Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
The VISC Instruction Set and Global Front End
Common instruction set architectures (ISAs) such as x86, ARMv8, Power, SPARC and other more esoteric ones rely on system code converting into predefined instructions that each design can handle. VISC comes with its own ISA as well, separate from the others, which VISC cores and virtual cores use. When using native VISC code, the global front end will split the instructions into smaller ‘virtual hardware threadlets’ which are then dispatched to separate virtual cores. These virtual cores can then issue them to the available resources on any of the physical cores and keep track of where the data goes. Multiple virtual cores can push threadlets into the reorder buffer of a single physical core, which can split partial instructions and data from multiple threadlets through the execution ports at the same time. We were told that each ‘virtual core’ keeps track of the position of the relative output.
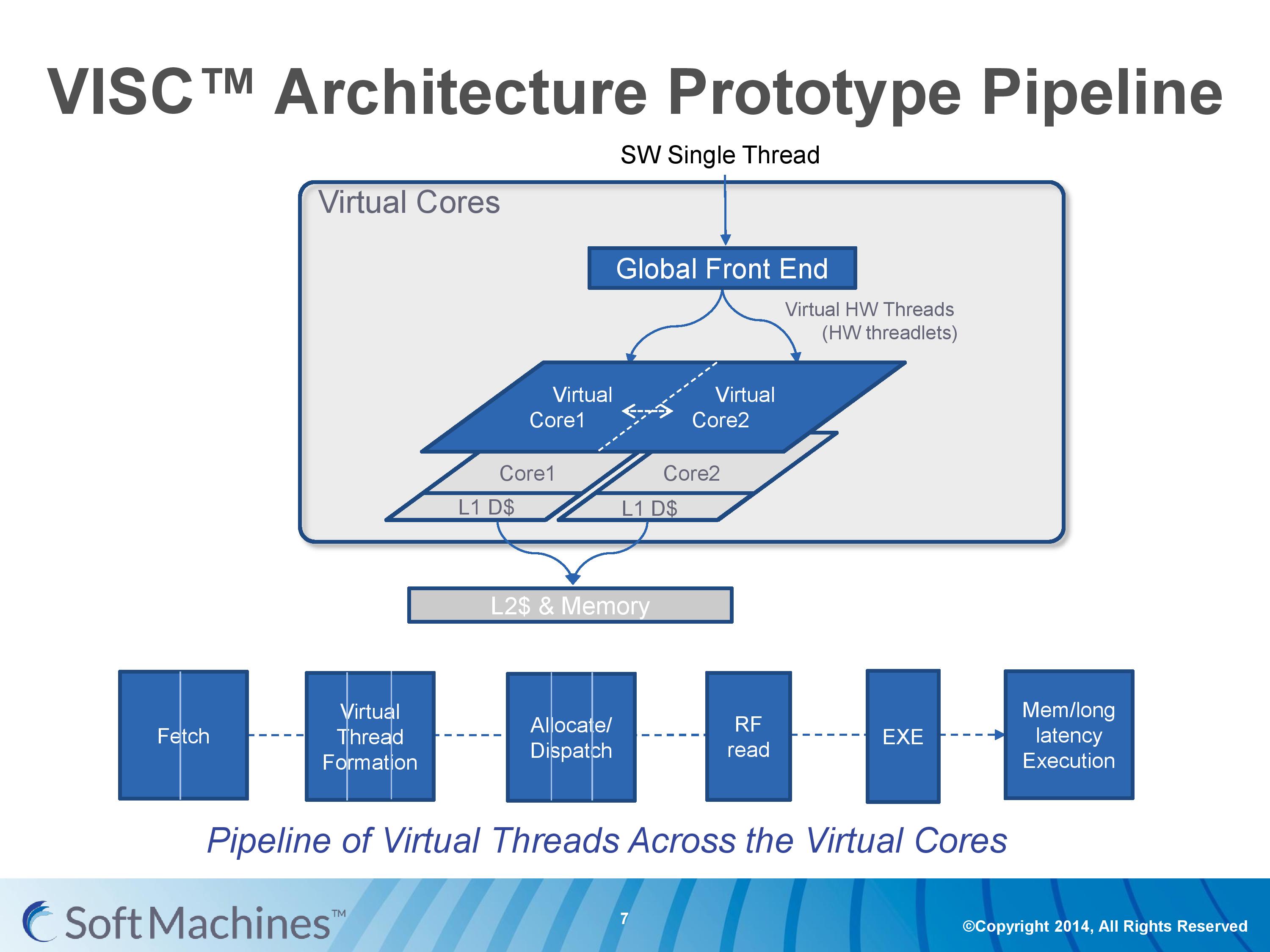
The true kicker (and so much of what sets VISC apart) is that when multiple virtual cores are in flight at one time, the core design allows the virtual core allocation of resources to be dynamic on a near-single cycle latency level (we were told from 1-4 cycles depending on the change in allocation). Thus if two virtual cores are competing for resources, there are appropriate algorithms in place to determine what resources are allocated where.
