The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTGPU Boost 3.0: Finer-Grained Clockspeed Controls
While much of this is abstracted away in everyday GPU discussions, under the hood the concept of clockspeed is a little lot more complex than the simple base clock and boost clock numbers posted in specification tables. Since the introduction of Kepler, NVIDIA has introduced fine-grained voltage points, which defines a series of GPU voltages and their respective clockspeeds. The GPU in turn operates at points along the resulting curve, shifting clockspeeds based on which voltage it’s at and what the environmental conditions are.
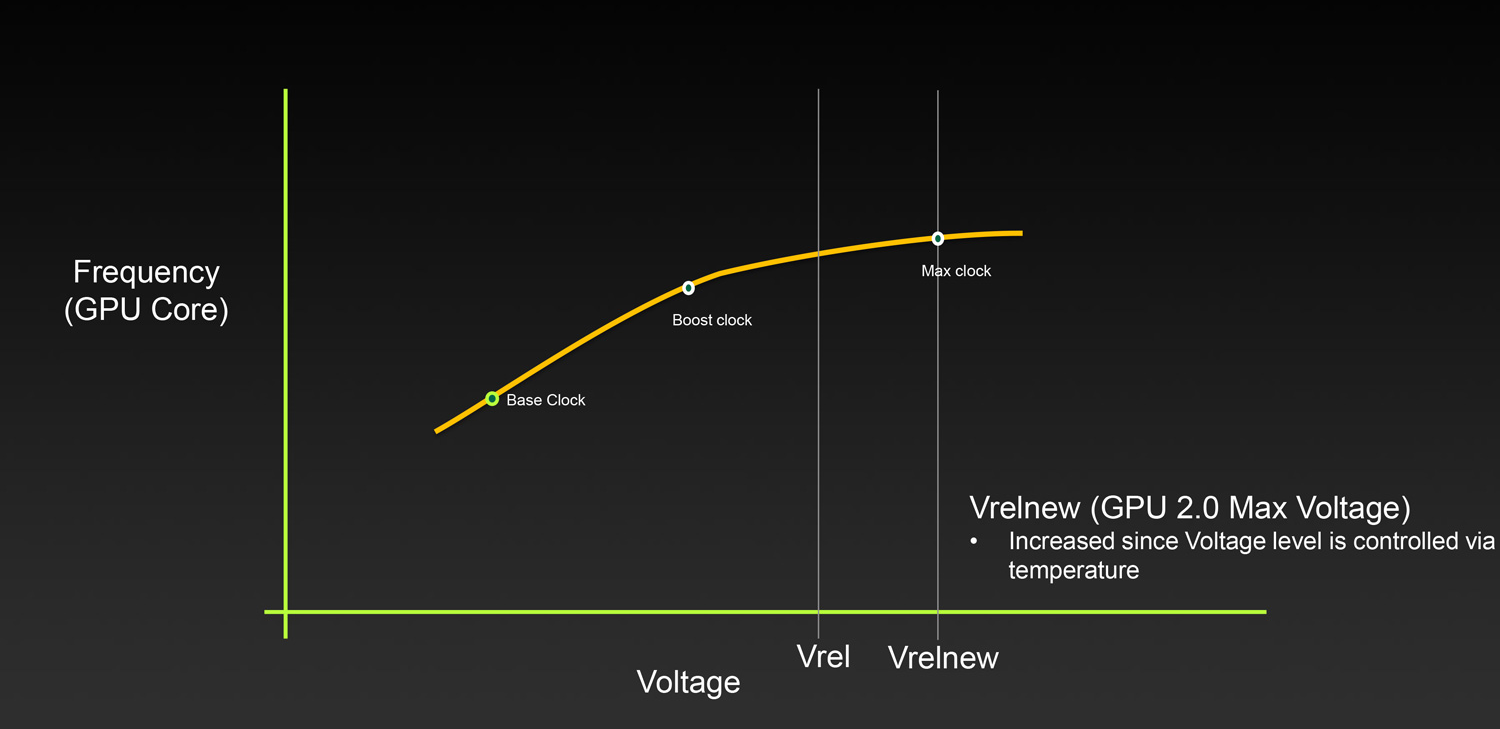
While these voltage points have been present since Kepler, NVIDIA has not, until now, exposed them to end users. However with Pascal this is finally changing, with the introduction of GPU Boost 3.0.
