The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
Memory Subsystem: Bandwidth
For this review we completely overhauled our testing of John McCalpin's Stream bandwidth benchmark. We compiled the stream 5.10 source code with the Intel compiler for linux version 16 or gcc 4.8.4, both 64 bit. The following compiler switches were used on icc:
-fast -openmp -parallel
The results are expressed in GB per second. The following compiler switches were used on gcc:
-O3 –fopenmp –static
Stream allows us to estimate the maximum performance increase that DDR-2400 (Xeon E5 v4) can offer over DDR-2133 (Xeon E5 v3).
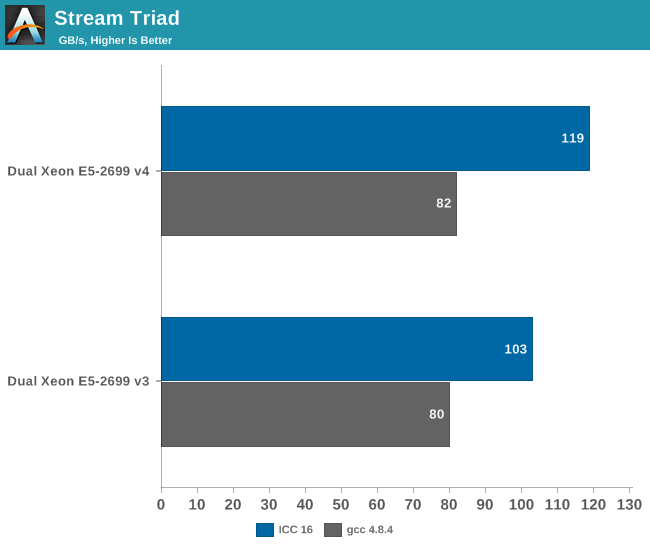
The Xeon E5 v4 with DDR4-2400 delivers about 15% higher performance then the v3 when we compile Stream with icc. To put this into perspective: DDR-4 @ 1600 delivered 80 GB/s.
The difference between DDR-4 2400 and DDR-4 2133 is negligible with gcc.
Memory Subsystem: Latency
To measure latency, we use the open source TinyMemBench benchmark. The source was compiled for x86 with gcc 4.8.2 and optimization was set to "-O2". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests.
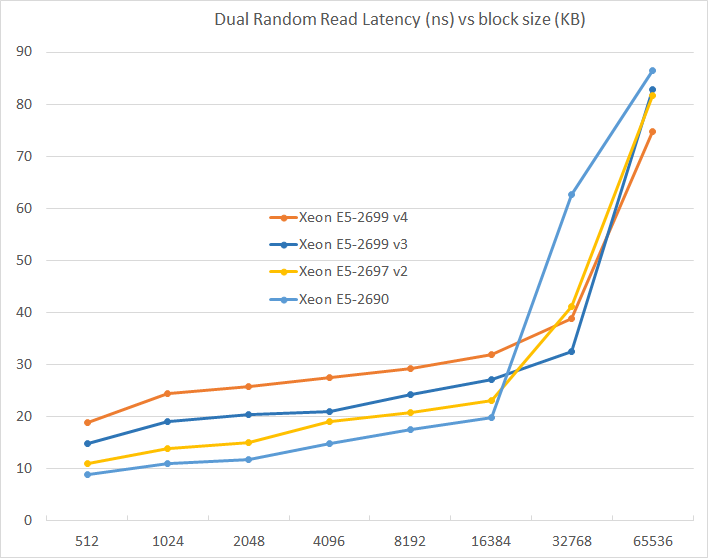
The larger the L3 caches get, the higher the latency. Latency has almost doubled from the Xeon E5 v1 to the Xeon E5 v4 while capacity has almost tripled (55 MB vs 20 MB). Still, this will result in a small performance hit in many non-virtualized applications that do no need such a large L3.








112 Comments
View All Comments
JohanAnandtech - Saturday, April 2, 2016 - link
Ok, thanks, time to sleep a little longer. I have fixed the error.xrror - Friday, April 1, 2016 - link
It's depressing to see the mobile-first design philosophy really gutting into the last bastion of x86 performance.I mean I get it - a 22 (20) core xeon wouldn't even exist without the aggressive power management tech needed to keep it from melting or needing exotic cooling. But it's still depressing to see ALL of the arch improvements immediately negated with lowered clock speeds, or worse "turbo speeds" you will never actually see once the machine is running production loads.
