Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
Dealing with Guest ISAs and a Translation Layer
Going back to this architecture diagram, everything up to the global front end is another interesting story as well.
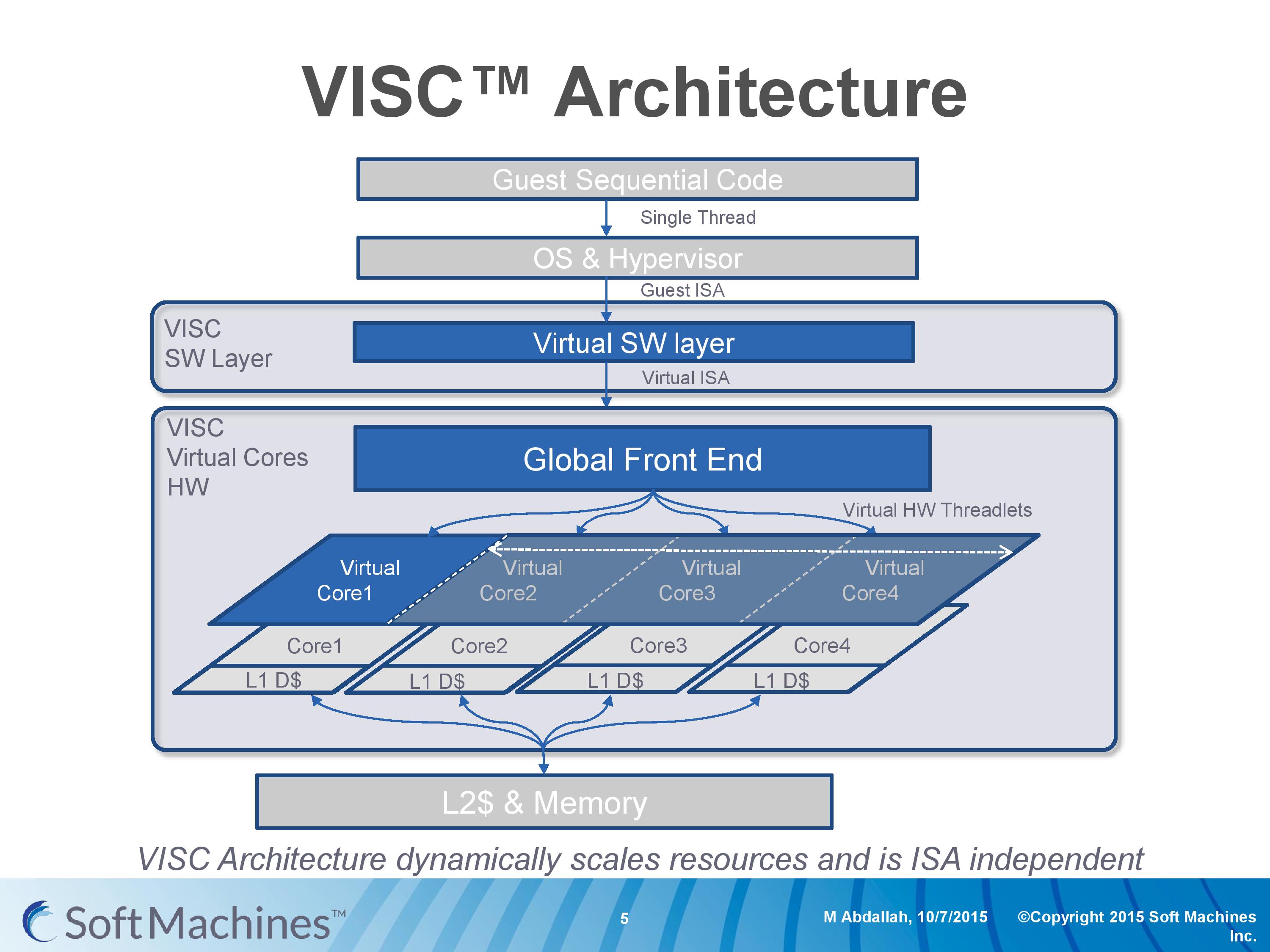
Part of Soft Machines' product package is a low level virtual software layer that will translate a guest instruction set and convert it into the VISC ISA. This is to allow VISC to be used with existing software, and to more easily integrate into current environments rather than trying to establish an ecosystem for a new architecture in 2016. Soft Machines tells us that two instruction sets are supported, one of which will be ARMv8. It was implied that x86 would be the other, although they were reluctant to outright confirm it (ed: x86 translation is likely not to be looked upon fondly by Intel). Meanwhile we were told that writing additional translation layers, while not trivial, can be done and that they plan to support other guest ISAs in future.