With the latest rendition of NVIDIA’s GPU clockspeed management technology, NVIDIA has made the individual voltage points programmable, and in turn they are exposing this functionality to third party overclocking programs via NVAPI. Consequently it is now possible to adjust the clockspeed of Pascal GPUs at each voltage point, a much greater level of control than before.
The addition of finer-grained controls is designed to improve the flexibility of overclocking on Pascal. Prior to GPU Boost 3.0, the only way to overclock was to adjust the clockspeed for all voltage points by the same amount at the same time – or in NVIDIA’s GPU Boost 3.0 vernacular, a fixed frequency offset. While this certainly works, it limits the highest stable overclock to the lowest point on the voltage/frequency curve. If the GPU can only overclock by 50MHz at the highest voltage point, but 100MHz at a middle point, then the highest stable overclock is only going to be 50MHz.
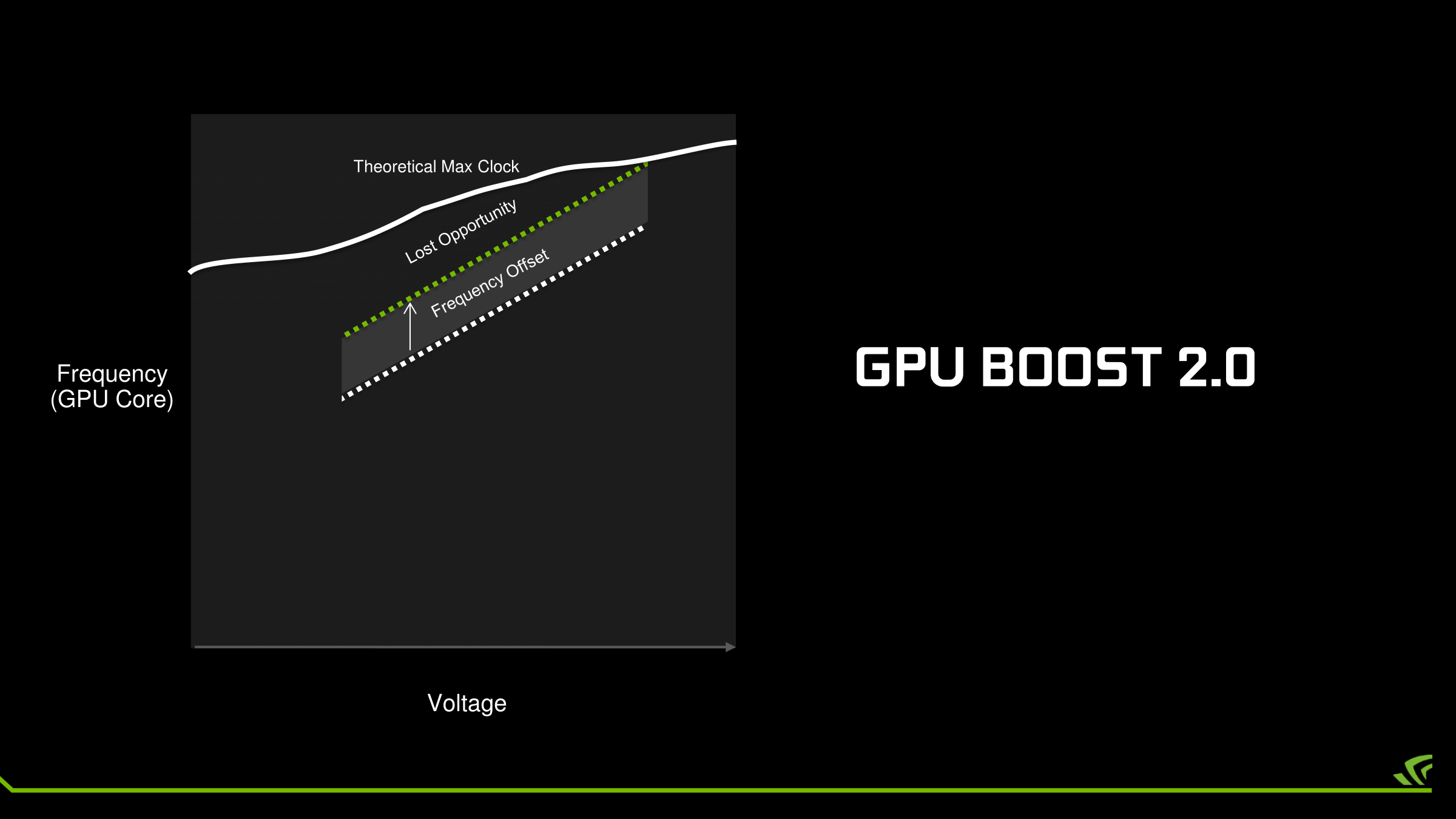
With GPU Boost 3.0 on the other hand, each point on the curve can be adjusted individually. This means the weakest points can be overclocked to a lesser degree while the strongest points can be more significantly overclocked. All other things held equal, this should improve GPU