The AMD Radeon RX 480 Preview: Polaris Makes Its Mainstream Mark
by Ryan Smith on June 29, 2016 9:00 AM ESTThe Polaris Architecture: In Brief
For today’s preview I’m going to quickly hit the highlights of the Polaris architecture.
In their announcement of the architecture this year, AMD laid out a basic overview of what components of the GPU would see major updates with Polaris. Polaris is not a complete overhaul of past AMD designs, but AMD has combined targeted performance upgrades with a chip-wide energy efficiency upgrade. As a result Polaris is a mix of old and new, and a lot more efficient in the process.
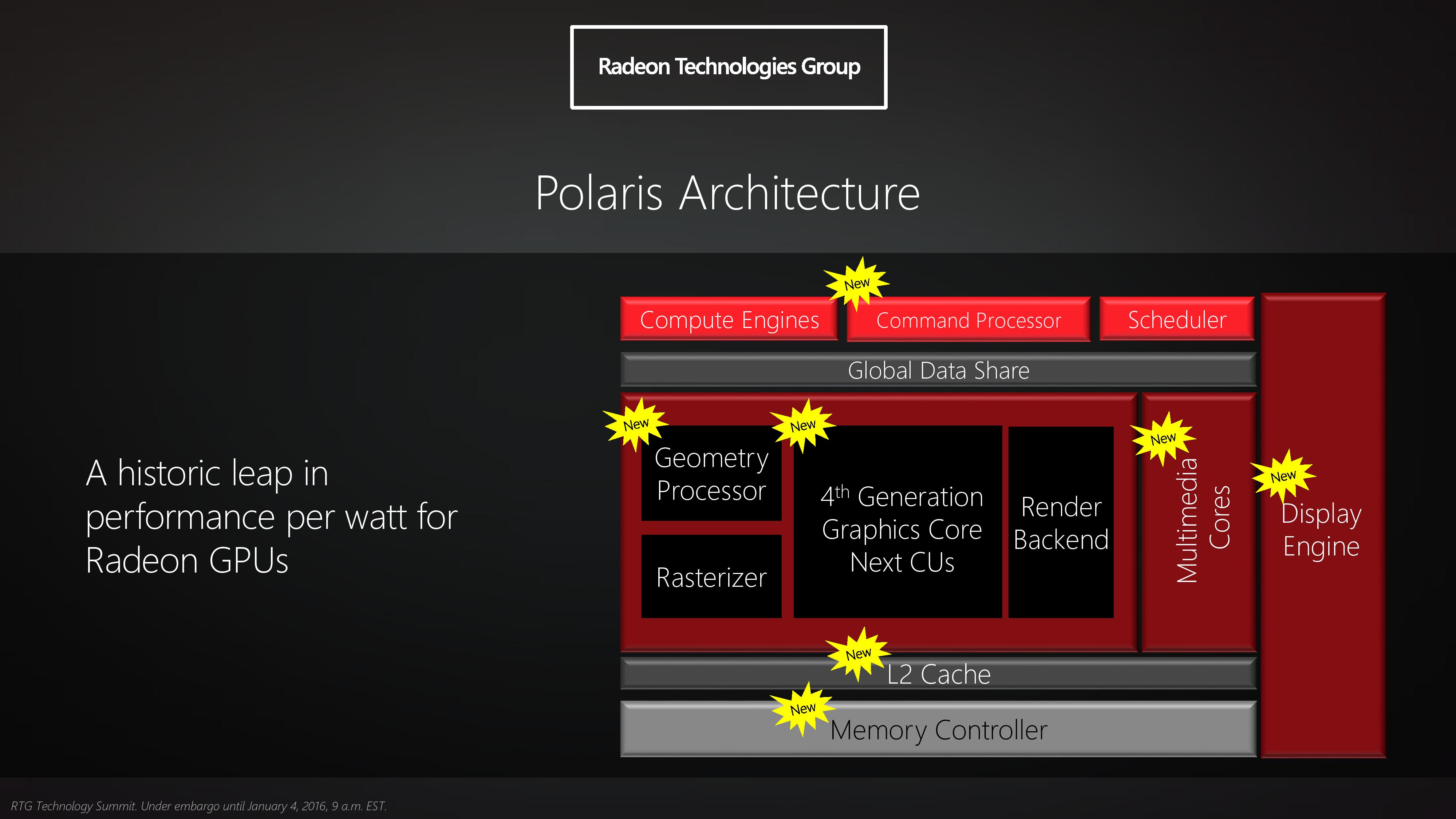
At its heart, Polaris is based on AMD’s 4th generation Graphics Core Next architecture (GCN 4). GCN 4 is not significantly different than GCN 1.2 (Tonga/Fiji), and in fact GCN 4’s ISA is identical to that of GCN 1.2’s. So everything we see here today comes not from broad, architectural changes, but from low-level microarchitectural changes that improve how instructions execute under the hood.

