The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTPreemption Improved: Fine-Grained Preemption for Time-Critical Tasks
Continuing our discussion thus far on asynchronous compute and concurrency, the Pascal architecture includes another major feature update related to how work is scheduled. For those of you who have caught our earlier coverage of NVIDIA’s Pascal P100 accelerator, then you should already have an idea of what this is, as NVIDIA touted it as an HPC feature as well. I am of course speaking about fine-grained preemption.
Before we start, in writing this article I spent some time mulling over how to best approach the subject of fine-grained preemption, and ultimately I’m choosing to pursue it on its own page, and not on the same page as concurrency. Why? Well although it is an async compute feature – and it’s a good way to get time-critical independent tasks started right away – its purpose isn’t to improve concurrency.
Asynchronous compute is in a sense a catch-all term, as the asynchronous execution of tasks has a number of different uses. But for consumer products, it’s important to make a distinction between those features that improve concurrency and allow a GPU to get more work done – which is the best understood feature of asynchronous compute – and other features that make more novel use of async. Fine-grained preemption is distinctly in the latter category.
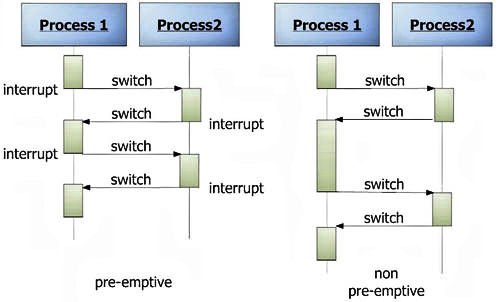
So what is preemption then? In a nutshell, it’s the ability to interrupt an active task (context switch) on a processor and replace it with another task, with the further ability to later resume where you left off. Historically this is a concept that’s more important for CPUs than GPUs, especially back in the age of single core CPUs, as preemption was part of how single core CPUs managed to multitask in a responsive manner. GPUs, for their part, have supported context switching and basic preemption as well for quite some time, however until the last few years it has not been a priority, as GPUs are meant to maximize throughput in part by rarely switching tasks.
(Robert Berger/EE Times: Getting real (time) about embedded GNU/Linux)
Preemption in turn is defined by granularity; how quickly a processor can actually context switch. This ranges from coarse grained-context switching, which is essentially only being able to context switch at certain points in execution, out to fine-grained context switching that allows for an almost immediate switch at any point in time. What’s new for Pascal then is that preemptive context switching just got a lot finer grained, especially for compute.
Diving deeper, to understand what NVIDIA has done, let’s talk about prior generation architectures. Previously, with Maxwell 2 and older architectures, NVIDIA only offered very coarse grained preemption. For graphics tasks or mixed graphics/compute tasks, NVIDIA could only preempt at the boundary of draw calls – collections of triangles and other draw commands, potentially encompassing dozens of polygons and hundreds (if not thousands) of pixels and threads.

Preemption Circa Maxwell 2
The great thing about preempting at a draw call boundary is that it’s relatively clean, as draw calls are a very large and isolated unit of work. The problem with preempting at a draw call boundary is that draw calls are a very large unit of work; just because you call for the preemption doesn’t mean you’re going to get it any time soon. This analogy extends over to the compute side as well, as whole blocks of threads needed to be completed before a preemption could take place.
In fact it’s probably the compute side that’s a better real-world example of the problem with coarse-grained preemption. If you’ve ever run a GPU compute program and had your display driver reboot due to Timeout Detection and Recovery (TDR), then you’ve experienced coarse-grained preemption. For end-user responsiveness and quality purposes, Windows will reset a GPU if it doesn’t respond for more than around 2 seconds. With coarse-grained preemption, it is possible to schedule a compute task that takes so long to run that a block can’t complete in time for the Windows check-in, triggering the TDR reset. Consequently, there is good reason to support finer grained preemption for both graphics and compute tasks.