overclocking performance, as GPU tends to shift along multiple points when it’s running. Put another way: GPU Boost 3.0 seeks to wring out the last bits of overclocking headroom along the voltage frequency curve. The only way to go higher still would be to increase the voltage, which NVIDIA hasn’t truly allowed since Fermi.
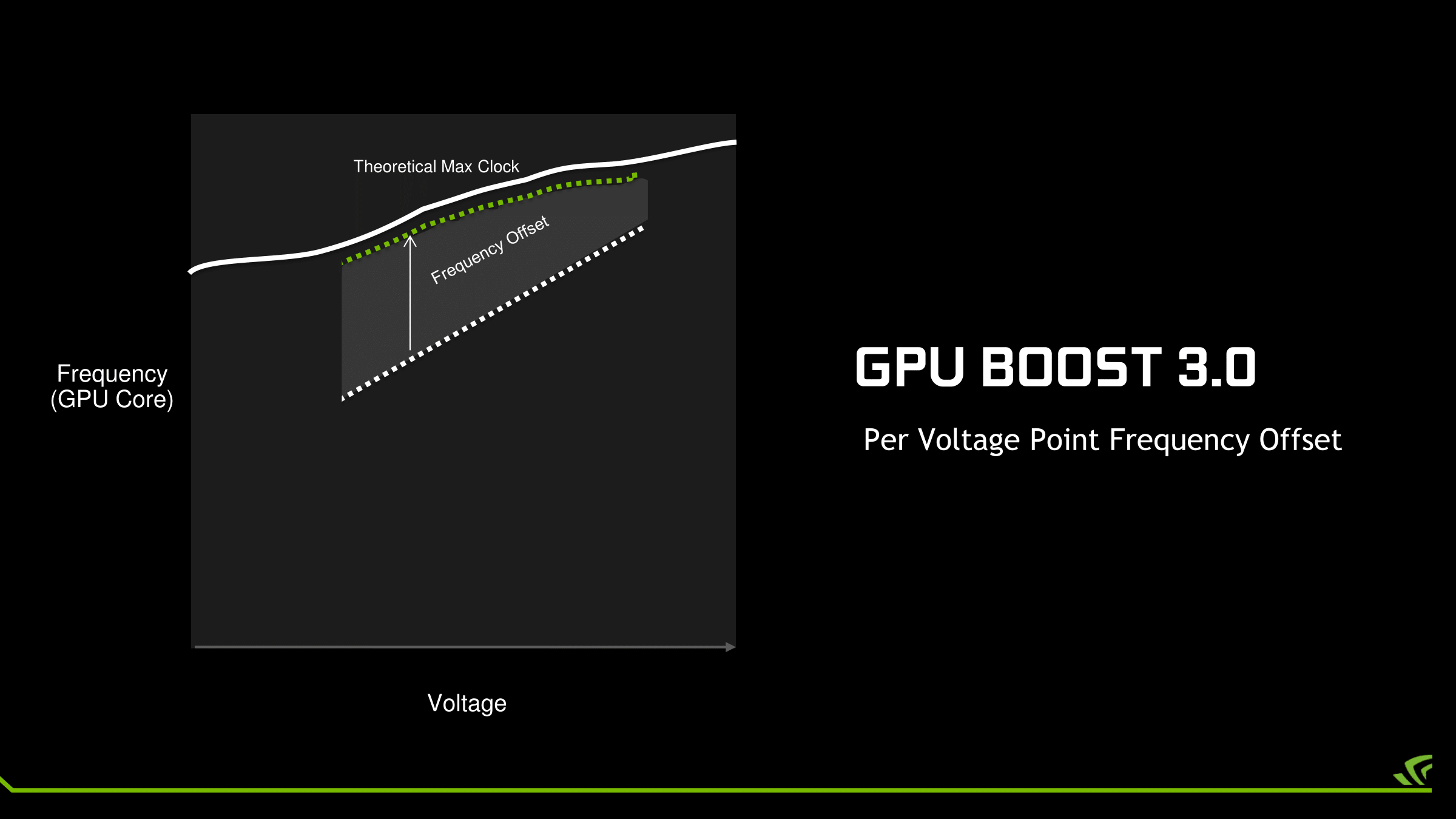
Meanwhile, the flip side of having finer-grained controls is that it’s now more work to dial in the perfect overclock. Rather than testing one overclock you now have to test nearly two-dozen voltage points to fully exploit GPU Boost 3.0’s abilities, which is time consuming at the best of times. As a result NVIDIA has also exposed a setting in NVAPI to lock the GPU at a specific voltage point. The significance of this is that it now allows overclocking utilities to go through the voltage points and discretely test each one.
The first software to implement this concept is EVGA’s Precision XOC. The latest iteration of EVGA’s overclocking software is able to go through the voltage points and run an OC ScannerX test on each one to find its stability. When a point fails, Precision XOC will then back off the frequency at that point and move on. The end result is that after a series of trials and failures, you should have the virtually-perfect overclock.
