AMD Zen Microarchitecture: Dual Schedulers, Micro-Op Cache and Memory Hierarchy Revealed
by Ian Cutress on August 18, 2016 9:00 AM EST
In their own side event this week, AMD invited select members of the press and analysts to come and discuss the next layer of Zen details. In this piece, we’re discussing the microarchitecture announcements that were made, as well as a look to see how this compares to previous generations of AMD core designs.
AMD Zen
Prediction, Decode, Queues and Execution
First up, let’s dive right into the block diagram as shown:
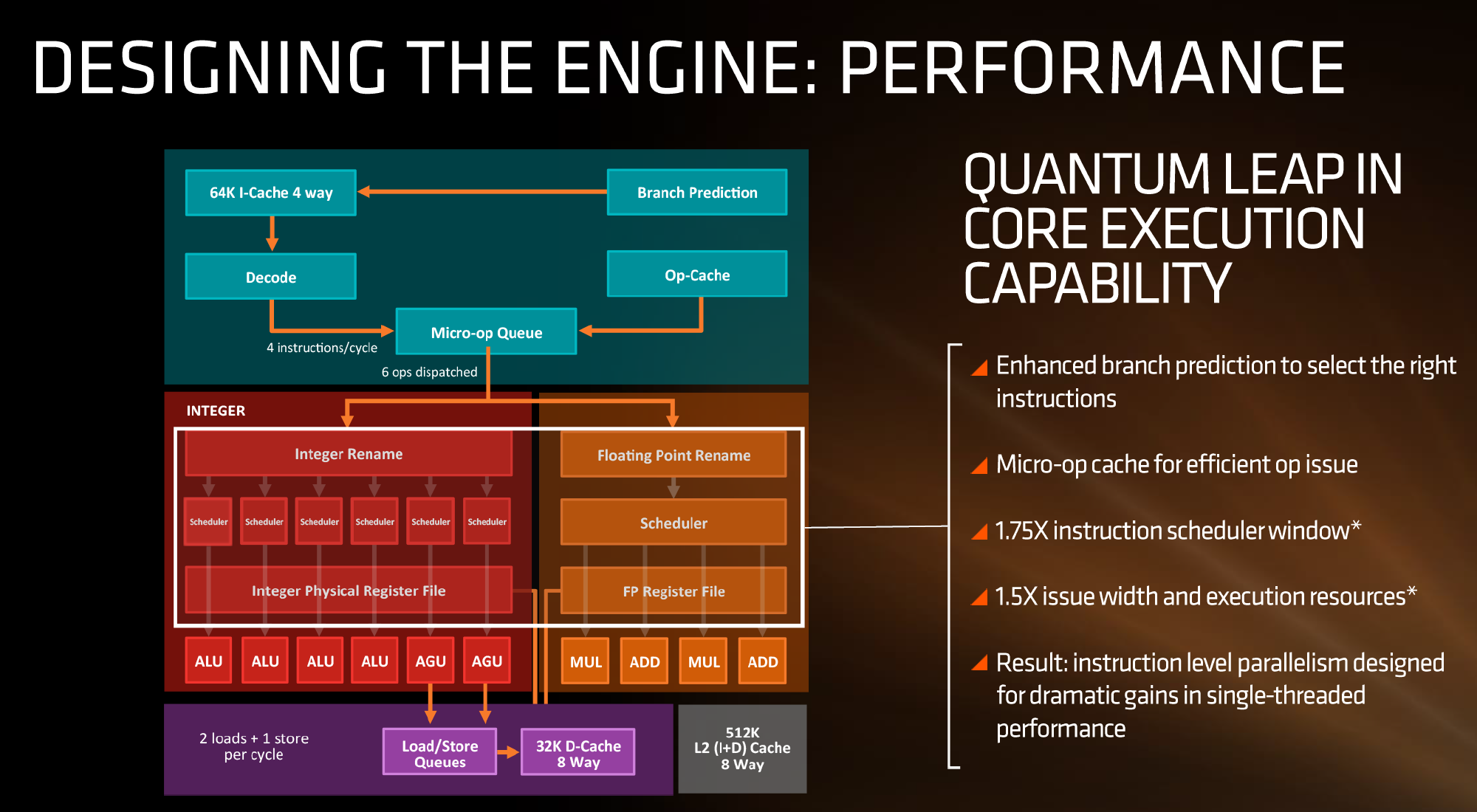
If we focus purely on the left to start, we can see most of the high-level microarchitecture details including basic caches, the new inclusion of an op-cache, some details about decoders and dispatch, scheduler arrangements, execution ports and load/store arrangements. A number of slides later in the presentation talk about cache bandwidth.