So for all intents and purposes, this is a translation layer converting from ARMv8 to VISC. Many companies over the past couple of decades have tried with translation layers – Intel with Itanium, Transmeta to x86, and one of the latest was NVIDIA with Denver, which translated ARM to a custom ISA. Mentioning Itanium, Transmeta and Denver, for those who have followed the industry, might bring a chill down the spine given the very limited success each of these platforms have had. Soft Machines’ CEO was keen to point out that the purpose of the translation layer for VISC is very different to these previous attempts.
The VISC translation layer is designed to be a thin and lean implementation whose main role is to maintain compatibility to the VISC ISA, not to extract performance. Taking Denver as the most recent example, the translation layer there is designed to adjust the ARM instructions into Denver’s ISA and extract instruction level parallelism into the 7-wide design. For VISC, we are told, there is no need to go after performance at this level. The main point at which the VISC design increases performance is at threadlet generation, not in translation and making instruction sequences better fit the VISC hardware. This allows the ARM translation layer to have a less than 5% overhead, according to Soft Machines, and releases a point of contention with previous translation layer designs. As long as the translation layer is 100% compatible, the performance can in principle be extracted at the threadlet level.
This also means, again according to Soft Machines, that any specific compiler enhancement offered by others can also be used when translated. We put it to them that in the case of x86 certain codes are accelerated better on Intel’s compiler than say GCC (a question that arose out of the results we’ll go into later), and we were told that those instruction enhancements by ICC should translate well into the VISC ISA after going through the translation layer.
We asked about the VISC ISA, but were told that more information about this and the core design would be released at a later date as designs progress. We were told that it is a relatively small ISA (as to us sounds like a RISC, which is easier to extract ILP at lower power) with smaller instructions in comparison to ARM and x86. I would assume that this means they are fixed length, but this was not confirmed.








97 Comments
View All Comments
Bleakwise - Tuesday, March 14, 2017 - link
"Floating point code""Integer code"
Do you have any idea what you're talking about?
Bulldozer does "flaoting poitn code" faster than the fucking 1080Ti
At least one one thread. Unless you're going to go wide it doesn't help.
The point of this isn't to "go wide" it's to massively increase speculation ability.
The 1080Ti has ZERO speculative ability, NONE. GPUs simply don't do branching, that's not what GPUs do, they rely on ACE units and SMX units and so on to balance thousands of cores.
A CPU on the other hand has more speculative branches than cores.
SIMD and SIMT that GPUs do are not "FPU code"
FFS
dcbronco - Friday, February 12, 2016 - link
AMD helped finance this. They may already have a stake and I would bet some right to first refusal. They used their investment in HBM to get earlier access than NVIDIA, I doubt they would have invested without some sort of incentives for themselves.Bleakwise - Tuesday, March 14, 2017 - link
Of course not.bcronce - Saturday, February 13, 2016 - link
There is no such thing as a free lunch. They are trading something. Their benchmarks are for single thread performance, which the graphs showed a much greater efficiency and performance than Intel. Very impressive and I'm sure they'll be great for something.The problem is the platform sounds great for highly coupled cores and very wide single thread execution with few data dependencies. Could be great for computation.
What I'm wondering is how their platform scales for IO workloads like web servers, file servers, or event video games. Suddenly a large part of the work is communicating with other devices and synchronizing many cores.
