The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
A Modest Tick
As Broadwell is a tick - a die shrink of an existing architecture, rather than a new architecture - so you should expect modest IPC improvements. Most Xeon E5 v4 SKUs have slightly lower clockspeeds compared to their Haswell v3 brethren, so overall the single threaded performance has hardly improved. Clock for clock, Intel tells us that their simulation tools show that Broadwell delivers about 5% better performance per clock in non-AVX2 traces.
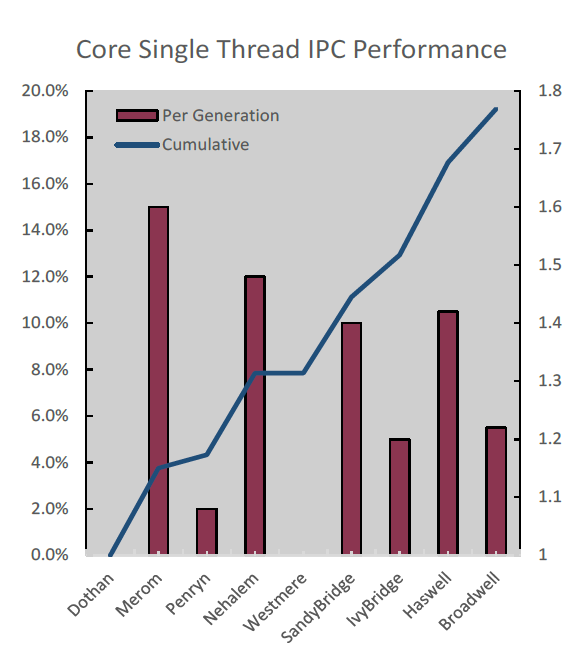
First Y-axis + bars: simulated single threaded performance improvement. Blue line + second Y-axis is the cumulative improvement.
In that sense, Broadwell is basically a Haswell made on Intel's 14nm second generation tri-gate transistor process. Intel did make a few subtle improvements to the micro-architecture:
- Faster divider: lower latency & higher throughput
- AVX multiply latency has decreased from 5 to 3
- Bigger TLB (1.5k vs 1k entries)
- Slightly improved branch prediction (as always)
- Larger scheduler (64 vs 60)
None of these improvements will yield large performance improvements. The larger improvements must come from other features.
New Features
Compared to Haswell-EP, Broadwell-EP also includes some new features. The first one is the improved power control unit.
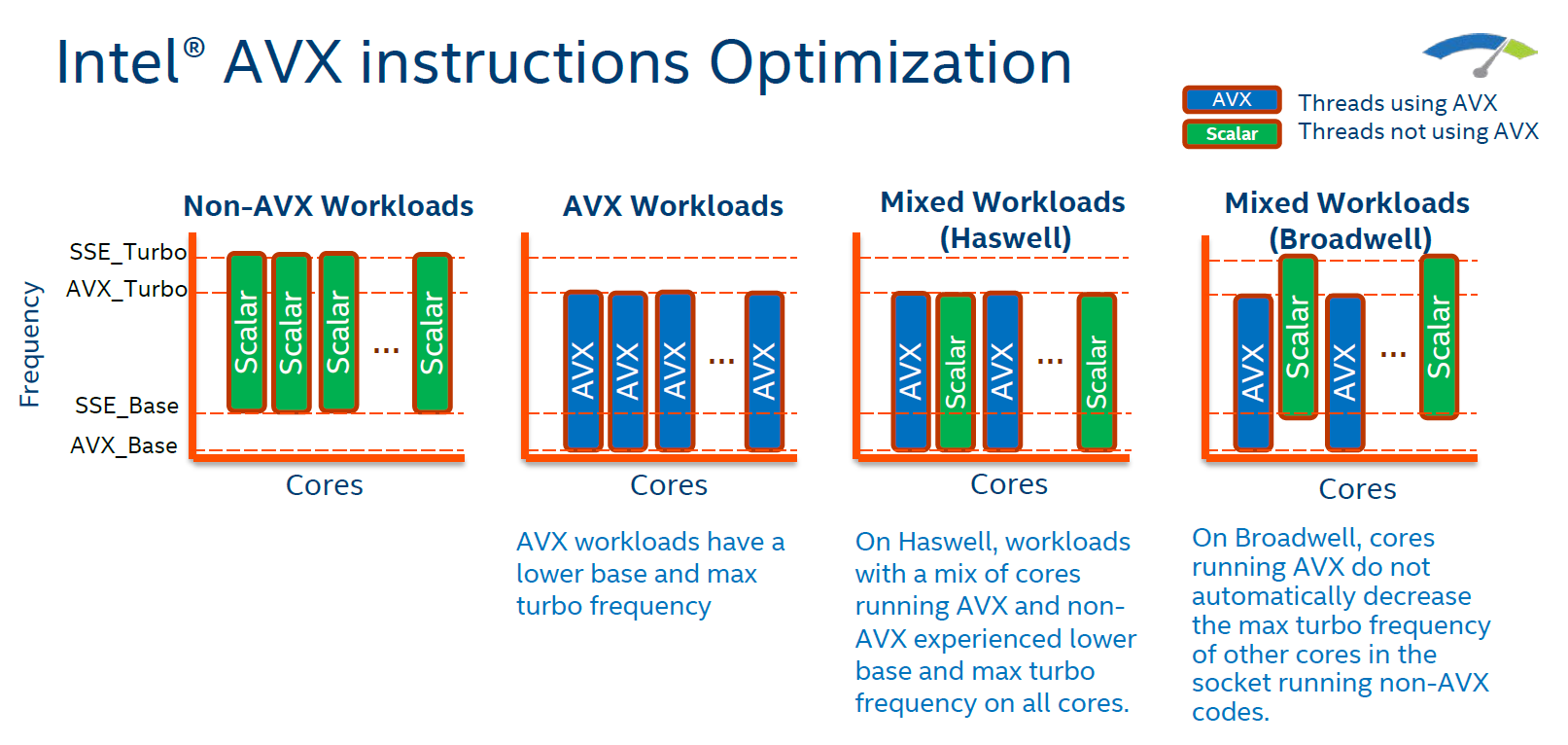
On Haswell, one AVX instruction on one core forced all cores on the same socket to slow down their clockspeed by around 2 to 4 speed bins (-200,-400 MHz) for at least 1 ms, as AVX has a higher power requirement that reduces how much a CPU can turbo. On Broadwell, only the cores that run AVX code will be reducing their clockspeed, allowing the other cores to run at higher speeds.