Firstly, one of the bigger deviations from previous AMD microarchitecture designs is the presence of a micro-op cache (it might be worth noting that these slides sometimes say op when it means micro-op, creating a little confusion). AMD’s Bulldozer design did not have an operation cache, requiring it to fetch details from other caches to implement frequently used micro-ops. Intel has been implementing a similar arrangement for several generations to great effect (some put it as a major stepping stone for Conroe), so to see one here is quite promising for AMD. We weren’t told the scale or extent of this buffer, and AMD will perhaps give that information in due course.
Aside from the as-expected ‘branch predictor enhancements’, which are as vague as they sound, AMD has not disclosed the decoder arrangements in Zen at this time, but has listed that they can decode four instructions per cycle to feed into the operations queue. This queue, with the help of the op-cache, can deliver 6 ops/cycle to the schedulers. The reasons behind the queue being able to dispatch more per cycle is if the decoder can supply an instruction which then falls into two micro-ops (which makes the instruction vs micro-op definitions even muddier). Nevertheless, this micro-op queue helps feed the separate integer and floating point segments of the CPU. Unlike Intel who uses a combined scheduler for INT/FP, AMD’s diagram suggests that they will remain separate with their own schedulers at this time.
The INT side of the core will funnel the ALU operations as well as the AGU/load and store ops. The load/store units can perform 2 16-Byte loads and one 16-Byte store per cycle, making use of the 32 KB 8-way set associative write-back L1 Data cache. AMD has explicitly made this a write back cache rather than the write through cache we saw in Bulldozer that was a source of a lot of idle time in particular code paths. AMD is also stating that the load/stores will have lower latency within the caches, but has not explained to what extent they have improved.
The FP side of the core will afford two multiply ports and two ADD ports, which should allow for two joined FMAC operations or one 256-bit AVX per cycle. The combination of the INT and FP segments means that AMD is going for a wide core and looking to exploit a significant amount of instruction level parallelism. How much it will be able to depends on the caches and the reorder buffers – no real data on the buffers has been given at this time, except that the cores will have a +75% bigger instruction scheduler window for ordering operations and a +50% wider issue width for potential throughput. The wider cores, all other things being sufficient, will also allow AMD’s implementation of simultaneous multithreading to potentially take advantage of multiple threads with a linear and naturally low IPC.








216 Comments
View All Comments
m1ngky - Saturday, August 20, 2016 - link
It could be the performance boost is only 5% each generation because there wasn't a need for more due to the monopoly Intel has in the CPU market.Once decent competition from AMD emerges I'm betting we see more of a % boost then.
sonicmerlin - Saturday, August 20, 2016 - link
I seriously doubt it, Intel needs performance boosts to sell new products every year. If they could've then they would've.Byte - Thursday, August 18, 2016 - link
Value of top end K chips actually don't really go down that much. If you want to look for a Haswell devils canon, you still have to pony up around $300, maybe you can find a used one for $250ish, but same can be said for a Skylake. Even a 4770k or 3770k is hard to find for under $250 used. Even a 2770k i sold one not too long ago for $245.Nagorak - Thursday, August 18, 2016 - link
Prices for computer hardware isn't dropping very fast because performance has barely increased. A two year old CPU now is for all intents and purposes is just as good as a brand new one. There may be some marginal situations where the 5% difference in performance matters, but for the most part they perform identically.Compare this to the heyday of the late 90s when a two year old CPU might be half as fast as a new one. It was no surprise that upgrade cycles were shorter and resale values much less.
KPOM - Friday, August 19, 2016 - link
Tell that to all the people on MacRumors complaining that the 13" rMBP still has a Broadwell processor.Icehawk - Sunday, August 21, 2016 - link
While I agree with Nagorak, I have moved from a 2yr cycle to a 4+ cycle on CPU/platforms, I think the Apple folks have a right to gripe about the lack of updates - some of them are a few gens back at this point and prices haven't dropped enough to make up for that IMO.smilingcrow - Thursday, August 18, 2016 - link
Their whole CPU business is based on an Intel license to copy; ignoring the ARM stuff.blublub - Thursday, August 18, 2016 - link
1. Intel's X64 is based on AMD's license.....so what !? (remeber the Itanium disaster?)2. AMD also hold X86 licenses which are used by Inte - both x86 and x64 are cross-licenses
So in the end they both license/copy another -- so what!?
And I am pretty sure after the recent Intel/Nvidia rattle that the next Intel GPUs are being build via AMD's license
smilingcrow - Thursday, August 18, 2016 - link
There’s a massive difference though. AMD only has a license due to IBM insisting on Intel allowing a second manufacturer for its patented x86 CPUs.So AMD has been a parasite living on Intel patents with a degree of symbiosis in the relationship. That makes their various successful phases all the more noteworthy and hopefully Zen leads into another long awaited successful phase.
I think you are jumping to conclusions much to quickly over a mere PR spat with Nvidia.
ddriver - Thursday, August 18, 2016 - link
you are such an obvious intel troll fanboy that its just sad