the store queue.
The rest of the core is competitive, meaning that if a thread demands more resources it will try to get there first if there is space to do so each cycle.
New Instructions
AMD has a couple of tricks up its sleeve for Zen. Along with including the standard ISA, there are a few new custom instructions that are AMD only.

Some of the new commands are linked with ones that Intel already uses, such as RDSEED for random number generation, or SHA1/SHA256 for cryptography. The two new instructions are CLZERO and PTE Coalescing.
The first, CLZERO, is aimed to clear a cache line and is more aimed at the data center and HPC crowds. This allows a thread to clear a poisoned cache line atomically (in one cycle) in preparation for zero data structures. It also allows a level of repeatability when the cache line is filled with expected data. CLZERO support will be determined by a CPUID bit.
PTE (Page Table Entry) Coalescing is the ability to combine small 4K page tables into 32K page tables, and is a software transparent implementation. This is useful for reducing the number of entries in the TLBs and the queues, but requires certain criteria of the data to be used within the branch predictor to be met.








106 Comments
View All Comments
tipoo - Wednesday, August 31, 2016 - link
Meanwhile Intel worked on shortening pipelines...Curious to see how this will go, hope for AMDs sake it's competitive.masouth - Friday, September 2, 2016 - link
I hope it works out for AMD as well but reading about long pipelines and higher freqs always reminds me of the P4 days/shudder
junky77 - Wednesday, August 24, 2016 - link
The problem is now having Intel/AMD provide fast enough CPUs to feed the new GPUs that don't seem to slow down..gamerk2 - Wednesday, August 24, 2016 - link
Pretty much anything from an i7 920 onward can keep GPUs fed these days. For gaming purposes, CPUs haven't been the bottleneck for over a decade. That's why you don't see significant improvement from generation to generation, since our favorite CPU tests happen to be with GPU sensitive benchmarks.Death666Angel - Thursday, August 25, 2016 - link
The story is much more complicated than you are making it seem:https://www.youtube.com/watch?v=frNjT5R5XI4
tipoo - Wednesday, August 31, 2016 - link
A Skylake i3 presents better frametimes than old i7s like the 920 or 2500Krhysiam - Wednesday, August 24, 2016 - link
40% over Excavator probably still puts it well behind even Haswell on IPC. If I'm looking at it right, Bench on this site has 4 single threaded tests (3 Cinebench versions and 3D Particle...). I crunched some numbers and found that if you add 40% to Excavator @ 4Ghz (X4 860 turbo), it still loses to Skylake @ 3.9Ghz (turbo) by between 32% & 39% across the four benchmarks. Haswell @ 3.9Ghz (turbo) would still be faster by 24% to 33%.If it really is 40% minimum, AND they can sustain decent clock speeds, then that's at least enough to be in the ballpark, but it's still well short of Intel in those few benchmarks at least. TBH I don't know how representative those benchmarks are of overall single-threaded performance.
It could well be a case of AMD offering significantly poorer lightly threaded performance, but a genuine 8 core CPU at an affordable (i.e. not $1000) price.
gamerk2 - Wednesday, August 24, 2016 - link
I except the following:~40% average IPC gain in FP workloads
~30% average IPC gain in INT workloads
~20% clock speed reduction.
Average performance increase: ~15-20%, or Ivy Bridge i7 level performance.
Michael Bay - Wednesday, August 24, 2016 - link
Well, nothing stops them from their own brand of tick-tock, especially considering largely stagnant intel IPC.looncraz - Wednesday, August 24, 2016 - link
40% over Excavator is almost exactly Haswell overall, particularly once you shape the performance to match what is known about Zen.http://excavator.looncraz.net/