This in turn is where Pascal steps in. Along with the aforementioned improvements to how Pascal can fill up its execution pipelines, Pascal also implements a radically improved preemption ability. Depending on whether it’s a graphics or a pure compute task, Pascal can now preempt at the thread level or even the instruction level respectively.
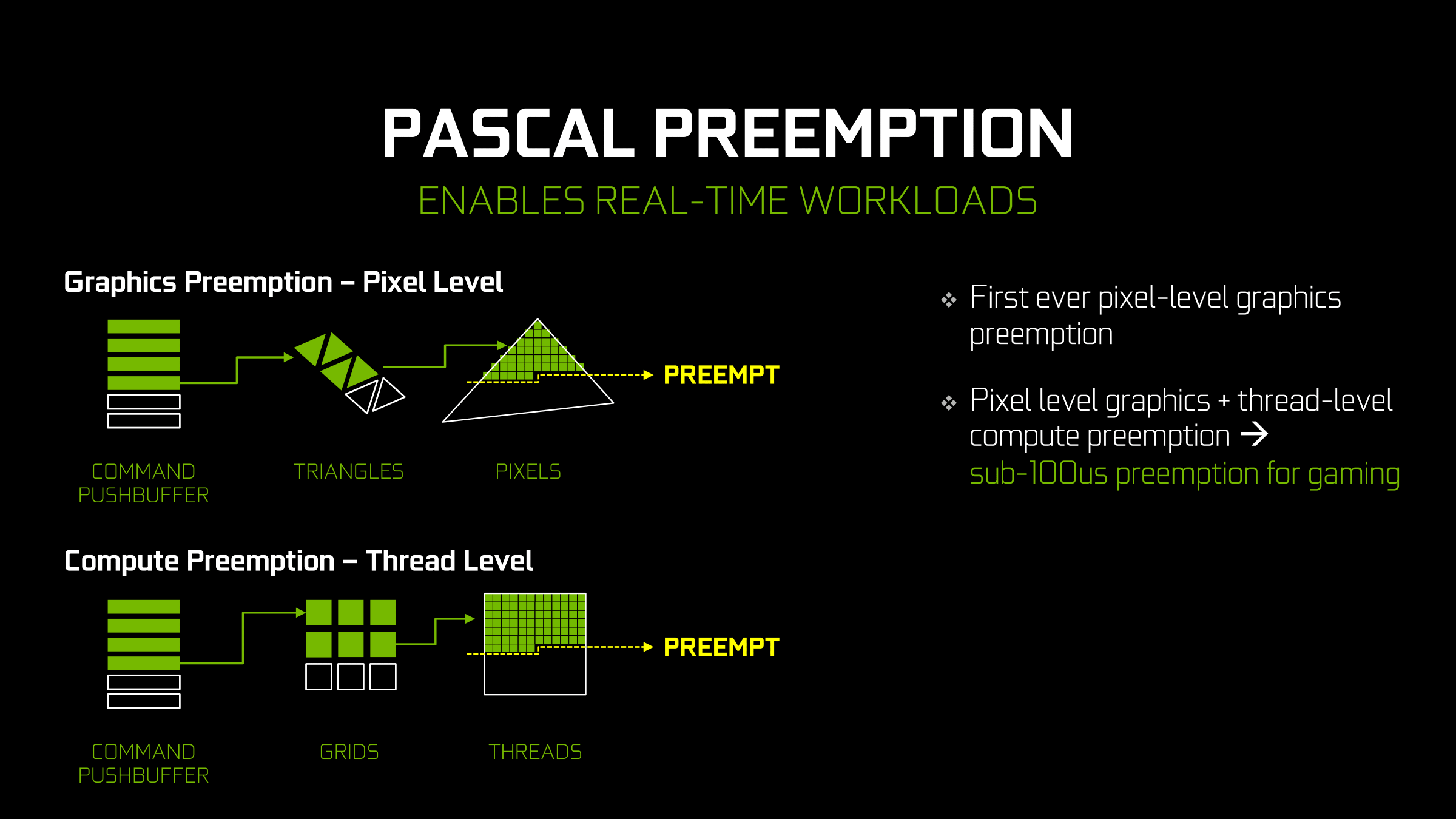
Starting with the case of a graphics task or a mixed graphics + compute task, Pascal can now interrupt at the thread level. For a compute workload this is fairly self-explanatory. Meanwhile for a graphics workload the idea is very similar. Though we’re accustomed to working with pixels as the fundamental unit in a graphics workload, under the hood the pixel is just another thread. As a result the ability to preempt at a thread has very similar consequences for both a graphics workload and the compute threads mixed in with a graphics workload.