One thing that has helped ARM for a long time is they were mostly single core and only recently multi-core. They didn't use to have a complex cache-coherency like x86. This dramatically reduced transistor counts, increase efficiency, and allowed for great decoupled core performance. But as soon as you wanted two cores to work together, it went to crap. Cache-coherency is hardware accelerated inter-core communication. Amdahl's law was not very forgiving to ARM's non-cache-coherency cores for anything except GPU like workloads.
Based on the description, VISC sounds like it needs highly couples cores to maintain low latency and high bandwidth. This is probably why they also seem to have lower frequency. Keeping many parts far away from each-other in sync takes time. But lower frequency also means lower voltage, and power consumption scales with the square of the voltage and linear with frequency.
I wonder how tightly coupled they can keep 4, 8, or 16 cores. Maybe they don't need the core counts for their target workloads or possibly they can stay competitive with a fraction the core counts by having better efficiency in power and IPC.
In the end, I'm sure they'll at least find a niche market and I'm glad some new ideas are making it out there. I wouldn't be surprised if they can take over the dual or quad core market, forcing Intel to add more cores.
Bleakwise - Tuesday, March 14, 2017 - link
It's not a "free lunch"Obviously all of this crap is going to cost DIE space, it's not free.
If all we cared about was raw processing power we'd just make 2046kb wide vector units and ignore branching and speculation all together.
Bulldozer has better theortical performance than Haswell i5s. I'd rather have the extra out of order pipes, the SMT unit to use any unused pipes, better branch prediction and so, and in the real world this stuff wins the day.
Not everyone can become a world class programmer and re-factor all their code so that it spreads across thousands of cores like it can on a GPU.
Sometimes it's not even possible. Sometimes what you need is branch prediction, branch prediction lets you see the future, LITERALLY this is what the CPU does. Obviously the more branches you predict, the more cycles you're wasting on that thread, because the more speculations you get wrong.
You also reduce the number of misses and increase cache hits.
As for coupling 4 or 16 cores, they haven't even talked about going beyond 4 cores. Obvoiusly it doesn't scale into infinity, if you're getting 90% speculative accuracy you can only gain 10% more. Spending 30% of your transitor budget to bind up 8 or 16 cores when spending 10% of your budget on 4, for a 10% performance gain would be dumb.
You'd be much better off going for more clock speed, or reducing latency, adding a victim cache, or l2 cache coherency, or beefing up the GPU, a better memory controller, or just beefing up your underlying branch predictor,
Bleakwise - Tuesday, March 14, 2017 - link
You'll never get perfect speculation anyway. Unless a language is developed that puts limits on the number of branches possible per X lines of code and keep the number of branches below the number the CPU can handle. You're going to ALWAYS have to deal with the risk of cache misses.Not sure there is even anything you could gain from 100% target prediction hit grantee beyond having no lost cycles on a miss. Getting there even through a core-binding fabric/bus like this across 16 cores would blow your transistor budget to the point that you could hardly afford a reasonable size cache in the first place.
You'd be better off just reducing the number of stages in the pipelines or just adding more pipelines to each core instead of blowing your budget on this fabric.
For example, binding together 100 in order CPUs to make a virtual 100 pipeline CPU would be ridiculously expensive and power hungry vs just having an 8 core superscaler CPU with 12 out of order pipelines in each CPU.
tipoo - Friday, February 12, 2016 - link
Question, since this is testing their core design in isolation and the rests of the package hasn't been built around it, is that accommodated for in the comparisons to other SoCs, which all have far more die area dedicated to non-core stuff than the cores?Flunk - Friday, February 12, 2016 - link
If VISC is not an Acronym then don't capitalize it, idiots.The technology looks like it could be really good, I'm hoping we see some practical applications.
smilingcrow - Friday, February 12, 2016 - link
They can capitalize it for any reason they like; it's just a word so nothing to GYKIATO (Get your kickers .... over).andychow - Friday, February 12, 2016 - link
It's an acronym, you can't trademark acronyms, so now they claim it's not an acronym. Legal bs 101.