Overall AMD is claiming that GCN 4 (via RX 480) offers a 15% improvement in shader efficiency over GCN 1.1 (R9 290). This comes from two changes; instruction prefetching and a larger instruction buffer. In the case of the former, GCN 4 can, with the driver’s assistance, attempt to pre-fetch future instructions, something GCN 1.x could not do. When done correctly, this reduces/eliminates the need for a wave to stall to wait on an instruction fetch, keeping the CU fed and active more often. Meanwhile the per-wave instruction buffer (which is separate from the register file) has been increased from 12 DWORDs to 16 DWORDs, allowing more instructions to be buffered and, according to AMD, improving single-threaded performance.
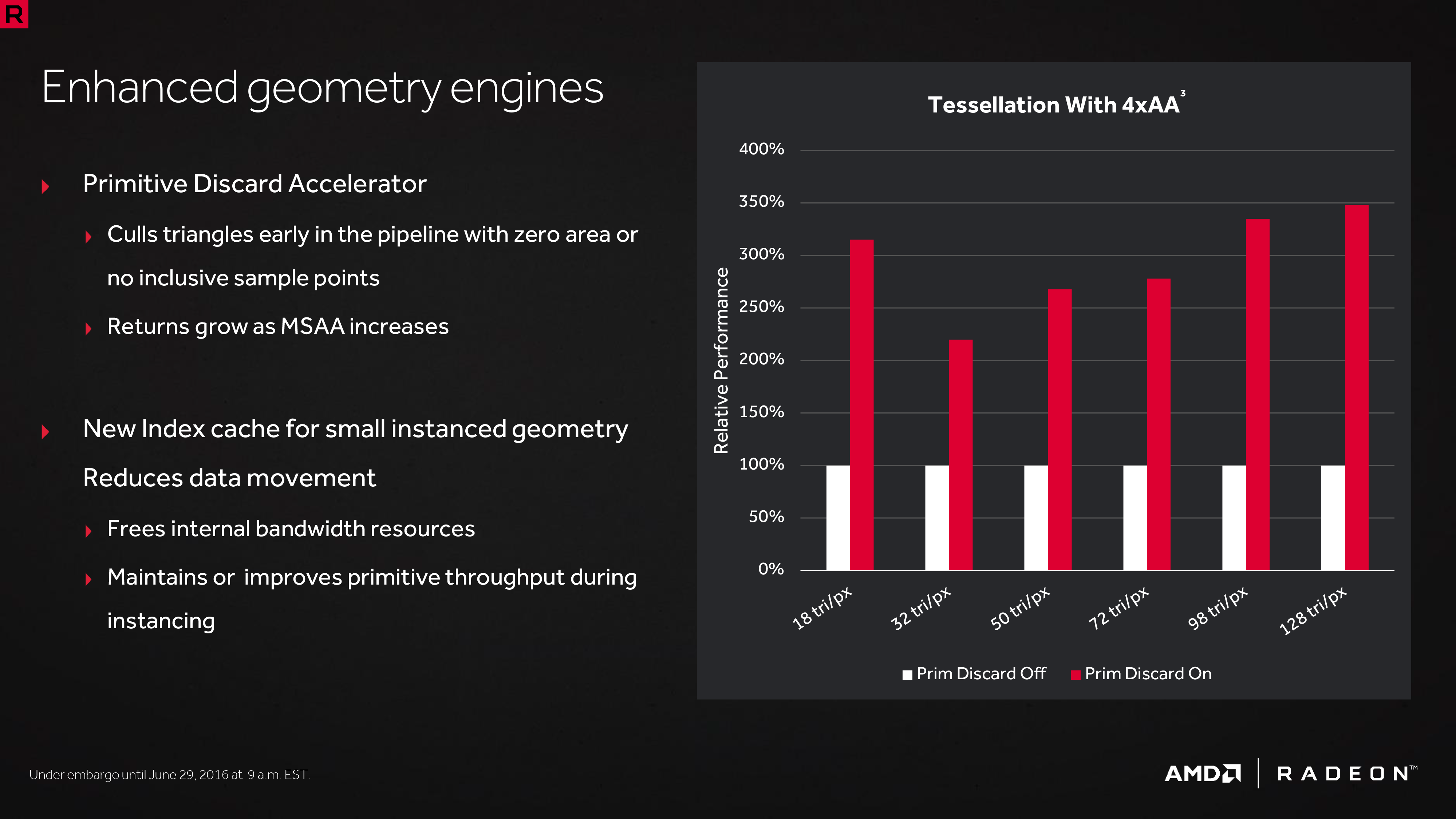
Outside of the shader cores themselves, AMD has also made enhancements to the graphics front-end for Polaris. AMD’s latest architecture integrates what AMD calls a Primative Discard Accelerator. True to its name, the job of the discard accelerator is to remove (cull) triangles that are too small to be used, and to do so early enough in the rendering pipeline that the rest of the GPU is spared from having to deal with these unnecessary triangles. Degenerate triangles are culled before they even hit the vertex shader, while small triangles culled a bit later, after the vertex shader but before they hit the rasterizer. There’s no visual quality impact to this (only triangles that can’t be seen/rendered are culled), and as claimed by AMD, the benefits of the discard accelerator increase with MSAA levels, as MSAA otherwise exacerbates the small triangle problem.
