Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
Dealing with Guest ISAs and a Translation Layer
Going back to this architecture diagram, everything up to the global front end is another interesting story as well.
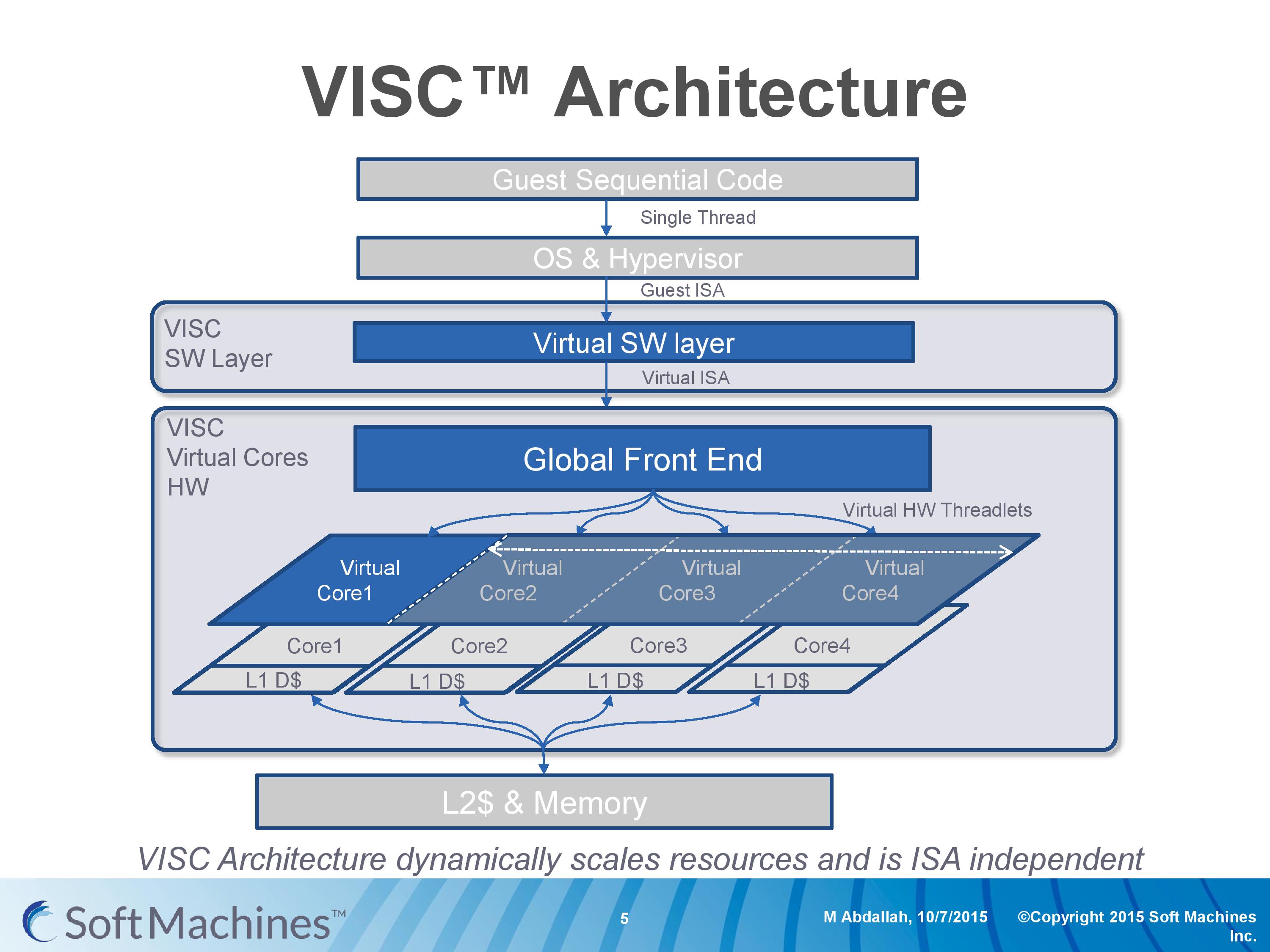
Part of Soft Machines' product package is a low level virtual software layer that will translate a guest instruction set and convert it into the VISC ISA. This is to allow VISC to be used with existing software, and to more easily integrate into current environments rather than trying to establish an ecosystem for a new architecture in 2016. Soft Machines tells us that two instruction sets are supported, one of which will be ARMv8. It was implied that x86 would be the other, although they were reluctant to outright confirm it (ed: x86 translation is likely not to be looked upon fondly by Intel). Meanwhile we were told that writing additional translation layers, while not trivial, can be done and that they plan to support other guest ISAs in future.
So for all intents and purposes, this is a translation layer converting from ARMv8 to VISC. Many companies over the past couple of decades have tried with translation layers – Intel with Itanium, Transmeta to x86, and one of the latest was NVIDIA with Denver, which translated ARM to a custom ISA. Mentioning Itanium, Transmeta and Denver, for those who have followed the industry, might bring a chill down the spine given the very limited success each of these platforms have had. Soft Machines’ CEO was keen to point out that the purpose of the translation layer for VISC is very different to these previous attempts.