One big area of focus in optimizing processor designs for single-thread performance is speculation – being able to deal with branches in code and/or prefetch relevant data from memory when needed. Typically when speculation occurs, as the data for a single thread is contained within a core, it is easy enough to deal with code paths that rely on previous data or end up with bad speculation.
In the virtual core scenario however this becomes trickier. VISC tackles this in two ways – firstly, the threadlet generation is designed to minimize cross-core communication because this adds latency and reduces performance. Second, each core can communicate through either the register file or the L1 data caches. The register files have a single cycle latency for data but can only transmit tens of values, whereas the L1 cache has a 4-cycle latency but can transmit thousands of values.
Typically communicating through a register file is seen as a risky maneuver and difficult to control, especially when you have multiple physical cores and each core needs each other core to be able to place/take data into the right registers. Soft Machines told us that a large part of their design work has been in this area of speculation and data transfer. Specifically on speculation and branch prediction, we postulated that they were over ten years behind Intel in this, and the response we got was in a similar vein, stating that using Intel’s branch prediction methods could offer at least 20-30% better performance with branching code. However, we were told that the VISC design is quicker to recover in the event of a failed branch, needing only a few cycles.
The Pipeline
The first VISC core available for license is Shasta, a dual core part that enables up to two virtual cores or threads (2C/2VC), and we were given a base overview of the pipeline.
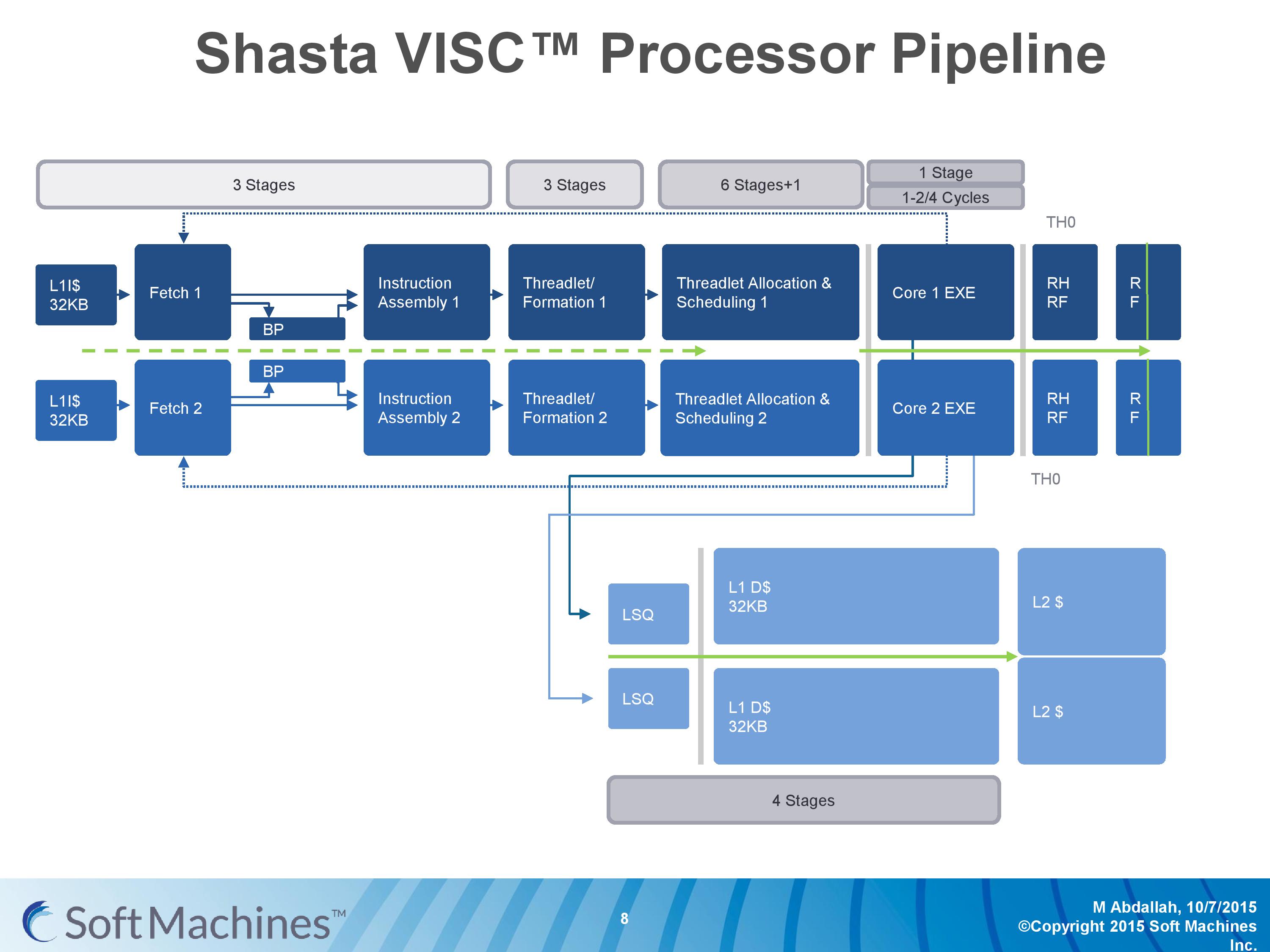
Normally we would see a pipeline of one core but this is a pipeline of both cores of Shasta. This pipeline, compared to the original VISC prototype, is also deeper. The pipeline looks relatively normal to others to start, where the thread either takes an instruction or issues a fetch for data into the instruction assembly. Making the VISC instructions and data into threadlets takes another three stages, but the allocation and scheduling takes six (plus one). On that subject, Soft Machines mentioned that keeping track of data across multiple cores per virtual core is tricky, as well as dealing with reorder buffers and parallel instruction management, that’s why there are a large amount of stages here. The plus one goes back to variable physical core allocation methodology, ensuring that if there are two threads active that the heavier one will get the most resources. The threadlets are then executed on the ports of each core, with a possible 1-4 cycle delay if data needs to be transferred across the core boundaries via registers or L1 cache.