Along these lines, Polaris also implements a new index cache, again meant to improve geometry performance. The index cache is designed specifically to accelerate geometry instancing performance, allowing small instanced geometry to stay close by in the cache, avoiding the power and bandwidth costs of shuffling this data around to other caches and VRAM.
Finally, at the back-end of the GPU, the ROP/L2/Memory controller partitions have also received their own updates. Chief among these is that Polaris implements the next generation of AMD’s delta color compression technology, which uses pattern matching to reduce the size and resulting memory bandwidth needs of frame buffers and render targets. As a result of this compression, color compression results in a de facto increase in available memory bandwidth and decrease in power consumption, at least so long as buffer is compressible. With Polaris, AMD supports a larger pattern library to better compress more buffers more often, improving on GCN 1.2 color compression by around 17%.
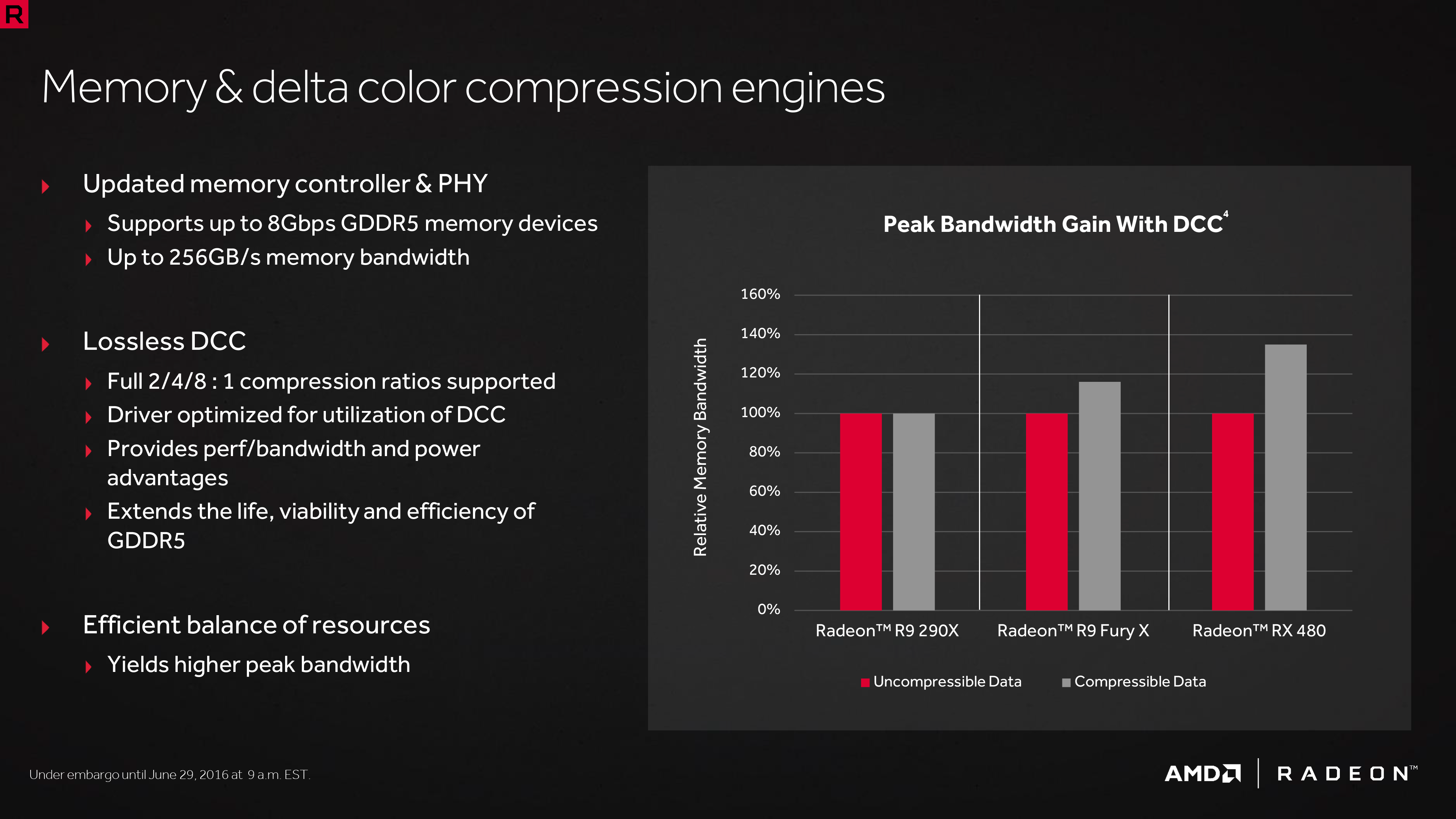
Otherwise we’ve already covered the increased L2 cache size, which is now at 2MB. Paired with this is AMD’s latest generation memory controller, which can now officially go to 8Gbps, and even a bit more than that when oveclocking.








449 Comments
View All Comments
Hurn - Thursday, June 30, 2016 - link
The real question, here, is why the R9 380 beats the pants off of the R9 380X in many tests.Example: Dirt Rally 1920x1080 Ultra Quality. The 380 gets 64.3, while the 380X only gets 33.1. Half the speed from a card that's supposed to be faster?? Investigation needed!
Ryan Smith - Friday, July 1, 2016 - link
Thanks.It looks like I errored when transcribing the results into the database. I've gone through and corrected the charts.
Archie2085 - Friday, July 1, 2016 - link
@Ryan Any possibility you can cover whats leakage on this process . Lower Temps leading to lower power draw without reducing clocks??? either changing coolers or lowering ambient temp by blowing cold air??Been seeing posts of disproportionate increase in temps and powerdraw
FourEyedGeek - Thursday, June 30, 2016 - link
I'll wait to RX 490.Locut0s - Friday, July 1, 2016 - link
