Assessing IBM's POWER8, Part 2: Server Applications on OpenPOWER
by Johan De Gelas on September 15, 2016 8:01 AM ESTFuture Visions: POWER8 with NVLink
Digging a bit deeper, the shiny new S822LC is a different beast. If offers the "NVIDIA improved" POWER8. The core remained the same but the CPU now comes with NVIDIA's NVlink technology. Four of these NVLink ports allows the S822LC to make a very fast (80 GB/s full duplex) and direct link with the latest and greatest of NVIDIA GPUs: the Tesla P100. Ryan has discussed NVLink and the 16 nm P100 in more detail a few months ago. I quote:
NVLink will allow GPUs to connect to either each other or to supporting CPUs (OpenPOWER), offering a higher bandwidth cache coherent link than what PCIe 3 offers. This link will be important for NVIDIA for a number of reasons, as their scalability and unified memory plans are built around its functionality.
Each P100 has a 720 GB/s of memory bandwidth, powered by 16 GB of HBM2 stacked memory. If you combine that with the fact that the P100 has more than twice the processing power in half precision and double precision floating point (important for machine learning algorithms) than its predecessor, it easy to understand why the data transfers from the CPU to GPU can easily become a bottleneck in some applications.
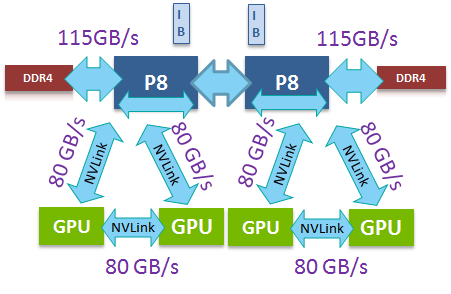
This means that the "OpenPOWER way of working" has enabled the IBM POWER8 to be the first platform to fully leverage the best of NVIDIA's technology. It is almost certain that Intel will not add NVLink to their products, as Intel went a totally different route with the Xeon and Xeon Phi. NVLink offers 80 GB/s of full-duplex connectivity per GPU, which is provided in the form of 4 20GB/s connections that can be routed between GPUs and CPUs as needed. By comparison, a P100 that plugs into an x16 PCIe 3.0 slot only gets 16 GB/s full duplex to communicate with both the CPU and the other GPUs. So theoretically, a quad NVLink setup from GPU to CPU offers at least 2.5 times more bandwidth. However, IBM claims that in reality the advantage is 2.8x as the NVLink is more efficient than PCIe (83% of theoretical bandwidth vs. 74%).

The NVLink equipped P100 cards will make use of the SXM2 form factor and come with a bonus: they deliver 13% more raw compute performance than the "classic" PCIe card due to the higher TDP (300W vs 250W). By the numbers, this amounts to 5.3 TFLOPS double precision for the SXM2 version, versus 4.7 TFLOPS for the PCIe version.








49 Comments
View All Comments
JohanAnandtech - Sunday, September 25, 2016 - link
Thanks Jesper. Looks like I will have to spend even more time on that system :-). And indeed, out of the box performance is important if IBM ever wants to get a piece of the x86 market.luminarian - Thursday, September 15, 2016 - link
It was my understanding that the SMT mode on the power8 could be changed. Depending on the type of work this would make a giant difference, especially with mysql/mariadb that are limited to 1 process/thread per connection.With databases the real winner would be with one that supports parallel queries, such as postgresql 9.6, db2, oracle, etc.
Also yer bench mark very easily could be limiting the power8 if its not opening enough connections to fill out the number of threads that thing can handle, remember mysql/mariaDB are 1 process/thread per connection. Alot of database bench marks default to a small number of connections, this thing has 160 threads with the dual 10 core. I would suggest trying to run that same benchmark again but do it at the same time from multiple client machines. See if the bench takes a larger dip when a second client machine runs the same bench or if the bench shows similar figures(granted this might hit hd io limit on the power8 server).
So yea, that and try SMT-2 and SMT-4 modes.
JohanAnandtech - Friday, September 16, 2016 - link
Hi, I tried SMT-4, throughput was about 25% worse: 11k instead 14k+. 95th perc response time was better: 3.7 ms.JohanAnandtech - Friday, September 16, 2016 - link
updated the MySQL graphs with SMT-4 data. Our Spark tests gets worse with SMT-4 and that is also true for SPECjbb.luminarian - Friday, September 16, 2016 - link
Awesome, Thanks for the response.Meteor2 - Friday, September 16, 2016 - link
The HPC potential is awesome. You can really see why Oak Ridge chose POWER9 and Volta.Communism - Sunday, September 18, 2016 - link
Pretty sure most of the reason for that is due to Intel blocking every attempt Nvidia makes at getting a high bandwidth interface bolted onto a Xeon.Given that one of the main reasons that Intel blocked Nvidia's chipset business way back in the day was to try to limit the ability of other companies bolting on high bandwidth accelerators onto Intel chips (Presumably to protect their own initiatives in that space).
Klimax - Saturday, September 17, 2016 - link
Not terribly impressive. You have to get SW to paly nice and spend time to fine tune it to outperform Intel and it will cost you in power and cooling. More like "yes, if you get quite bigger TDP you get bit more power". And it won't be terribly good in many cases. (Like public facing service where latency is critical)Maybe if you are in USA and can waste admins and devs time and waste a lot on cooling and electricity then maybe. Otherwise why bother...
SarahKerrigan - Sunday, September 18, 2016 - link
I don't see this as a bad result. This is a 22nm processor, over two years old, and it beats Haswell-EP (which is newer) on efficiency. Broadwell-EP is brand new, and P9 should come out well before the end of BDW-EP's lifecycle.Kevin G - Sunday, September 18, 2016 - link
Some of the POWER9 chips will be out next year though is suspect that the scale-up models maybe an early 2018 part. Considering that those chips go into IBM's big iron Unix servers, they tend to launch a bit later than the low end models so it isn't game changing.The real question is when SkyLake-EP/EX will launch and in comparison to the scale-out POWER9 chips. I was expecting a first half of 2017 for the Intel parts but I have no reference as to when to expect the POWER9 SO chips. Thus there is a chance Intel can come out first.
Intel also wants a quick transition to SkyLake-EP/EX as they unify those to lines to some extent and provide some major platform improvements. I'm thinking Broadwell-EP/EX will have a relatively short life span compared to Haswell-EP/EX. This mimics much of what happened on the desktop and the challenge to move to 14 nm.