The other performance feature is the vastly improved PCLMULQDQ (carry-less multiplication) instruction: throughput has been doubled, and latency reduced from 7 cycles to 5.

This increases AES (symmetric) encryption performance by 20-25%, and CRCs (Cyclic Redundancy check) are up to 90% faster. Broadwell also has some new ADCX/ADOX instructions to speed up asymmetric encryption algorithms such as the popular RSA. These improvements are implemented in OpenSSL 1.0.2-beta3. But don't expect too much from it.. The compute intensive asymetric encryption is mostly used to initiate a secure connection. Most modern web applications keep their sessions "alive", and as a result, events that require asymmetric encryption happen a lot less frequentely . Symmetric encryption (like AES) which is used to send encrypted data is a lot lighter, so even on a fully encrypted website with long encrypted data streams, encryption is only a small percentage (<5%) of the total computing load.








112 Comments
View All Comments
isrv - Sunday, April 3, 2016 - link
i will belive that only after one by one comparison E5-1630v3 vs any of E5v4 composing wordpress front page for example.and so far, that's only a words about better caching etc...
simplyfabio - Monday, April 4, 2016 - link
Could I ask one thing here? For a Workstation 3D, both for rendering and graphic/cad, (like illustrator, photoshop, autocad, 3dsmax), could be better have more core like the E5 2690 (considering all the turbo clock speed for each core active) ore better frequency, like the 1680? Thanks a lot to everyone, I can't find a nice review on this side of this CPUs...grantdesrosiers - Monday, April 4, 2016 - link
Not sure if anyone has pointed it out yet, but I think there is an error on the "Multi-Threaded Integer Performance" page, first graph. The 2695v4 says 22 cores, I believe it should be 18.SanX - Monday, April 4, 2016 - link
Poor Moore's law for workstations... 10-20% gain per 2-years generation.Think about it: there is no reason to upgrade for the next *** 5-10 generations *** or the next 10-20 years (!!!) when the processors will be only e-fold (2.71x) faster.
dragonsqrrl - Monday, April 4, 2016 - link
The problem is your first assumption is already false.Khenglish - Monday, April 4, 2016 - link
I can't understand why the 4C and under turbo speeds are so slow on the v4 2699. A Broadwell with 55MB of cache being outperformed by a stock clocked Sandy Bridge is ridiculous. Why would this CPU not clock up to at least 4.2GHz with a 4 core workload, and say 4.4GHz for a 1 core workload? Hell it costs over $4000 and a massive TDP. You'd think Intel could take a minute to make the low core count speeds not terribly low.My workstation in my lab has a 1650 v3. My workloads peak between 4-8 cores. There is not a single CPU in the v4 lineup that would be an upgrade over the 1650 v3 despite the major power savings of 14nm and the cache size increase due to Intel's inability to set reasonable 8C and under frequencies.
Romulous - Monday, April 4, 2016 - link
People who are serious about recompiling the same software often would probably use ccache and maybe even distcc. So your Linux kernel compile test is really only there for to show potential cpu performance.LHL2500 - Tuesday, April 5, 2016 - link
"It finds a home in the same LGA 2011-3 socket."Not according to Intel's website.
http://ark.intel.com/compare/91754,81908
In this comparison between a v3 and a v4 version of a E5-2680, the socket support for the two chips are different. The older version using the the FCLGA2011-3 and the newer version using FCLGA2011.
So who is right? Anandtech or Intel?
And it not just this chip. It's all the v4s.
While I hope it's a typo on Intel's behalf, for now it doesn't look like the v4s are direct upgrades to the v3s. You will apparently need new motherboards.
xrror - Tuesday, April 5, 2016 - link
That... is a bit disconcerting. I also like how "VID Voltage Range" for the v4 parts is simply listed as "0" ...SeanJ76 - Tuesday, April 5, 2016 - link
My School had the 3rd Generation Xeon's in their Workstations, they were slow as fuck@3.3ghz!! The consumer i7 4790K/6700K would run laps around these Xeon crap cpus!