Ten Year Anniversary of Core 2 Duo and Conroe: Moore’s Law is Dead, Long Live Moore’s Law
by Ian Cutress on July 27, 2016 10:30 AM EST- Posted in
- CPUs
- Intel
- Core 2 Duo
- Conroe
- ITRS
- Nostalgia
- Time To Upgrade
Core: It’s all in the Prefetch
In a simple CPU design, instructions are decoded in the core and data is fetched from the caches. In a perfect world, such as the Mill architecture, the data and instructions are ready to go in the lowest level cache at all times. This allows for the lowest latency and removes a potential bottleneck. Real life is not that rosy, and it all comes down to how the core can predict what data it needs and has enough time to drag it down to the lowest level of cache it can before it is needed. Ideally it needs to predict the correct data, and not interfere with memory sensitive programs. This is Prefetch.
The Core microarchitecture added multiple prefetchers in the design, as well as improving the prefetch algorithms, to something not seen before on a consumer core. For each core there are two data and one instruction prefetchers, plus another couple for the L2 cache. That’s a total of eight for a dual core CPU, with instructions not to interfere with ‘on-demand’ bandwidth from running software.
One other element to the prefetch is tag lookup for cache indexing. Data prefetchers do this, as well as running software, so in order to avoid a higher latency for the running program, the data prefetch uses the store port to do this. As a general rule (at least at the time), loads happen twice as often as stores, meaning that the store port is generally more ‘free’ to be used for tag lookup by the prefetchers. Stores aren’t critical for most performance metrics, unless the system can’t process stores quickly enough that it backs up the pipeline, but in most cases the rest of the core will be doing things regardless. The cache/memory sub-system is in control for committing the store through the caches, so as long as this happens eventually the process works out.
Core: More Cache Please
Without having access to a low latency data and instruction store, having a fast core is almost worthless. The most expensive SRAMs sit closest to the execution ports, but are also the smallest due to physical design limitations. As a result, we get a nested cache system where the data you need should be in the lowest level possible, and accesses to higher levels of cache are slightly further away. Any time spent waiting for data to complete a CPU instruction is time lost without an appropriate way of dealing with this, so large fast caches are ideal. The Core design, over the previous Netburst family but also over AMD’s K8 ‘Hammer’ microarchitecture, tried to swat a fly with a Buick.
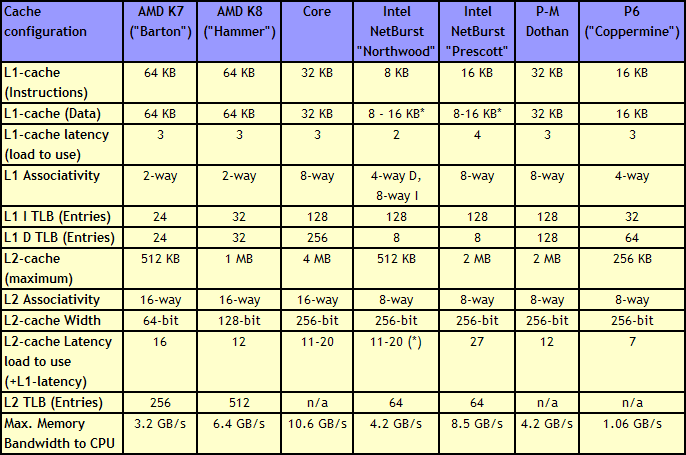
Core gave a 4 MB Level 2 cache between two cores, with a 12-14 cycle access time. This allows each core to use more than 2MB of L2 if needed, something Presler did not allow. Each core also has a 3-cycle 32KB instruction + 32KB data cache, compared to the super small Netburst, and also supports 256 entries in the L1 data TLB, compared to 8. Both the L1 and L2 are accessible by a 256-bit interface, giving good bandwidth to the core.
Note that AMD’s K8 still has a few advantages over Core. The 2-way 64KB L1 caches on AMD’s K8 have a slightly better hit rate to the 8-way 32KB L1 caches on Core, with a similar latency. AMD’s K8 also used an on-die memory controller, lowering memory latency significantly, despite the faster FSB of Intel Core (relative to Netburst) giving a lower latency to Core. As stated in our microarchitecture overview at the time, Athlon 64 X2s memory advantage had gotten smaller, but a key element to the story is that these advantages were negated by other memory sub-system metrics, such as prefetching. Measured by ScienceMark, the Core microarchitecture’s L1 cache delivers 2x bandwidth, and the L2 cache is about 2.5x faster, than the Athlon one.








158 Comments
View All Comments
fanofanand - Thursday, July 28, 2016 - link
Ian, your reviews are always too notch. You have incredible knowledge, and your understanding of both CPU and memory architecture etc is unparalleled in journalism. Ignore the trolls, this was a fantastic article.extide - Wednesday, July 27, 2016 - link
Different editors for different content. Honestly I thought this was a great piece. I think this site is not quite up to what it was back then, just go read the articles for Fermi, or when Bulldozer released and stuff, much more deep dives into the architecture. I realize that Intel and the other manufacturers may not always be willing to release much info, and they seem to release less these days but I don't know -- the site feels different.Honestly, and I am pretty forgiving, being as late as this site has on the recent GPU reviews is pretty inexcusable. Although, that is obviously nothing to do with Ian, I always like Ian's articles.
Ian Cutress - Wednesday, July 27, 2016 - link
Thanks! :)fanofanand - Thursday, July 28, 2016 - link
The Pascal review was pretty damn deep, not sure how much farther you expect them to dive. That said, it was very, very late.Michael Bay - Thursday, July 28, 2016 - link
ADHD millennial detected.Notmyusualid - Thursday, July 28, 2016 - link
Hey Rain Cloud!I enjoyed it, as did many others here - try reading the friendly discussion!
tipoo - Wednesday, July 27, 2016 - link
I like articles like these. Sometimes certain processors stick around as the baseline in my brain even after a decade (holy hell!). Core 2 Duo is always a reference point for me, so is a 3GHz P4.rocky12345 - Wednesday, July 27, 2016 - link
Yea I still have a Q6600 Core2Quad running strong in the front rooom OC to 3700Mhz been running like that since day 1.wumpus - Thursday, August 4, 2016 - link
Wow. I've assumed that they would at least burn out so that they would need replacement (like my old super celeries). I'm sure you can measure a speed increase between a modern i5 and yours, but it would be hard to notice it.chekk - Wednesday, July 27, 2016 - link
Nice, thanks Ian. Interesting to look back and then ahead.I still use my E6400 in a media playback machine using the first "good" integrated graphics, the NVidia 9300. Since it runs at stock frequency @ 1V (VID spec is 1.325), it's pretty efficient too.