With Maxwell 2 and earlier architectures, the GPU would need to complete the whole draw call before preempting. However now with Pascal it can preempt at the pixel level within a triangle, within a draw call. When a preemption request is received, Pascal will stop rasterizing new pixels, let the currently rastered pixels finish going through the CUDA cores, and finally initiate the context switch once the above is done. NVIDIA likes to call this “Pixel Level Preemption.”
In terms of absolute time the benefit of course varies from game to game, and also a bit of luck depending on where in the draw call you are when the preemption request is made. But in general, draw call size and complexity has been going up over the years due to a combination of CPU limits (draw calls are expensive under DX11/OpenGL, which is why we have DX12/Vulkan) and the fact that pixel shaders continue to get longer, consequently taking more time for a given pixel/thread to fully execute. But in the end, the result is that Pascal can now execute a preemptive context switch for graphics much more rapidly than Maxwell 2 could.
Meanwhile in a pure compute scenario (i.e. running a CUDA program) Pascal takes things one step further. Not satisfied with preempting at the thread level, Pascal can actually preempt at the lowest level of them all, the instruction level. This means preempting a thread mid-flow, before the next instruction begins. The thread doesn’t even need to reach completion; with instruction level preemption, the thread can be pulled virtually immediately, Vaudeville Hook style.
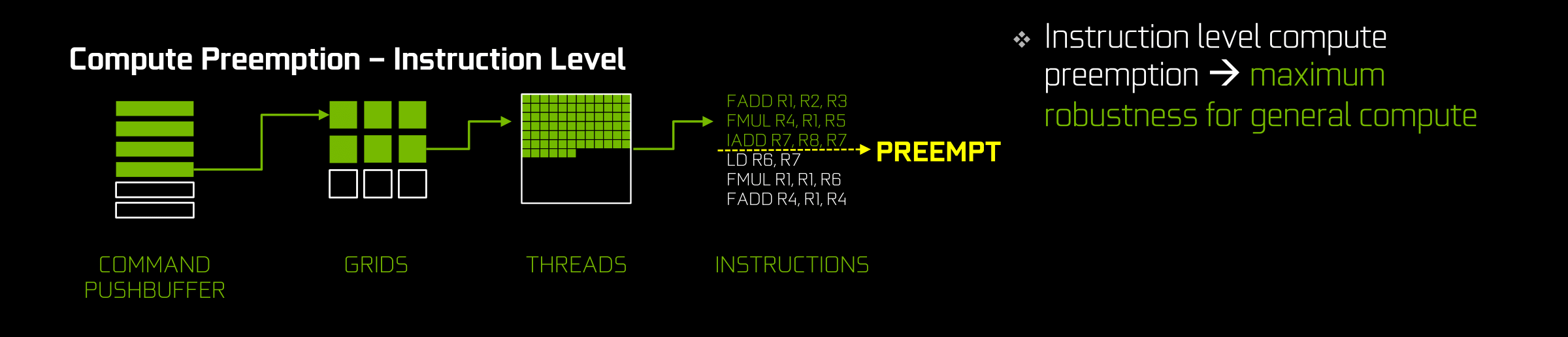
This kind of fine-grained preemption is the most powerful, but it’s also primarily on the GPU for compute purposes. The greatest significance to consumers is allowing CUDA compute applications to run without triggering the TDR watchdog, as now they can stop on the spot and let the watchdog complete its work. This, not-so-coincidentally, has been one of Microsoft’s long-term goals with WDDM development, as they’ve been pushing GPU vendors to support finer-grained preemption for this very reason. Though more broadly speaking, NVIDIA’s plans are greater than just WDDM and the TDR watchdog, such as allowing functionality like interactive debugging of CUDA programs on a single-GPU system (previously they were greater limitations and you’d often need multiple GPUs).