With the variable allocation of fractions of a core to a virtual core, VISC is designed for this situation:
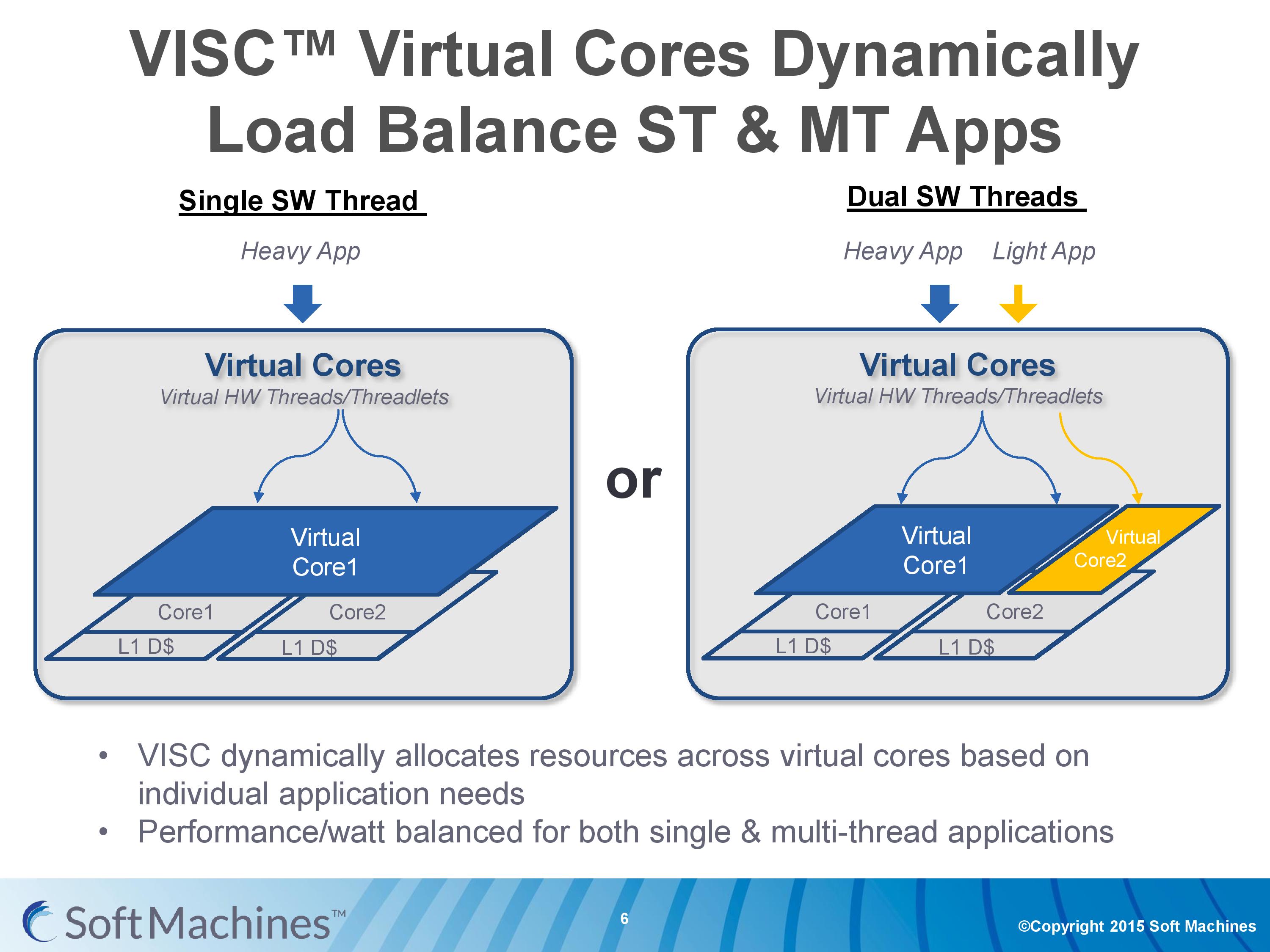
If one heaver thread needs more resources, it can take them from idle ports on a second core (or third, or fourth). The virtual cores can be configured at the software stage as well to limit their use (e.g. keep a VC to half a physical core), and this can be configured at runtime at the expense of 10-12 cycles. There is a quality of service implementation as well, so if a virtual core takes a high priority thread, it will have access to more resources by default.