Unfortunately while this is sound in concept, in practice NVIDIA and EVGA still aren’t quite there yet. Overclocking failures can cause multiple types of failures; graphic corruption (easy to catch and recover), driver crashes (moderately difficult to recover from), and system hardlocks (very difficult to recover from). In practice, Precision XOC isn’t yet at the point where it can quickly and efficiently handle the last two cases; so driver crashes and system hardlocks still require human intervention, and Precision XOC doesn’t do a great job of resuming from where it left off.
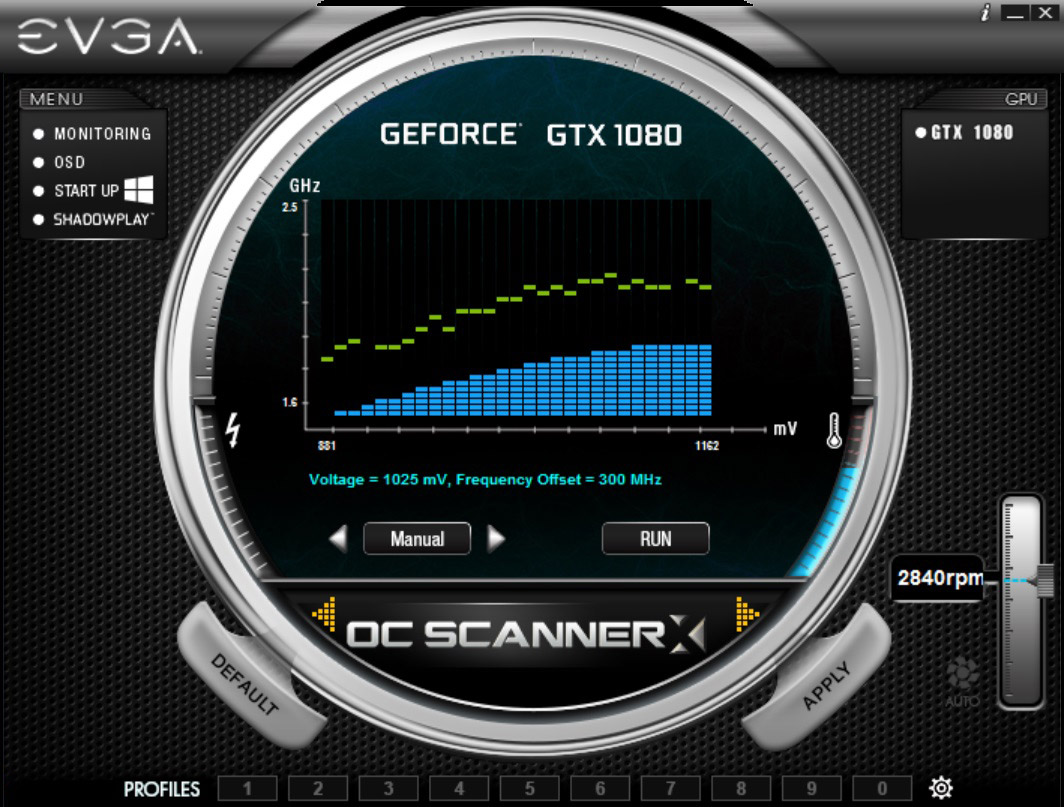
Hopefully one day NVIDIA and EVGA will get there, but for now the only practical way to fully exploit GPU Boost 3.0 is the tedious way. This means either using traditional offset overclocking, or a mode NVIDIA calls linear overclocking, in which the slope of the voltage/frequency curve is adjusted rather than offset (think m in y=mx+b rather than b). In this case two points are picked, and all of the voltage points are overclocked to match the resulting linear curve.
Observations on Clocking with Pascal
