The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTFP16 Throughput on GP104: Good for Compatibility (and Not Much Else)
Speaking of architectural details, I know that the question of FP16 (half precision) compute performance has been of significant interest. FP16 performance has been a focus area for NVIDIA for both their server-side and client-side deep learning efforts, leading to the company turning FP16 performance into a feature in and of itself.
Starting with the Tegra X1 – and then carried forward for Pascal – NVIDIA added native FP16 compute support to their architectures. Prior to these parts, any use of FP16 data would require that it be promoted to FP32 for both computational and storage purposes, which meant that using FP16 did not offer any meaningful improvement in performance or storage needs. In practice this meant that if a developer only needed the precision offered by FP16 compute (and deep learning is quickly becoming the textbook example here), that at an architectural level power was being wasted computing that extra precision.
Pascal, in turn, brings with it native support for FP16 compute for both storage and compute. On the storage side, Pascal supports FP16 datatypes, with relative to the previous use of FP32 means that FP16 values take up less space at every level of the memory hierarchy (registers, cache, and DRAM). On the compute side, Pascal introduces a new type of FP32 CUDA core that supports a form of FP16 execution where two FP16 operations are run through the CUDA core at once (vec2). This core, which for clarity I’m going to call an FP16x2 core, allows the GPU to process 1 FP32 or 2 FP16 operations per clock cycle, essentially doubling FP16 performance relative to an identically configured Maxwell or Kepler GPU.
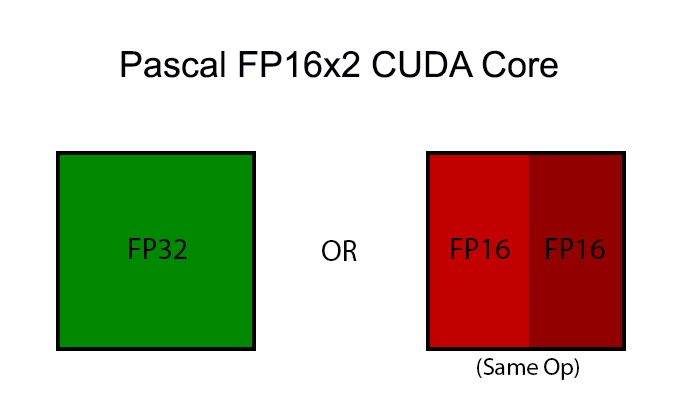
Now there are several special cases here due to the use of vec2 – packing together operations is not the same as having native FP16 CUDA cores – but in a nutshell NVIDIA can pack together FP16 operations as long as they’re the same operation, e.g. both FP16s are undergoing addition, multiplication, etc. Fused multiply-add (FMA/MADD) is also a supported operation here, which is important for how frequently it is used and is necessary to extract the maximum throughput out of the CUDA cores.
Low precision operations are in turn seen by NVIDIA as one of the keys into further growing their increasingly important datacenter market, as deep learning and certain other tasks are themselves rapidly growing fields. Pascal isn’t just faster than Maxwell overall, but when it comes to FP16 operations on the FP16x2 core, Pascal is a lot faster, with theoretical throughput over similar Maxwell GPUs increasing by over three-fold thanks to the combination of overall speed improvements and double speed FP16 execution.
GeForce GTX 1080, on the other hand, is not faster at FP16. In fact it’s downright slow. For their consumer cards, NVIDIA has severely limited FP16 CUDA performance. GTX 1080’s FP16 instruction rate is 1/128th its FP32 instruction rate, or after you factor in vec2 packing, the resulting theoretical performance (in FLOPs) is 1/64th the FP32 rate, or about 138 GFLOPs.

After initially testing FP16 performance with SiSoft Sandra – one of a handful of programs with an FP16 benchmark built against CUDA 7.5 – I reached out to NVIDIA to confirm whether my results were correct, and if they had any further explanation for what I was seeing. NVIDIA was able to confirm my findings, and furthermore that the FP16 instruction rate and throughput rates were different, confirming in a roundabout manner that GTX 1080 was using vec2 packing for FP16.
As it turns out, when it comes to FP16 NVIDIA has made another significant divergence between the HPC-focused GP100, and the consumer-focused GP104. On GP100, these FP16x2 cores are used throughout the GPU as both the GPU’s primarily FP32 core and primary FP16 core. However on GP104, NVIDIA has retained the old FP32 cores. The FP32 core count as we know it is for these pure FP32 cores. What isn’t seen in NVIDIA’s published core counts is that the company has built in the FP16x2 cores separately.
To get right to the point then, each SM on GP104 only contains a single FP16x2 core. This core is in turn only used for executing native FP16 code (i.e. CUDA code). It’s not used for FP32, and it’s not used for FP16 on APIs that can’t access the FP16x2 cores (and as such promote FP16 ops to FP32). The lack of a significant number of FP16x2 cores is why GP104’s FP16 CUDA performance is so low as listed above. There is only 1 FP16x2 core for every 128 FP32 cores.