The trade-off for finer-grained preemption is that the deeper you go – the more “in the middle of things” you allow the interruption – the more work it is to context switch. Preempting at the draw call level involves very little state information, preempting at the thread level involves a fair bit of state, and preempting at the instruction level involves a massive amount of state, including the full contents of the L1 caches and the register files. In the case of the latter you’re looking at a minimum of several megabytes of state information that have to be recorded and sent to VRAM for storage. So finer-grained preemption is a very big deal at the implementation level, requiring new hardware to load and save states quickly, and then get it off to VRAM without skipping a beat.
The actual time cost for preemption varies with the workload, but at the most basic level, when the GPU is ready to execute the context switch, NVIDIA tells us that it can be done in under 100us (0.1ms), or about 170,000 clock cycles. Relative to the GPU this is not an insignificant amount of time, and while it’s much faster than the total context switch time from Maxwell 2, it does mean that context switching is still a somewhat expensive operation (roughly 50-100x more so than on a modern Intel CPU). So context switching still needs to be used intelligently, and, for best performance, infrequently.
Meanwhile I’ll quickly note that while the current Pascal drivers only implement thread/pixel level preemption for graphics and mixed workloads, as you might suspect from Pascal’s instruction level preemption capabilities for compute, this is something of an arbitrary decision. Because instruction level preemption is a fundamental Pascal ability, it could be made to do so for graphics as well as compute. The reason why NVIDIA has gone this route is one of cost/benefit tradeoffs; the DirectX team doesn’t believe