While we’re on the subject of clockspeed management on Pascal, I want to discuss my observations with how clockspeeds work on NVIDIA’s newest GPU. When it comes to clockspeed management NVIDIA hasn’t just changed how overclocking works, but relative to Kepler/Maxwell, there are some other, subtle changes.
To start, Pascal clockspeeds are much more temperature-dependent than on Maxwell 2 or Kepler. Kepler would drop a single bin at a specific temperature, and Maxwell 2 would sustain the same clockspeed throughout. However Pascal will drop its clockspeeds as the GPU warms up, regardless of whether it still has formal thermal and TDP headroom to spare. This happens by backing off both on the clockspeed at each individual voltage point, and backing off to lower voltage points altogether.
To quantify this effect, I ran LuxMark 3.1 continuously for several minutes, until the GPU temperature leveled out. As a compute test, LuxMark does not cause the GTX 1080 to hit its 83C temperature limit nor its 180W TDP limit, so it’s a good example of the temperature compensation effect.
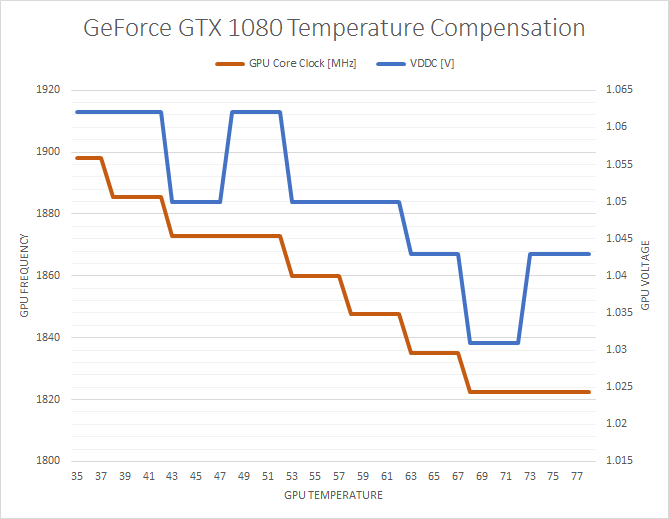
What we find is that from the start of the run until the end, the GPU clockspeed drops from the maximum boost bin of 1898MHz to a sustained 1822MHz, a drop of 4%, or 6 clockspeed bins. These shifts happen relatively consistently up to 68C, after which they stop.
