The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
A Modest Tick
As Broadwell is a tick - a die shrink of an existing architecture, rather than a new architecture - so you should expect modest IPC improvements. Most Xeon E5 v4 SKUs have slightly lower clockspeeds compared to their Haswell v3 brethren, so overall the single threaded performance has hardly improved. Clock for clock, Intel tells us that their simulation tools show that Broadwell delivers about 5% better performance per clock in non-AVX2 traces.
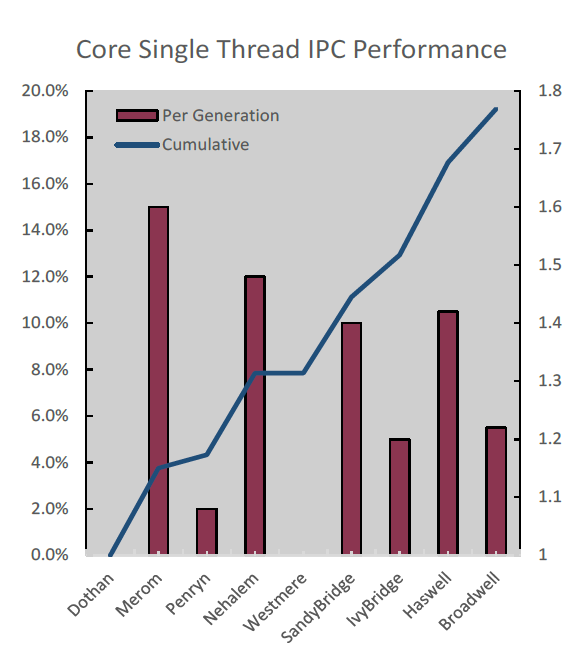
First Y-axis + bars: simulated single threaded performance improvement. Blue line + second Y-axis is the cumulative improvement.
In that sense, Broadwell is basically a Haswell made on Intel's 14nm second generation tri-gate transistor process. Intel did make a few subtle improvements to the micro-architecture:
- Faster divider: lower latency & higher throughput
- AVX multiply latency has decreased from 5 to 3
- Bigger TLB (1.5k vs 1k entries)
- Slightly improved branch prediction (as always)
- Larger scheduler (64 vs 60)
None of these improvements will yield large performance improvements. The larger improvements must come from other features.
New Features
Compared to Haswell-EP, Broadwell-EP also includes some new features. The first one is the improved power control unit.
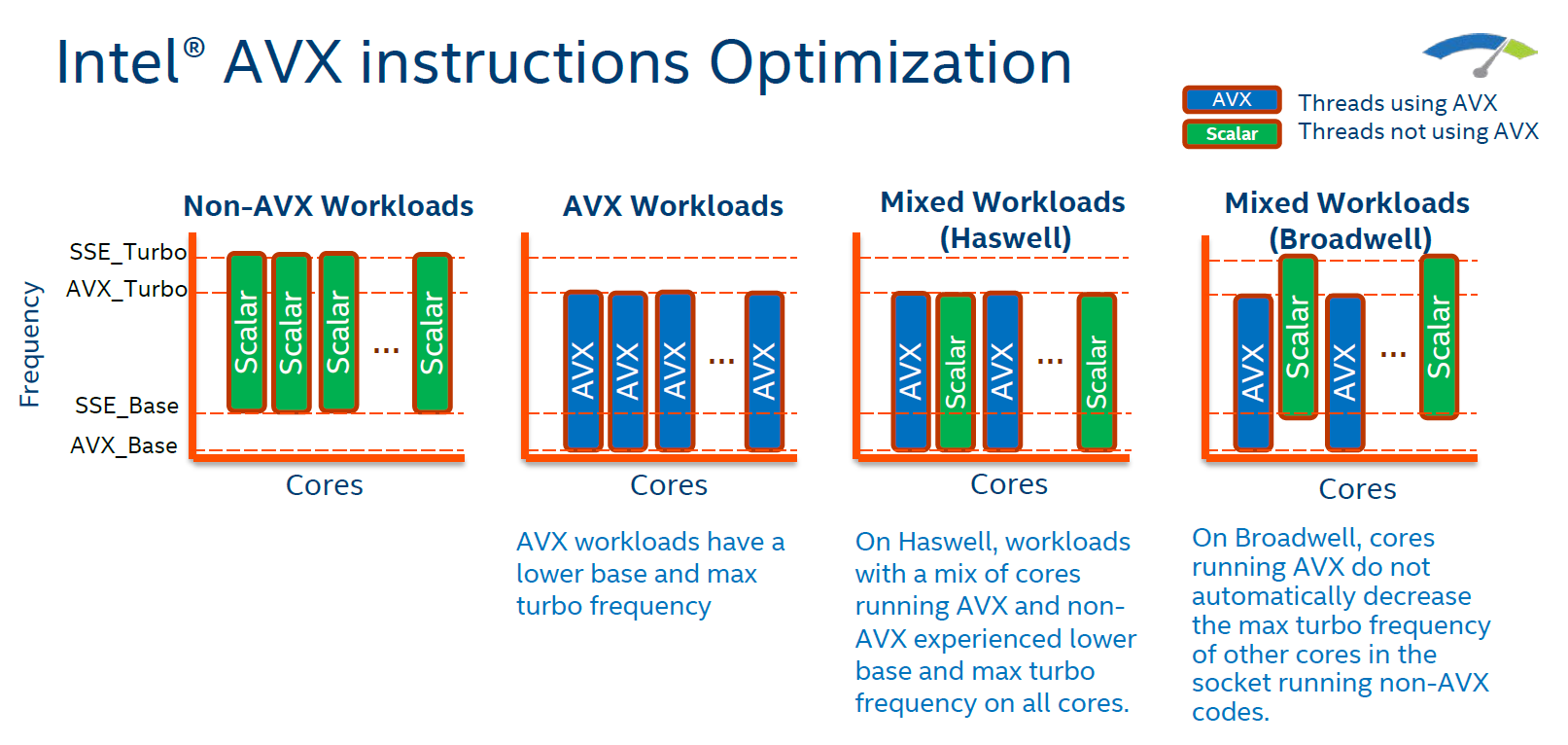
On Haswell, one AVX instruction on one core forced all cores on the same socket to slow down their clockspeed by around 2 to 4 speed bins (-200,-400 MHz) for at least 1 ms, as AVX has a higher power requirement that reduces how much a CPU can turbo. On Broadwell, only the cores that run AVX code will be reducing their clockspeed, allowing the other cores to run at higher speeds.