Limiting the performance of compute-centric features in consumer parts is nothing new for NVIDIA. FP64 has been treated as a Tesla feature since the beginning, and consumer parts have either shipped with a very small number of FP64 CUDA cores for binary compatibility purposes, or when a GeForce card uses an HPC-class GPU, FP64 performance is artificially restricted. This allows NVIDIA to include a feature for software development purposes while enforcing strict market segmentation between the GeForce and Tesla products. However in the case of FP64, performance has never been slower than 1/32, whereas with FP16 we’re looking at a much slower 1/128 instruction rate. Either way, the end result is that like GP104’s FP64 support, GP104’s FP16 support is almost exclusively for CUDA development compatibility and debugging purposes, not for performant consumer use.
| NVIDIA GPU Native FP Throughput Rates (Relative To FP32) | ||||
| FP16 | FP64 | |||
| GP104 |
1:64
|
1:32
|
||
| GP100 |
2:1
|
1:2
|
||
| GM200 |
N/A (Promoted to FP32)
|
1:32
|
||
| GK110 |
N/A (Promoted to FP32)
|
1:3
|
||
| GK104 |
N/A (Promoted to FP32)
|
1:24
|
||
As for why NVIDIA would want to make FP16 performance so slow on Pascal GeForce parts, I strongly suspect that the Maxwell 2 based GTX Titan X sold too well with compute users over the past 12 months, and that this is NVIDIA’s reaction to that event. GTX Titan X’s FP16 and FP32 performance was (per-clock) identical its Tesla equivalent, the Tesla M40, and furthermore both cards shipped with 12GB of VRAM. This meant that other than Tesla-specific features such as drivers and support, there was little separating the two cards.
The Titan series has always straddled the line between professional compute and consumer graphics users, however if it veers too far into the former then it puts Tesla sales at risk. Case in point: at this year’s NVIDIA GPU Technology Conference, I was approached twice by product vendors who were looking for more Titan X cards for their compute products, as at that time the Titan X was in short supply. Suffice it to say, Titan X has been very popular with the compute crowd.
In any case, limiting the FP16 instruction rate on GeForce products is an easy way to ensure that these products don’t compete with the higher margin Tesla business. NVIDIA has only announced one Tesla so far – the high-end P100 – but even that sold out almost immediately. For now I suspect that NVIDIA wants to ensure that P100 and M40 sales are not impacted by the new GeForce cards.
Overall I’m not surprised that NVIDIA limited the FP16 performance of the GTX 1080 – albeit by a new record – as they clearly consider faster FP16 performance a feature that can be monetized under Tesla. However I have to admit that I am surprised that NVIDIA limited it in hardware on GP104 in this fashion, similar to how they limit FP64 performance, rather than using FP16x2 cores throughout the GPU and using software cap. The difference is that had NVIDIA implemented a complete fast FP16 path in GP104 and merely turned it off for GeForce, then they could have used GP104 for high performance (and high margin) FP16 Tesla cards. However by building GP104 from the get-go with a single FP16x2 unit per SM, they have closed the door on that option.
Where things may get especially interesting when it comes to FP16 performance is in smaller-still chips such as GP106. NVIDIA admittedly never used GM204 as a high performance compute part – it was used in the virtualization focused Tesla M6 and M60 cards – but NVIDIA did produce a small form factor compute and deep learning focused card with the GM206 based Tesla M4. I fully expect that NVIDIA will want a successor to this card, which will be hard to do if only GP100 has fast FP16 support. At the same time NVIDIA has still yet to disclose the dGPUs used with the DRIVE PX 2 module, where again fast FP16 support is useful for neural network inference. It may very well be that GP104’s low hardware FP16 performance is something that is not shared by the rest of the Pascal consumer GPU family.








200 Comments
View All Comments
Flunk - Wednesday, July 20, 2016 - link
The "stock" fan setup is the blower. The "founders edition" cards are the base reference cards.prophet001 - Wednesday, July 20, 2016 - link
Alrighty then. Thanks for the info.bill44 - Wednesday, July 20, 2016 - link
Where can I find Audio specification, sampling rates etc.? Decoding capabilities?ImSpartacus - Wednesday, July 20, 2016 - link
The timeline is appreciated.tipoo - Wednesday, July 20, 2016 - link
Sounds like a good few weeks here, well doneChaotic42 - Wednesday, July 20, 2016 - link
Thanks for the review. Some things are worth the wait. Turn your phone and computer off and go take a nap. Sounds like you've earned it.zeeBomb - Wednesday, July 20, 2016 - link
An anandtech review takes all the pain away! How am I going to read this casually though? Without all the detailed whachinlmicallitssna1970 - Wednesday, July 20, 2016 - link
Can you please add Cross Fire benchmarks in the RX480 review ?close - Wednesday, July 20, 2016 - link
But where's the GTX 1070/1080 review? Oh wait... Scratch that.blanarahul - Wednesday, July 20, 2016 - link
"this change in the prefetch size is why the memory controller organization of GP104 is 8x32b instead of 4x64b like GM204, as each memory controller can now read and write 64B segments of data via a single memory channel.*Shouldn't it be the opposite?
"Overall when it comes to HDR on NVIDIA’s display controller, not unlike AMD’s Pascal architecture"
What?!!!