Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
Dealing with Guest ISAs and a Translation Layer
Going back to this architecture diagram, everything up to the global front end is another interesting story as well.
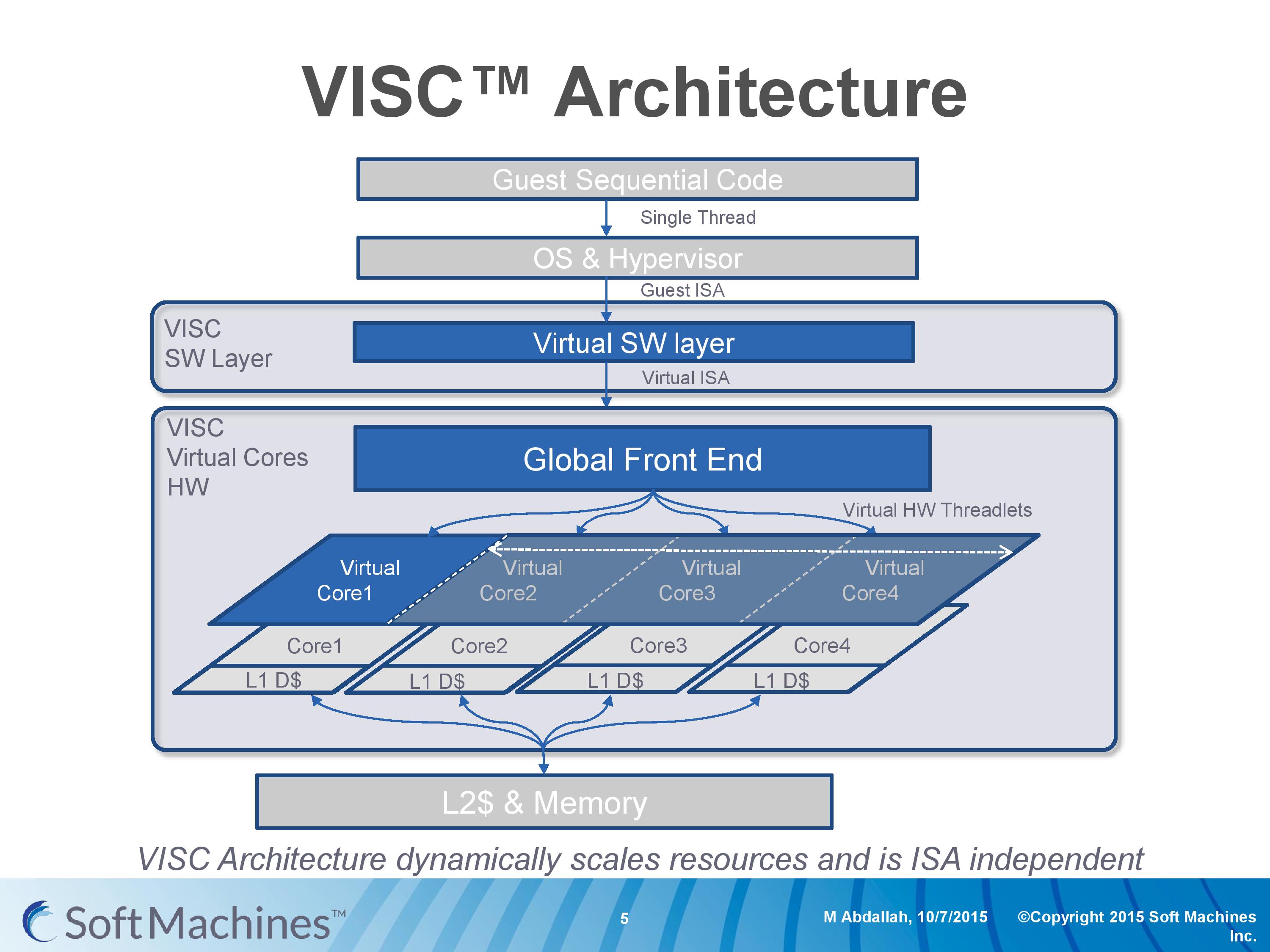
Part of Soft Machines' product package is a low level virtual software layer that will translate a guest instruction set and convert it into the VISC ISA. This is to allow VISC to be used with existing software, and to more easily integrate into current environments rather than trying to establish an ecosystem for a new architecture in 2016. Soft Machines tells us that two instruction sets are supported, one of which will be ARMv8. It was implied that x86 would be the other, although they were reluctant to outright confirm it (ed: x86 translation is likely not to be looked upon fondly by Intel). Meanwhile we were told that writing additional translation layers, while not trivial, can be done and that they plan to support other guest ISAs in future.