The other performance feature is the vastly improved PCLMULQDQ (carry-less multiplication) instruction: throughput has been doubled, and latency reduced from 7 cycles to 5.

This increases AES (symmetric) encryption performance by 20-25%, and CRCs (Cyclic Redundancy check) are up to 90% faster. Broadwell also has some new ADCX/ADOX instructions to speed up asymmetric encryption algorithms such as the popular RSA. These improvements are implemented in OpenSSL 1.0.2-beta3. But don't expect too much from it.. The compute intensive asymetric encryption is mostly used to initiate a secure connection. Most modern web applications keep their sessions "alive", and as a result, events that require asymmetric encryption happen a lot less frequentely . Symmetric encryption (like AES) which is used to send encrypted data is a lot lighter, so even on a fully encrypted website with long encrypted data streams, encryption is only a small percentage (<5%) of the total computing load.








112 Comments
View All Comments
petar_b - Saturday, August 27, 2016 - link
Thanks Phil_Oracle, Brutalizer and Anand for this discussion. I have learned a lot from reading different opinions. I am working with IBM and Oracle software products, and from my small experience, Xeons are pathetic when compared to POWER or SPARC. To do same operation at home Xeon it takes 10x more time than what it takes the corporate server to do. I have double memory than corporate server and yet no help from it.someonesomewherelse - Thursday, September 1, 2016 - link
Btw how locked down are these Xeons and their motherboards in regards to overclocking? Assuming you could provide enough power and cooling could you reach a decent overclock? Obviously nobody is going to do that for mission crittical servers/workstations, but if I had too much money could I get a quad or octa core system with as much cores possible and at least try to overclock them?