that preemption at this level is necessary for graphics, in part because pixel shaders aren’t prone to long loops like dedicated compute kernels are, so the next thread boundary will come up relatively quickly. And preempting at the thread boundary is easier (i.e. there’s less state) than at the instruction level. This is something that NVIDIA could theoretically change course on in the future, but at least for now the belief is that the need/demand for such fine-grained preemption in a graphics context isn’t there.
Finally, speaking of graphics, let’s talk about what pixel/thread level preemption is going to be used for. Overall there aren’t too many cases where you want to context switch in the middle of a graphics task, but there is one case that NVIDIA considers very important: asynchronous time warp. We’ve covered asynchronous time warp before, so I won’t fully rehash it here, but in short it’s a neat hack for VR where the frame being prepared for a headset is warped at the last possible moment, using up-to-the-millisecond positioning data, in order to give the illusion that the frame is newer than it actually is. The benefit is that it reduces the perceived input lag of VR, which is one of the causes of simulator sickness.
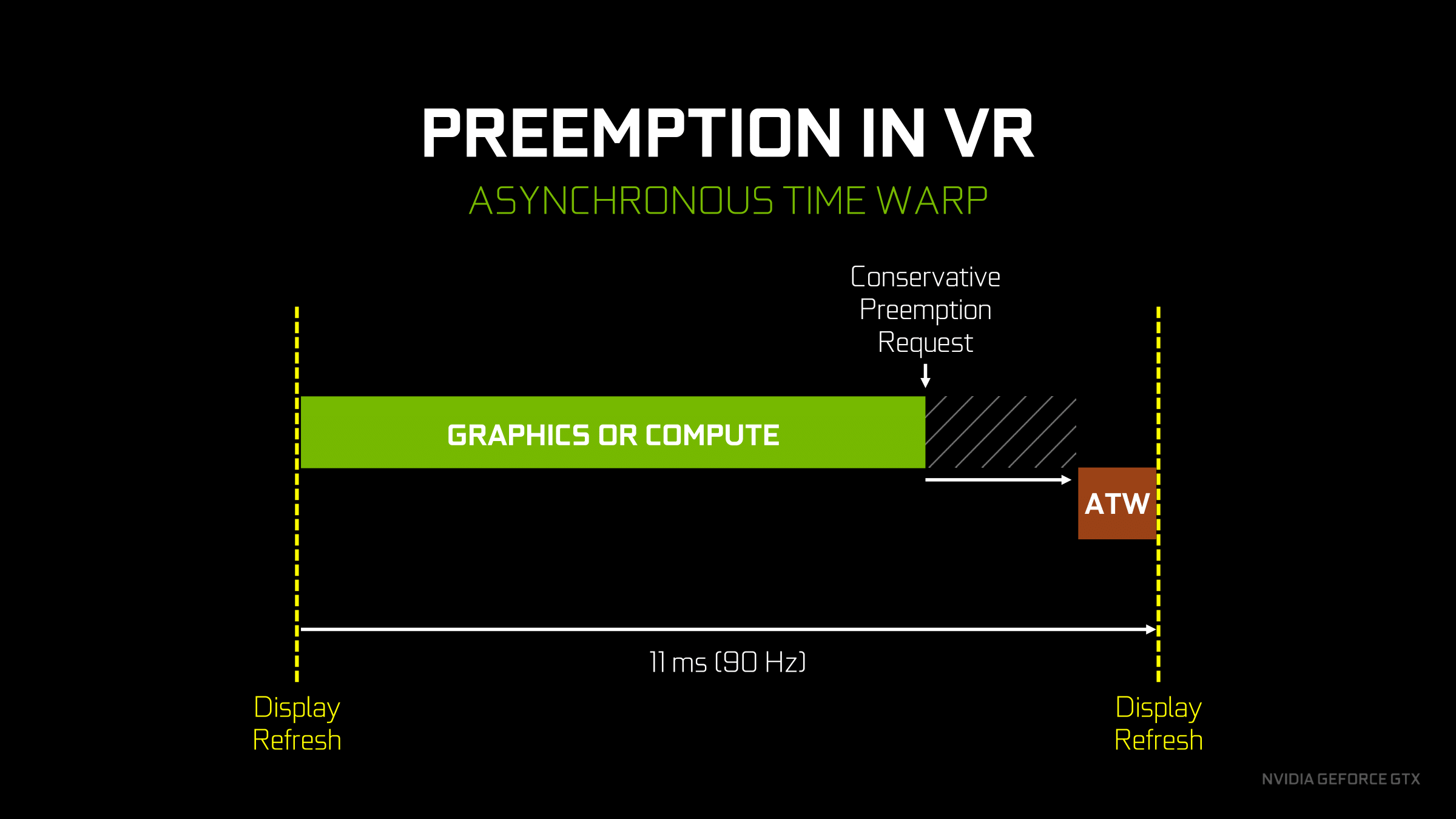
NVIDIA has supported async time warp since Oculus enabled the feature in their SDK, however given the above limitations of Maxwell 2, the architecture wasn’t able to execute an async time warp very efficiently. Assuming there weren’t any free SMs to work on a time warp right away, the need to wait until the end of a draw call meant that it could potentially be a relatively large amount of time until the context switch took place. This required the software stack to be relatively conservative with the preemption call, making the call early in order to ensure that the time warp could execute before it’s too late.