The engineering behind these big core count chips though is always very impressive. Also did Intel ever say how they "fixed" TSX?
FunBunny2 - Friday, April 1, 2016 - link
"It's depressing to see the mobile-first design philosophy really gutting into the last bastion of x86 performance."welcome to the world of laissez faire capitalism: do what makes the most money today, irregardless of future consequences. used to be, Intel could rely on M$ making the next versions of Windoze and Office impossible to run on existing Pentiums, thus driving sales of the next Pentium (a whole machine, at that). these days it's up to gamers and data centres. not taking any bets on which turns out to be in the driver's seat.
xrror - Friday, April 1, 2016 - link
Well, considering that "computer gaming" has degraded to whatever the kids are running on their smartphones, or the parent's tablet I'm not hopeful for any new resurgence in demand for high performance PC's in the mass market.So the future consequences for Intel prioritizing power efficiency over performance, or possibly developing a separate fabrication tech for performance is... likely not very much. So there really is no "future consequence" for Intel. Sure they could go out and actually try and make a 10Ghz 9nm part possible, but nobody in 2020 would buy it because... it probably would go into whatever iDevice they care about. And HPC market I dunno. Maybe if it datamines marketing data faster or can microtrade on the stock market faster or something. meh.
The general public really doesn't care about performance anymore (honestly, they may never have), only how portable it is and if a device is good enough to run their stuff on the go.
The high end market like these multi-core xeons though, is strange because you'd think this is where Intel would go all in, but I guess when your only competitors are IBM Power and (currently non-competitive) AMD I dunno...
I mean it's sad, even Intel has to beg to justify it's R&D expenses to shareholders - which is stupid because Intel's R&D is one of it's biggest strengths. But such as it is. Apr 1 rant over ;)
abufrejoval - Friday, April 1, 2016 - link
Johan, you keep bemoaning the fact that lack of competition seems to stop "real progress" and I wonder where you expect that progress to happen.More specifically you seem to desire more GHz and I can understand that desire, which may originate from that crazy 40MHz to 4GHz rush we all experienced somewhere in the decade starting in the mid nineties.
I understand the emotion, but I wonder how it fits the scientific mind I see everywhere else in your work, because 8, 16 or 32 GHz is simply not going to happen, competition or not.
Sure 8GHz are possible, you can even purchase 5GHz off the shelves. But it simply doesn't deliver in terms of Oomp/$. And Web Scale is all about value/€ and the main driver of server evolution today.
We'll still see radical speedups where it counts, but it will have to be via special purpose function blocks either on SoCs, or by adding a couple of extra instructions or by doing something as radical as Micron's Automata Processor.
But general purpose von Neumann has hit the Gigahertz wall years ago and nothing can change that except a different model of compute.
I liked the reference to Andreas Stiller, but I'm not sure everybody here has a subscription to c't like I do since the early 1990's. There could also be the tiny issue that not everyone outside Belgium is quadrilingual.
Make no mistake: I love your work! It's a pleasure to read for form, style and the content!
The Von Matrices - Saturday, April 2, 2016 - link
Any indication of the QPI speed of these chips? Did Intel increase it from the 9.6 GT/s in Haswell-EP?Ian Cutress - Saturday, April 2, 2016 - link
Most of the high end are 9.6 GT/s. https://twitter.com/IanCutress/status/715582714099...watersb - Saturday, April 2, 2016 - link
Johan, this is fantastic work. Thanks very much.Any way to address RAS features?
isrv - Saturday, April 2, 2016 - link
well, i'm completely dissapointed.web servers wants higher clock speed.
single-thread load (like PHP) become even slower on those E5v4 due to drop in GHz's.
still, the best CPU's for that is E3-1290v2, E3-1281v3 (and 1286v3), E3-1280v5, E5-1630v3, E5-1620v2 and the only one 6-core E5-1660v2
all those are 3.7Ghz (pointless to look at turbo speed since we're under constant 24/7 load).
i was hoping to at least one 3.8GHz or even higher.
so no changes here, E5-1660v2 is still the fastest web-server CPU.
or E5-1630v3 by sacrificing 2 cores for a bit faster memory.
patrickjp93 - Sunday, April 3, 2016 - link
For those 4-8 core chips, the turbo boost is maintainable for 24/7 workloads if your cooling is sufficient. You seem to know far less about this environment than you let on. And who the hell still uses single-threaded PHP? And you're not taking into account better caching algorithms and other architectural improvements that make the 200MHz slower V4 run faster than your V2.