For what it’s worth, the GTX 1080 gets up to 68C relatively quickly, so GPU performance stabilizes rather soon. But this does mean that GTX 1080’s performance is more temperature dependent than GTX 980’s. Throwing a GTX 1080 under water could very well net you a few percent performance increase by avoiding the compensation effect, along with any performance gained from avoiding the card’s 83C temperature throttle.
In any case, I believe this to be compensation for the effects of higher temperatures on the GPU, backing off on voltages/clockspeeds due to potential issues. What those issues are I’m not sure; it could be that 16nm FinFET doesn’t like high voltages at higher temperatures (NVIDIA takes several steps to minimize GPU degradation), or something else entirely.
Otherwise, outside of the temperature compensation effect, clockspeeds on GTX 1080 appear to mostly be a function of temperature or running out of boost bins (VREL limited). The card rarely appears to be TDP limited, especially at steady-state. This indicates that NVIDIA could probably increase the fan speed of the cooler a bit to get a bit more performance, but at the cost of generating a bit more noise.
Finally, how overvolting is being represented is a bit different from before. Previously NVIDIA (and EVGA Precision) would show the exact additional voltage (i.e. the voltage of the unlocked voltage points) when overvolting. However now overvolting is expressed on a percentage scale from 0% to 100%, which obfuscates what the higher voltage points actually are. However this hasn’t changed the underlying behavior of overvolting; one or more voltage points are calibrated by NVIDIA, but they are locked due to the potential for GPU degradation. Overvolting then unlocks these points, allowing the GPU to boost higher so long as there is thermal and power headroom to allow it.








200 Comments
View All Comments
Matt Doyle - Wednesday, July 20, 2016 - link
Same page, "The latter is also a change from GTX 980, as NVIDIA has done from a digital + analog DVI port to a pure digital DVI port.""NVIDIA has gone"?
Matt Doyle - Wednesday, July 20, 2016 - link
Rather, "Meet the GTX 1080" page, second to last paragraph.Matt Doyle - Wednesday, July 20, 2016 - link
"Meet the GTX 1080..." page, "...demand first slow down to a point where board partners can make some informed decisions about what cards to produce."I believe you're missing the word "must" (or alternatively, "needs to") between "demand" and "first" in this sentence.
Ryan Smith - Wednesday, July 20, 2016 - link
Thanks!supdawgwtfd - Wednesday, July 20, 2016 - link
Didn't even finish reading the first page. The bias is overwhelming... So much emotional language...Good bye Anandtech. Had been a nice 14 years of reading but it's obvious now you have moved to so many other sites.
Shills who can't restrain their bias and review something without the love of a brand springing forth like a fountain.
Yes i created an account just for this soul reason...
The fucking 2 month wait is also not on.
But what to expect form children,
BMNify - Wednesday, July 20, 2016 - link
Then just GTFO you idiot, on second thoughts crying your heart out may also help in this fanboy mental break down situation of yours.catavalon21 - Wednesday, July 20, 2016 - link
You're joking, or a troll, or a clown. I complained about the time it took to get the full article, (to Ryan's credit, for the impatient ones of us just looking for numbers, he noted a while back that GPU bench was updated to include benchmarks for these cards), but this is exactly the kind of review that often has separated AT from numerous other sites. The description of the relatively crummy FP16 performance was solid and on point. From NV themselves teasing us with ads that half precision would rock our world, well, this review covers in great detail the reset of the story.Yeah, I know guys, I shouldn't dignify it with a response.
atlantico - Thursday, July 21, 2016 - link
Anandtech have always been nvidia shills. Sad they can't make a living without getting paid by nvidia, but they're not alone. Arstechnica is even worse and Tomshardware is way worse.brookheather - Wednesday, July 20, 2016 - link
Typo page 12 - "not unlike AMD’s Pascal architecture" - think you mean Polaris?brookheather - Wednesday, July 20, 2016 - link
And another one on the last page: it keep the GPU industry - should be kept.