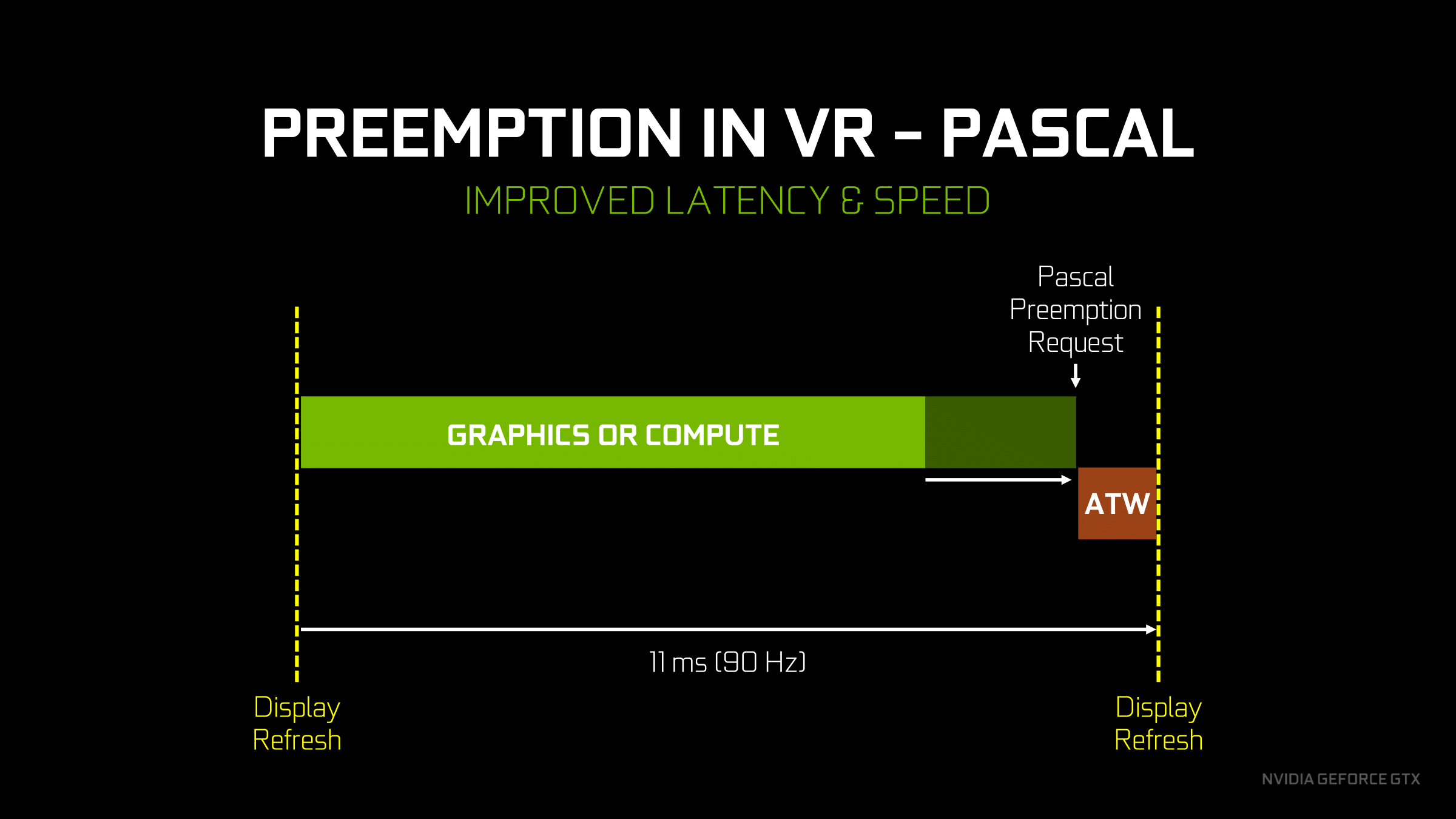
With Pascal’s much improved preemption capabilities, this significantly changes how conservative async time warp needs to be. Pascal’s finer-grained preemption means that the preemption request can come much later. The benefit is that this both better ensures that the async time warp actually occurs in time – there’s virtually no chance of a thread taking too long to finish – and it means that much less GPU time is wasted from the GPU idling due to the conservative preemption request. The end result is that the performance impact of async time warp is reduced on Pascal as compared to Maxwell 2, allowing the GPU to spend more time in every refresh interval doing productive work.
All of that said, I don’t have a good feel for the benefit in terms of numbers; like so many other cases it’s going to depend on the specific game in use, and for that matter how well the game is saturating the GPU given the fixed 90Hz update interval. And though this puts Maxwell 2 in a lesser light, at least so far I haven’t personally noticed Maxwell 2 struggling to execute an async time warp. That Maxwell 2 does as well as it does is likely a testament to the viability of conservative preemption requests, which is to say that it will be interesting if we ever get a chance to see just how much performance Maxwell 2 had to leave on the table to reliably execute async time warps.