97 Comments
View All Comments
xdrol - Saturday, February 13, 2016 - link
I somehow fail to see why should be scheduling 2 threads to 2 cores of 4-wide pipelines - including overhead from 'in-thread' cross-core communication - should be more effective than a 2-thread 8-wide SMT core (aka Skylake - it's not 6-wide, and SMT is fine-grained, threads don't 'wait' like the article suggests)Alexvrb - Saturday, February 13, 2016 - link
Right! It's like getting the best of narrow and wide designs at the same time. You can go wide or narrow and more/less threads as needed. It'll probably need a lot of OS support to work well. Still, the concept is interesting, and if their translation layer is fast, it could eventually handle legacy well enough.FunBunny2 - Saturday, February 13, 2016 - link
-- You can go wide or narrow and more/less threads as needed.but no known processor (or design algorithm) can create parallelism in serial code. just because a cpu wants to implement ILP to a greater extent than extant processors, it can't make parallel from nothing; it can only discover "hidden" parallel that extant processors are missing. not something I'd bet on.
Alexvrb - Sunday, February 14, 2016 - link
I was talking about the processor itself. The CPU can act like a wide or narrow design on demand. Whether or not a particular piece of code will benefit was not something I was discussing. My point is that where it helps, it can go wider than current designs. Where it doesn't help it can scale back and go narrow, leaving more cores available for other threads.In other words this doesn't displace multi-threading. A single piece of demanding software may still want to run multiple threads concurrently, to indirectly extract more parallel performance - such as a game splitting up AI, physics, audio, rendering, networking, etc into their own threads. I don't think their design eliminates the necessity of doing this sort of thing.
However they can boost average efficiency with a narrow design and lots of cores (similar to mobile ARM designs), without losing performance vs high-power designs (and in some cases gaining performance) because they can act as a wide pipeline by combining cores It's a flexible form of virtual cores that people will tend to just simplify as "reverse HyperThreading".
This is all just in theory of course, their implementation has to prove itself. Not to mention the difficulties they'll face with ISA translation, at least in the near term. If their technology takes off and gets licensed out, there will be ports of modern OS and APIs, and thus apps will be ported to run native (in the case of Windows, cloud compilation would handle the majority of RunTime apps).
Samus - Monday, February 15, 2016 - link
If the translation layer does what they say it does, that is exactly what this processor can do. It can break up serial code for parallel processing. I don't know how, or how efficient, it can do this. To analyze serial code and say ohh, so there's this complex part in the middle and the rest is simple, and send the complex part to one core and the rest to another, and somehow reassemble it after its processed, seems impossible. We have all seen promising tech flop before, Cyrix and Transmetta had some radical ideas for the way x86 worked, in the end neither could trump Intel or AMD.Alexvrb - Monday, February 15, 2016 - link
What he was saying is that some code can NOT be made parallel. They CAN take single threads and break them up, and when it's possible they can find parallel processing opportunities. But some tasks are inherently serial. Neither the programmer, nor the compiler, nor the VISC processor can make inherently serial tasks parallel. For example, if A has to happen before you can work on B.Uh, at least not with a conventional binary architecture. I don't know much about quantum processors.
easp - Friday, February 12, 2016 - link
I think uninformed pundits/press/commenters will miss the limits imposed by Amdahl's law.Its still plausible to me though that this approach will allow more efficient use of silicon and power by allowing better allocation of processor resources at runtime than is possible with traditional compilers, operating system scheduling, hardware scheduling and organization of execution resources.
Whether they can establish a viable foothold in todays competitive landscape is another issue.
Sufiyan - Saturday, February 13, 2016 - link
If anything this shows that Amdahls law is still true.Bleakwise - Tuesday, March 14, 2017 - link
They never said it violates Amdahl's law.I fact they said that 2 cores gives a speedup of 53%.
Amdahl's law says it would be a 100% speedup maximum.
Since when is 53% > 100%?
Bleakwise - Tuesday, March 14, 2017 - link
Of course, it does beg the question...Why don't we just make 24 wide CPU pipelines and allow for 3-way SMT and fatten the cores up with more units instead?