The VISC translation layer is designed to be a thin and lean implementation whose main role is to maintain compatibility to the VISC ISA, not to extract performance. Taking Denver as the most recent example, the translation layer there is designed to adjust the ARM instructions into Denver’s ISA and extract instruction level parallelism into the 7-wide design. For VISC, we are told, there is no need to go after performance at this level. The main point at which the VISC design increases performance is at threadlet generation, not in translation and making instruction sequences better fit the VISC hardware. This allows the ARM translation layer to have a less than 5% overhead, according to Soft Machines, and releases a point of contention with previous translation layer designs. As long as the translation layer is 100% compatible, the performance can in principle be extracted at the threadlet level.
This also means, again according to Soft Machines, that any specific compiler enhancement offered by others can also be used when translated. We put it to them that in the case of x86 certain codes are accelerated better on Intel’s compiler than say GCC (a question that arose out of the results we’ll go into later), and we were told that those instruction enhancements by ICC should translate well into the VISC ISA after going through the translation layer.
We asked about the VISC ISA, but were told that more information about this and the core design would be released at a later date as designs progress. We were told that it is a relatively small ISA (as to us sounds like a RISC, which is easier to extract ILP at lower power) with smaller instructions in comparison to ARM and x86. I would assume that this means they are fixed length, but this was not confirmed.








97 Comments
View All Comments
xdrol - Saturday, February 13, 2016 - link
I somehow fail to see why should be scheduling 2 threads to 2 cores of 4-wide pipelines - including overhead from 'in-thread' cross-core communication - should be more effective than a 2-thread 8-wide SMT core (aka Skylake - it's not 6-wide, and SMT is fine-grained, threads don't 'wait' like the article suggests)Alexvrb - Saturday, February 13, 2016 - link
Right! It's like getting the best of narrow and wide designs at the same time. You can go wide or narrow and more/less threads as needed. It'll probably need a lot of OS support to work well. Still, the concept is interesting, and if their translation layer is fast, it could eventually handle legacy well enough.FunBunny2 - Saturday, February 13, 2016 - link
-- You can go wide or narrow and more/less threads as needed.but no known processor (or design algorithm) can create parallelism in serial code. just because a cpu wants to implement ILP to a greater extent than extant processors, it can't make parallel from nothing; it can only discover "hidden" parallel that extant processors are missing. not something I'd bet on.
Alexvrb - Sunday, February 14, 2016 - link
I was talking about the processor itself. The CPU can act like a wide or narrow design on demand. Whether or not a particular piece of code will benefit was not something I was discussing. My point is that where it helps, it can go wider than current designs. Where it doesn't help it can scale back and go narrow, leaving more cores available for other threads.In other words this doesn't displace multi-threading. A single piece of demanding software may still want to run multiple threads concurrently, to indirectly extract more parallel performance - such as a game splitting up AI, physics, audio, rendering, networking, etc into their own threads. I don't think their design eliminates the necessity of doing this sort of thing.
However they can boost average efficiency with a narrow design and lots of cores (similar to mobile ARM designs), without losing performance vs high-power designs (and in some cases gaining performance) because they can act as a wide pipeline by combining cores It's a flexible form of virtual cores that people will tend to just simplify as "reverse HyperThreading".
This is all just in theory of course, their implementation has to prove itself. Not to mention the difficulties they'll face with ISA translation, at least in the near term. If their technology takes off and gets licensed out, there will be ports of modern OS and APIs, and thus apps will be ported to run native (in the case of Windows, cloud compilation would handle the majority of RunTime apps).
Samus - Monday, February 15, 2016 - link
If the translation layer does what they say it does, that is exactly what this processor can do. It can break up serial code for parallel processing. I don't know how, or how efficient, it can do this. To analyze serial code and say ohh, so there's this complex part in the middle and the rest is simple, and send the complex part to one core and the rest to another, and somehow reassemble it after its processed, seems impossible. We have all seen promising tech flop before, Cyrix and Transmetta had some radical ideas for the way x86 worked, in the end neither could trump Intel or AMD.Alexvrb - Monday, February 15, 2016 - link
What he was saying is that some code can NOT be made parallel. They CAN take single threads and break them up, and when it's possible they can find parallel processing opportunities. But some tasks are inherently serial. Neither the programmer, nor the compiler, nor the VISC processor can make inherently serial tasks parallel. For example, if A has to happen before you can work on B.Uh, at least not with a conventional binary architecture. I don't know much about quantum processors.
easp - Friday, February 12, 2016 - link
I think uninformed pundits/press/commenters will miss the limits imposed by Amdahl's law.Its still plausible to me though that this approach will allow more efficient use of silicon and power by allowing better allocation of processor resources at runtime than is possible with traditional compilers, operating system scheduling, hardware scheduling and organization of execution resources.
Whether they can establish a viable foothold in todays competitive landscape is another issue.
Sufiyan - Saturday, February 13, 2016 - link
If anything this shows that Amdahls law is still true.Bleakwise - Tuesday, March 14, 2017 - link
They never said it violates Amdahl's law.I fact they said that 2 cores gives a speedup of 53%.
Amdahl's law says it would be a 100% speedup maximum.
Since when is 53% > 100%?
Bleakwise - Tuesday, March 14, 2017 - link
Of course, it does beg the question...Why don't we just make 24 wide CPU pipelines and allow for 3-way SMT and fatten the cores up with more units instead?