200 Comments
View All Comments
Ryan Smith - Friday, July 22, 2016 - link
2) I suspect the v-sync comparison is a 3 deep buffer at a very high framerate.lagittaja - Sunday, July 24, 2016 - link
1) It is a big part of it. Remember how bad 20nm was?The leakage was really high so Nvidia/AMD decided to skip it. FinFET's helped reduce the leakage for the "14/16"nm node.
That's apples to oranges. CPU's are already 3-4Ghz out of the box.
RX480 isn't showing it because the 14nm LPP node is a lemon for GPU's.
You know what's the optimal frequency for Polaris 10? 1Ghz. After that the required voltage shoots up.
You know, LPP where the LP stands for Low Power. Great for SoC's but GPU's? Not so much.
"But the SoC's clock higher than 2Ghz blabla". Yeah, well a) that's the CPU and b) it's freaking tiny.
How are we getting 2Ghz+ frequencies with Pascal which so closely resembles Maxwell?
Because of the smaller manufacturing node. How's that possible? It's because of FinFET's which reduced the leakage of the 20nm node.
Why couldn't we have higher clockspeeds without FinFET's at 28nm? Because power.
28nm GPU's capped around the 1.2-1.4Ghz mark.
20nm was no go, too high leakage current.
16nm gives you FinFET's which reduced the leakage current dramatically.
What does that enable you to do? Increase the clockspeed..
Here's a good article
http://www.anandtech.com/show/8223/an-introduction...
lagittaja - Sunday, July 24, 2016 - link
As an addition to the RX 480 / Polaris 10 clockspeedGCN2-GCN4 VDD vs Fmax at avg ASIC
http://i.imgur.com/Hdgkv0F.png
timchen - Thursday, July 21, 2016 - link
Another question is about boost 3.0: given that we see 150-200 Mhz gpu offset very common across boards, wouldn't it be beneficial to undervolt (i.e. disallow the highest voltage bins corresponding to this extra 150-200 Mhz) and offset at the same time to maintain performance at lower power consumption? Why did Nvidia not do this in the first place? (This is coming from reading Tom's saying that 1060 can be a 60w card having 80% of its performance...)AnnonymousCoward - Thursday, July 21, 2016 - link
NVIDIA, get with the program and support VESA Adaptive-Sync already!!! When your $700 card can't support the VESA standard that's in my monitor, and as a result I have to live with more lag and lower framerate, something is seriously wrong. And why wouldn't you want to make your product more flexible?? I'm looking squarely at you, Tom Petersen. Don't get hung up on your G-sync patent and support VESA!AnnonymousCoward - Thursday, July 21, 2016 - link
If the stock cards reach the 83C throttle point, I don't see what benefit an OC gives (won't you just reach that sooner?). It seems like raising the TDP or under-voltaging would boost continuous performance. Your thoughts?modeless - Friday, July 22, 2016 - link
Thanks for the in depth FP16 section! I've been looking forward to the full review. I have to say this is puzzling. Why put it on there at all? Emulation would be faster. But anyway, NVIDIA announced a new Titan X just now! Does this one have FP16 for $1200? Instant buy for me if so.Ryan Smith - Friday, July 22, 2016 - link
Emulation would be faster, but it would not be the same as running it on a real FP16x2 unit. It's the same purpose as FP64 units: for binary compatibility so that developers can write and debug Tesla applications on their GeForce GPU.hoohoo - Friday, July 22, 2016 - link
Excellent article, Ryan, thank you!Especially the info on preemption and async/scheduling.
I expected the preemption mght be expensive in some circumstances, but I didn't quite expect it to push the L2 cache though! Still this is a marked improvement for nVidia.
hoohoo - Friday, July 22, 2016 - link
It seems like the preemption is implemented in the driver though? Are there actual h/w instructions to as it were "swap stack pointer", "push LDT", "swap instruction pointer"?