So I guess like the 1080 this will be a "preview" that we will never get an actual review of.pencea - Friday, July 1, 2016 - link
Yup exactly.Anand still hasn't done a review of both GTX 1070 or 1080, and now the 480. While other major sites have already done both reference and custom reviews, along with SLI testing on the Nvidia cards.
Unacceptable for a site like this.
X-Alt - Friday, July 1, 2016 - link
Let's look at it this way2900XT->7970->R9 290X->Fury X-???
6970->7950->R9 290->Fury Nano\390X->???
6950->7870->R9 280X->R9 380X->RX480
6870->7850->R9 270X->R9 380->??
All that matters is how the 1060 stacks up
dani_dacota - Friday, July 1, 2016 - link
Ryan, did you have a separate 4GB card to test or did you switch the vram config in the bios. Reason I ask is because I am wondering if the extra 4GB of vram might be pushing the RX 480 to post power consumption figures as high as the 970 even though the gpu chip itself is more efficient. If the extra 4GB of vram consumes 15-20W of power itself than the power efficiency numbers might improve significantly compared to the 970.FreeKill - Friday, July 1, 2016 - link
*Wondering what year we'll get the REAL full version of this GPU as a re-badge* I completely understand chip harvesting to sell the highest percentage of chips out of a fab, But I can't help but be pissed off with AMD about advertising to everyone that this is a fully enabled chip as I highly doubt it is, I believe it has 40 CU's and 2560 SP's and is currently neutered in order to hit their marketing points (power, price) They've done this with virtually every newly released GPU for years now so I should be used to it but time will tell if suddenly there's a 40 CU, GDDR5X Polaris based card in 12 months badged as a 570. I think Tahiti (7970) and Fiji (Fury X) are the only two GPU's they haven't neutered and lied about from day 1Several examples:
Tonga:
http://www.kitguru.net/components/graphic-cards/an...
Hawaii:
http://forums.guru3d.com/showthread.php?t=385046
Tams80 - Saturday, July 2, 2016 - link
I don't understand your issues with this, other than perhaps a concern for wasting natural resources.As long as AMD provide what they claim to, at the price they state; then what is the issue? Sure, they could make something better, but that is not the market they have targeted with this product.