So for all intents and purposes, this is a translation layer converting from ARMv8 to VISC. Many companies over the past couple of decades have tried with translation layers – Intel with Itanium, Transmeta to x86, and one of the latest was NVIDIA with Denver, which translated ARM to a custom ISA. Mentioning Itanium, Transmeta and Denver, for those who have followed the industry, might bring a chill down the spine given the very limited success each of these platforms have had. Soft Machines’ CEO was keen to point out that the purpose of the translation layer for VISC is very different to these previous attempts.
The VISC translation layer is designed to be a thin and lean implementation whose main role is to maintain compatibility to the VISC ISA, not to extract performance. Taking Denver as the most recent example, the translation layer there is designed to adjust the ARM instructions into Denver’s ISA and extract instruction level parallelism into the 7-wide design. For VISC, we are told, there is no need to go after performance at this level. The main point at which the VISC design increases performance is at threadlet generation, not in translation and making instruction sequences better fit the VISC hardware. This allows the ARM translation layer to have a less than 5% overhead, according to Soft Machines, and releases a point of contention with previous translation layer designs. As long as the translation layer is 100% compatible, the performance can in principle be extracted at the threadlet level.
This also means, again according to Soft Machines, that any specific compiler enhancement offered by others can also be used when translated. We put it to them that in the case of x86 certain codes are accelerated better on Intel’s compiler than say GCC (a question that arose out of the results we’ll go into later), and we were told that those instruction enhancements by ICC should translate well into the VISC ISA after going through the translation layer.
We asked about the VISC ISA, but were told that more information about this and the core design would be released at a later date as designs progress. We were told that it is a relatively small ISA (as to us sounds like a RISC, which is easier to extract ILP at lower power) with smaller instructions in comparison to ARM and x86. I would assume that this means they are fixed length, but this was not confirmed.








97 Comments
View All Comments
vladx - Sunday, February 14, 2016 - link
If it works, Intel or ARM won't be abke to copy them because they've already patented the techniques used.vladx - Sunday, February 14, 2016 - link
*able tovalinor89 - Saturday, February 13, 2016 - link
AMD, Samsung and Globalfoundries are chief investors so it is doubtful Intel or Nvidia will be able to aquire this company.xthetenth - Friday, February 12, 2016 - link
Why is that such a red flag? They show the optimal part of the curve for A72, and they show the suboptimal tail for all of them, although they extend it farther for the A72 to show what it takes to get it up to the same performance level (basically it's non-viable and that they're in a different class if accurate), and they say as much. There's a huge list of objections the article raises and that isn't on it for pretty good reason. It's just not nearly as big a deal as the rest.Andrei Frumusanu - Friday, February 12, 2016 - link
It's incorrect to simply extend a curve of an existing design beyond its design operating range. It's perfectly possible to design the physical implementation to be optimized at very high frequencies - in such a case the curve would less steep but consume higher power at the low frequencies. Extending the curve of a low-power design is relatively misleading in this case.extide - Friday, February 12, 2016 - link
Yeah, and I don't think they should adjust the Intel cores at all. Intel chips come as Intel makes them, that's it. You will never see the skylake arch on TSMC or GF foundry processes. You should take the results from the Intel chip as they are because that is what you will be competing against, not some made up adjusted result that will never exist in the wild.As for adjusting the OTHER chips, well, ok I see what they are going at here, but I still think they took it a bit too far, like adjusting for more or less cache. Although you can see those other chips on various processes, form GF and TSMC, so the process correction isn't really as big of a red flag to me.
name99 - Saturday, February 13, 2016 - link
The curve is not illegitimate because you're missing the point. The goal of the curve is not to show how great their CPU is, it is to show how great their TECHNOLOGY is (ie their microarchitecture). This is best done by comparisons that hold all else equal (ie same process, same compiler, same caches, etc; only different microarchitecture).If you're going to criticize the presentation, criticize it on grounds that actually make sense:
- their "performance" score is garbage because they claim to be in the business of speeding up SINGLE-THREADED code, but then mix in a number of benchmarks that are very naturally parallelized. This is much like comparing an ARMv8 CPU with NEON switched off to an x86 using AVX-512, to test matrix multiplication speed --- it's simply NOT telling you anything about single-threaded performance.
- the robustness of their normalizations is dodgy and they provide little evidence that the ways in which they have normalized are legit.
gamerk2 - Friday, February 12, 2016 - link
This is where CPUs are eventually going to go, since it's really the only way to get maximized CPU performance without adding a lot of power-hungry components onto the die.That being said, the likely outcome is someone (Intel most likely, possibly NVIDIA) acquires Soft Machines and integrates their IP onto their own chips.
vladx - Sunday, February 14, 2016 - link
Doubt it, the only chance for NVidia would be to license it and Intel would most likely be blocked from nuying such a company.Avendit - Friday, February 12, 2016 - link
How doe this all compare to the Transmetta/Crusoe parts? That had a different purpose but did have the translation abstraction layer approach, but didn't seem to go anywhere unfortunetly. Are there any parallels or learnings to be had?